







Redis主从复制的核心原理
通过执行slaveof命令或设置slaveof选项,让一个服务器去复制另一个服务器的数据。主数据库可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数据库。而从数据库一般是只读的,并接受主数据库同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。
全量复制
-
主节点通过
bgsave命令fork子进程进行RDB持久化,该过程是非常消耗CPU、内存(页表复制)、硬盘IO的。 -
主节点通过网络将
RDB文件发送给从节点,对主从节点的带宽都会带来很大的消耗 -
从节点清空老数据、载入新
RDB文件的过程是阻塞的,无法响应客户端的命令;如果从节点执行bgrewriteaof,也会带来额外的消耗
增量复制/部分复制
-
复制偏移量:执行复制的双方,主从节点,分别会维护一个复制偏移量
offset -
复制积压缓冲区:主节点内部维护了一个固定长度的、先进先出(
FIFO)队列作为复制积压缓冲区,当主从节点
offset的差距过大超过缓冲区长度时,将无法执行部分复制,只能执行全量复制。 -
服务器运行ID(
runid):每个Redis节点,都有其运行ID,运行ID由节点在启动时自动生成,主节点会将自己的
运行ID发送给从节点,从节点会将主节点的运行ID存起来。从节点Redis断开重连的时候,就是根据运行ID来
判断同步的进度:- 如果从节点保存的
runid与主节点现在的runid相同,说明主从节点之前同步过,主节点会继续尝试使用部
分复制(到底能不能部分复制还要看offset和复制积压缓冲区的情况); - 如果从节点保存的
runid与主节点现在的runid不同,说明从节点在断线前同步的Redis节点并不是当前的主节点,只能进行全量复制。
- 如果从节点保存的
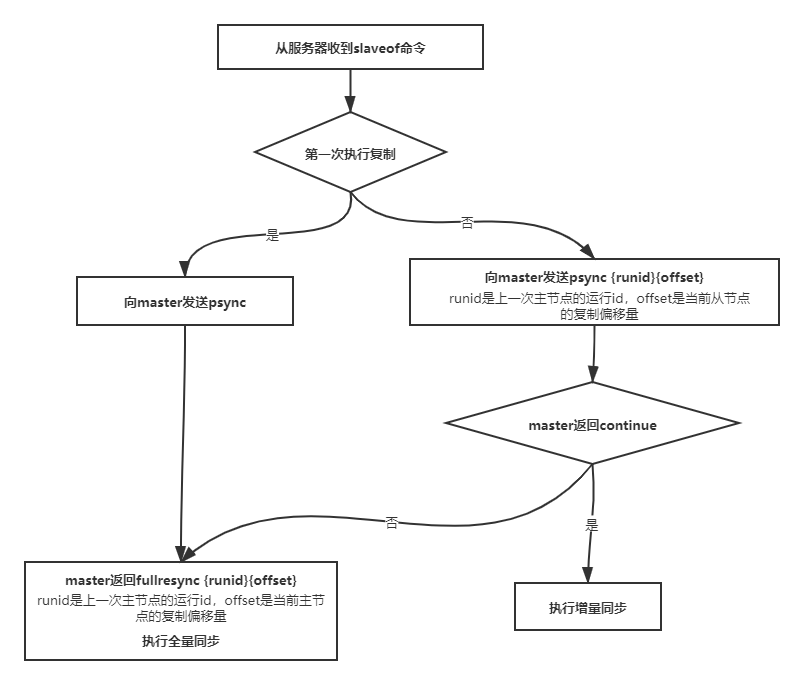
过程原理:















 6063
6063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









