






1.量化器的种类——均匀/
https://arxiv.org/pdf/1806.08342
1.1 Uniform Affine Quantizer
这是一种最朴素的量化:

s表示step,可以看作量化的最小单位;z是zero point,因为当浮点x=0时,对应的量化结果就是z。
可以看到,量化产生了两种误差,截断误差(clipping error)和舍入误差(rounding error),分别由截断和四舍五入运算引入。当浮点x=0时,量化没有产生误差,所以zero padding是没有量化误差的。
对于伪量化后的卷积,两个偏置z会以乘积的形式作为一个加项:
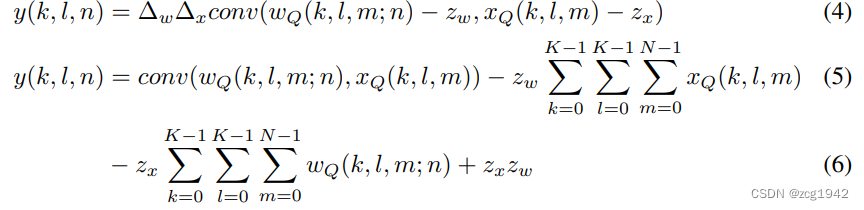
1.2 Uniform symmetric quantize
当Uniform Affine Quantizer中的偏置为0时,就是Uniform symmetric quantize。量化结果可以是带正负符号的,也可以是无符号的:
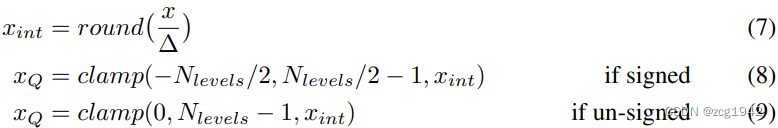
1.3 Stochastic quantizer
随机量化,在以步长归一化之前,对浮点叠加了一个随机值。
没看明白,说是有时会退化为浮点本身,对计算梯度有优势,但推理时大部分硬件不支持。
2.量化的对象——权重/激活层
2.1 Weight only
当只量化weights时,只需要一行命令就可以完全,不需要validation data。一般当不关心运行误差,只是为了便于传输模型和存储时只量化权重。
2.2 weights and activations
很多人不理解激活层怎么量化。虽然激活层没有可训练的参数,但它作为一个函数,其实是有参数的。就算是有参数,为什么要量化激活层呢?只量化weights有什么问题呢?
我想有两个可能的问题。一个问题是激活函数之后可能新产生浮点数据,而浮点运算是硬件不支持的;一个问题是原有的激活函数是为分布在0~1的数据设计的,以sigmoid为例,浮点的时候要无限接近于1它才等于1,但量化数据很容易就大于1了,但从整个分布看这个值其实还处于比较低的水平。


relu这样的函数过于简单,只是一个求最大值的过程,但如leaky relu和sigmoid这样的,函数本身就包含浮点数。那我们做的就是把激活函数中的浮点数定点化吗?
对leaky relu来说,只需要把浮点数定点化就可以了,但对于sigmoid来说,只定点化函数中的e,其实还是存在上述提到的第二个问题。所以,对于激活层的量化,我们更关注的是数据的分布。
所以需要calibration data 计算激活层的动态范围,对映射后的数据一一量化。对每个值量化不太现实,所以做法一般是先量化一些特定的点,其余点通过泰勒展开得到。对于定点数的除法,还需要用到newton-raphson算法。
量化激活层带来的误差是很小的,这意味着量化误差基本上全部来自于对权重的量化。
当网络结构中有ReLU6或者Batch normalization with no scaling时,前者的feature map范围被限制在0~6中,后者的feature maps激活层有0均值和同一方差的特性。这两种特性都有助于激活层的动态范围很小,有利于缩小激活层的量化误差。
3.量化的粒度——layer/channel
一个tensor有多种划分方法,如何把这个tensor划分,就是粒度Granularity of quantization。
以一个四维tensor为例,它由多个3维kernel构成。每个kernel是有意义的,它和feature map一一对应。一个合理的想法是对每个kernel涉及一个量化器,即不同kernel对应的量化器的s和z是不同的,这就是per-channel quantization。而如果不对tensor划分,对整个tensor进行量化,那就是per-layer quantization。
对于activations的量化不使用per channel,因为会使得内积的计算更加复杂。所以对权重使用per channel,对激活层使用per layer。
We do not consider per-channel quantization for activations as this would complicate the inner product computations at the core of conv and matmul operations.
We recommend that per-channel quantization of weights and per-layer quantization of activations be the preferred quantization scheme for hardware acceleration and kernel optimization.
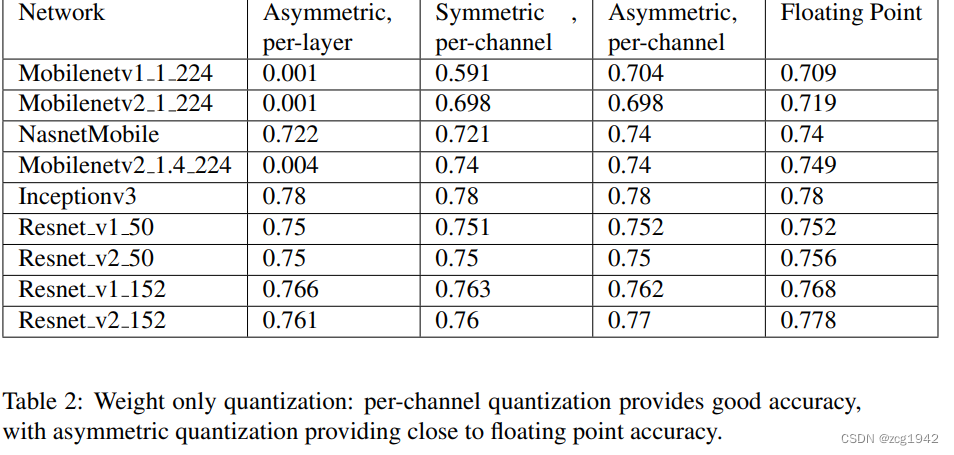
从上表中可以看到,对只量化weights的情况,per channel的精度更好。尤其是MobileNet,使用per layer量化将带来巨大的误差。可能的原因是ResNet这样的网络参数量更大,而参数量越大,对量化误差的鲁棒性也越好。
4.量化的种类——是否训练
pytorch把量化分为三种:Introduction to Quantization on PyTorch | PyTorch,第一种Dynamic Quantization其实针对的是量化的对象。从量化与训练的相对顺序来说,其实可以分为两种:
4.1Post-Training Quantization
Post Training Quantization (PTQ) — Torch-TensorRT v1.4.0+7d1d80773 documentation
https://www.tensorflow.org/lite/performance/post_training_quantization
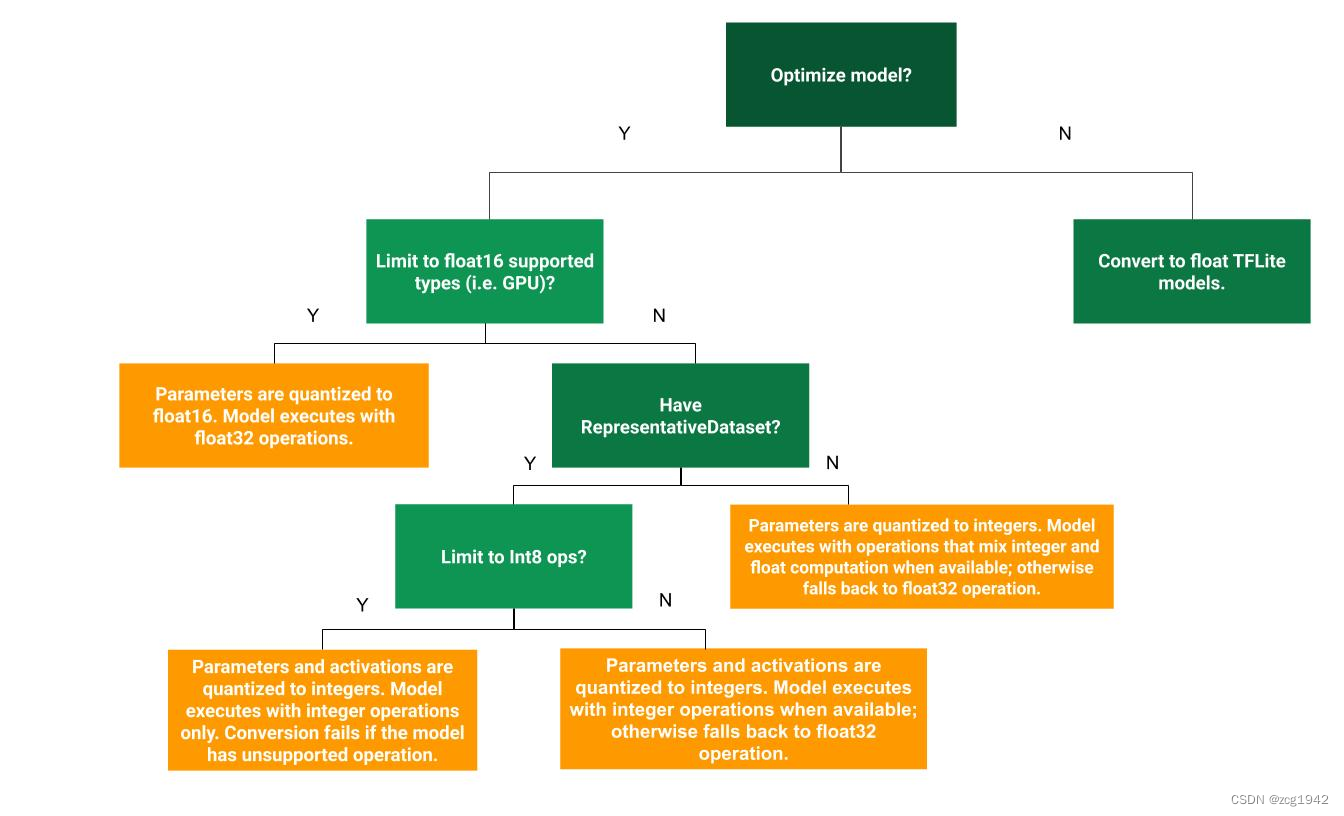
顾名思义,就是在已经训练得到浮点模型之后,使用一些工具把它转换为量化后的模型。TensorRT需要calibration step,作用是使得INT8和FP32的推理结果尽可能差异最小。把权重和激活层都量化到INT8是最高级别的量化,在FP32和INT8之间,还可以有一些中间形态:
4.2 Quantization Aware Training
https://www.tensorflow.org/model_optimization/guide/quantization/training
之前的PTQ量化都只关心forward,而QAT还关心backward。
在这里weights和activations 都被假量化,模拟clamping and rounding带来的量化损失,但是所有的计算仍然使用浮点。虽然使用浮点计算,但此时的梯度是基于量化数据计算得到的,所以仍然是有意义的。这样让网络在训练阶段就意识到有量化这个操作,从而达到更高的精度。

即便使用4bit量化,QAT的准确性都要好于PTQ。
QAT可以是从头开始训练from scratch,也可以是基于原来的浮点模型fine tune,关键是训练中包含fake quantization operations。
此时训练得到的模型仍然是一个浮点模型,只不过因为考虑到了量化损失,这个浮点模型对量化是更友好的。所以还是需要一个Convert model的过程,把weights变为int类型,同时还要记录激活层的量化信息。在tf中通过tensorflow converter (TOCO)把Convert model的结果存放在flatbuffer中。
5. 高通论文
高通作为移动端的王者,对量化有着深刻的认识。综述性的可以看高通的白皮书,这里简单看一篇更加具体的文章:Data-Free Quantization Through Weight Equalization and Bias Correction,原文链接。
正如前面提到的,MobileNetV2的后量化会面临70.9% to 0.1%的准确度下降,但这篇文章不需要per channel量化,也不需要训练就可以得到接近原始精度的量化效果。
首先弄清楚为什么下降这么厉害。MobileNetV2有一个结构特点是depthwise-separable,这就造成不同channel的权重分布差异特别大:
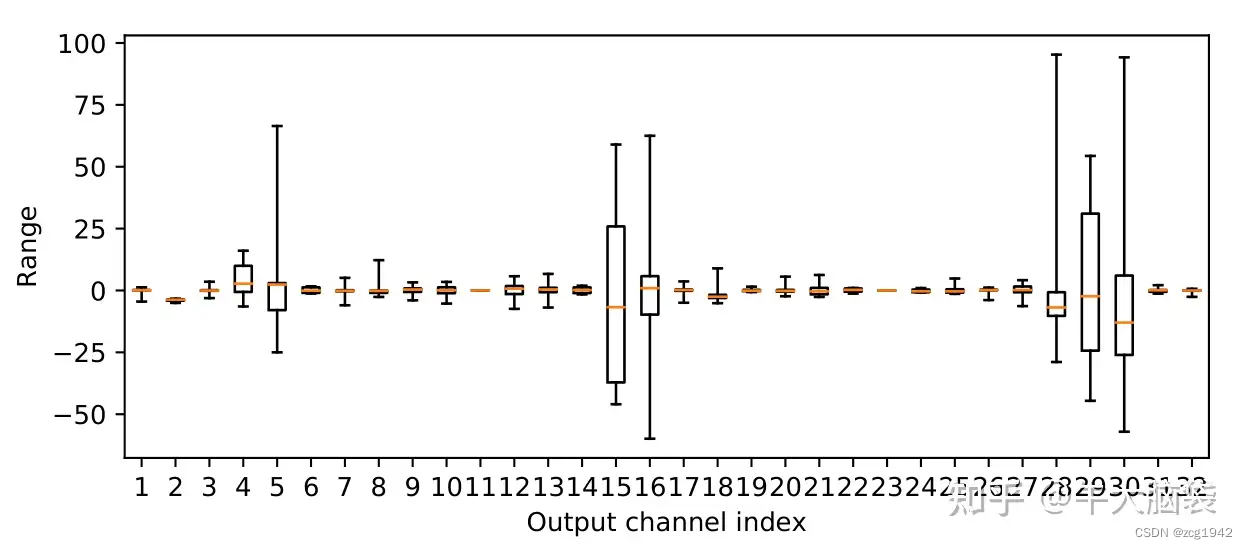
如此大的差异,导致整个tensor一同量化的时候出现顾此失彼的情况。
另外一个原因来自于假设性条件无法满足。量化会产生误差,误差的期望是0就是无偏的,这是我们期望的。但实际上量化误差是有偏的,这就会影响下一层的输入分布。
data-free quantization method (DFQ)从下面三个方面进行解决:
5.1 range equalization
根据线性关系,将相邻两层卷积层重参数化reparameterize:
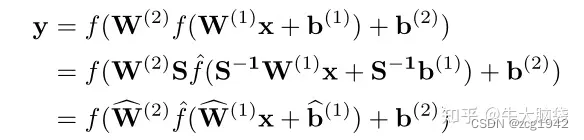
重参数化之后,权重W根据选定的S发生了变化,所以原则上调整S就可以使得W的分布更加相似,便于量化,解决上述提到的不同kernel波动大的问题。
5.2 Absorbing high biases
s小的话偏置b就要大,这样就导致进入激活层时范围过于大。这里仍然是利用relu的特点:
![]()
进一步重参数化,把偏置大传递到下一层。
5.3 Quantization bias correction
就像基于算数平均值估计方差时一样,如果是有偏估计,可以把这个偏差减去。可以看到,偏移同时和x的期望和量化误差有关:
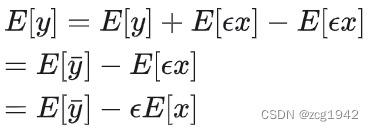
文章假设了BN-->relu这样的顺序结构,因此BN层得到的高斯分布,只有正半轴的部分保留了下来,此时不能直接使用BN的均值作为 E[x] 。文中提供了两种方法来计算relu后的 E[x]。分别是有calibration和没有calibration时。















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









