







1、Word2Vec的损失函数
Word2Vec模型(包括CBOW和Skip-gram)主要使用两种形式的损失函数:负对数似然损失(Negative Log Likelihood, NLL)和负采样损失(Negative Sampling Loss)。下面我将详细介绍这两种损失函数的数学形式和含义。
(1) 原始Softmax损失函数(负对数似然)
对于单个训练样本,原始softmax损失函数为:
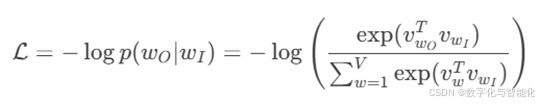
其中:
wI 是输入词(CBOW中是上下文词的平均,Skip-gram中是中心词)
wO 是目标输出词(CBOW中是中心词,Skip-gram中是上下文词)
vw 是词w的向量表示
V 是词汇表大小
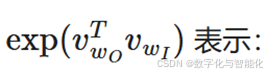
计算目标词与输入词的相似度(点积)的指数
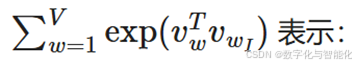
计算所有词汇与输入词相似度的指数和
整体:计算目标词在所有词汇中的概率,并取其负对数
特点:
【1】计算复杂度高:每次需要计算整个词汇表的softmax
【2】适合小词汇表场景
【3】在标准Word2Vec实现中很少直接使用,因为当词汇表很大时计算量过大
(2) 负采样损失函数(Negative Sampling)
负采样损失是对原始softmax的近似,公式为:
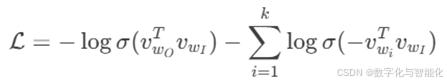
其中:
【1】![]()
是sigmoid函数
【2】wO 是正样本(真实上下文词)
【3】wi 是从噪声分布Pn(w)中采样的负样本(k个)
【4】k是负采样数量(通常5-20)
第一部分:
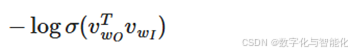
最大化正样本的概率
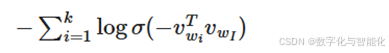
第二部分:
最小化负样本的概率
整体:相当于二元逻辑回归,区分真实上下文词和噪声词
特点:
【1】计算效率高:不需要计算整个词汇表,只需计算k+1个样本
【2】实际效果与原始softmax相当甚至更好
【3】是Word2Vec默认采用的损失函数
(3) 层次Softmax(Hierarchical Softmax)
另一种替代方案是层次Softmax,使用二叉树结构减少计算复杂度:
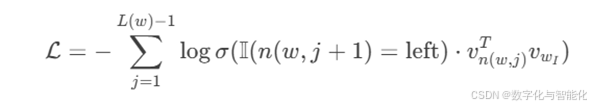

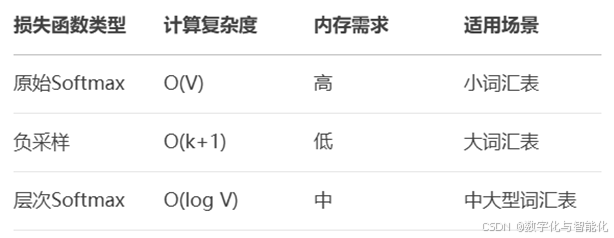
不同损失函数的比较:
PyTorch实现示例(负采样损失):
import torch
import torch.nn as nn
import torch.nn.functional as F
class NegativeSamplingLoss(nn.Module):
def __init__(self):
super(NegativeSamplingLoss, self).__init__()
def forward(self, input_vectors, output_vectors, noise_vectors):
# 正样本损失
batch_size, embed_size = input_vectors.shape
input_vectors = input_vectors.view(batch_size, embed_size, 1)
output_vectors = output_vectors.view(batch_size, 1, embed_size)
# 正样本得分 (batch_size,)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











