







实验目的
1、熟悉MapReduce的程序结构
2、通过实例重点了解map和reduce的工作过程
3、了解MapReduce程序的打包;在集群的部署运行过程
实验环境
1、Linux操作系统(Windows环境类似)
2、安装64位jdk8
3、hadoop它分布式环境
实验内容
要求统计某个文件中(文件名file)每个单词出现的次数,样本数据格式及其信息如下(中间使用制表符“\t”):
hello you
hello me
hello everone
实验原理
MapReduce由两个阶段组成:Map和Reduce,用户只需要重map()和reduce()两个方法即可实现分布式计算程序。
Map()函数是以key/value键值对作为输入,产生另外一系列的key/value键值对作为中间结果输出到本地磁盘。MapReduce框架底层一些算法会自动将这些中间数据按照Key值进行聚集,默认采用的是哈希算法将key值相同的数据统一交给reduce()函数处理。
reduce()函数以key及对应的value列表作为输入,经合并key相同的value值后产生另外一系列key/value对作为最终输出写入HDFS。
一个完整的mapreduce程序有三类实例进程:
MRAppMaster:负责整个程序的协调过程
MapTask:负责map阶段的数据处理
ReduceTask:负责reduce阶段的数据处理
【1】Map阶段由一定数量的Map Task组成
格式解析:InputFormat(把输入文件分片)
数据处理:继承Mapper类
【2】Reduce阶段由一定数量的Reduce Task组成
从Map Task的输出拷贝数据, 按照key排序和分组(key相同的都放在一起,按照key进行分组操作,每一组交由Reducer进行处理),它继承Reducer类,可以通过OutputFormat类设置。
实验步骤
一、开发的环境准备
1、建立Java项目
步骤一 双击桌面Eclipse图标:

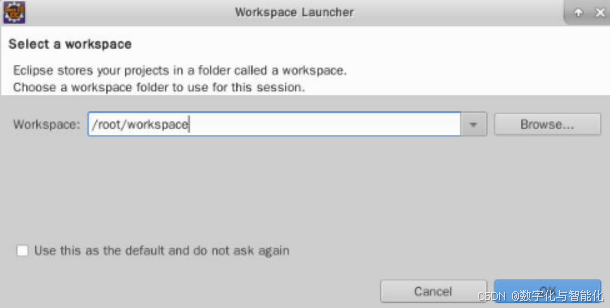
步骤二 选择默认工作区/root/workspace:
步骤三 点击《OK》按钮后打开Eclipse:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6323
6323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











