







Solr的中文分词器
- 中文分词在solr里面是没有默认开启的,需要我们自己配置一个中文分词器。
- 目前可用的分词器有smartcn,IK,Jeasy,庖丁。其实主要是两种,一种是基于中科院ICTCLAS的隐式马尔科夫HMM算法的中文分词器,如smartcn,ictclas4j,优点是分词准确度高,缺点是不能使用用户自定义词库;另一种是基于最大匹配的分词器,如IK ,Jeasy,庖丁,优点是可以自定义词库,增加新词,缺点是分出来的垃圾词较多。各有优缺点。
- 面给出两种分词器的安装方法,任选其一即可,推荐第一种,因为smartcn就在solr发行包的contrib/analysis-extras/lucene-libs/下,就是lucene-analyzers-smartcn-4.2.0.jar,首选在solrconfig.xml中加一句引用analysis-extras的配置,这样我们自己加入的分词器才会引到的solr中。
smartcn 分词器的安装
1.首选将发行包的contrib/analysis-extras/lucene-libs/ lucene-analyzers-smartcn-4.2.0.jar复制到\solr\contrib\analysis-extras\lib下,在solr_home文件夹下
2.打开/ims_advertiesr_core/conf/scheme.xml,编辑text字段类型如下,添加以下代码到scheme.xml中的相应位置,就是找到fieldType定义的那一段,在下面多添加这一段就好啦
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
</analyzer>
</fieldType>如果需要检索某个字段,还需要在scheme.xml下面的field中,添加指定的字段,用text_ smartcn作为type的名字,来完成中文分词。如 text要实现中文检索的话,就要做如下的配置:
<field name ="text" type ="text_smartcn" indexed ="true" stored ="false" multiValued ="true"/>IK 分词器的安装
IKAnalyzer2012FF_u1.jar //分词器jar包
IKAnalyzer.cfg.xml //分词器配置文件
stopword.dic //分词器停词字典,可自定义添加内容- 将IKAnalyzer2012FF_u1.jar 加入C:\apache-tomcat-7.0.57\webapps\solr\WEB-INF\lib中。
- 在C:\apache-tomcat-7.0.57\webapps\solr\WEB-INF下新建classes文件夹,将IKAnalyzer.cfg.xml、keyword.dic、stopword.dic加入classes里。
- 然后就可以像smartcn一样进行配置scheme.xml了
<!-- 配置IK分词器start -->
<fieldType name="text_ik" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" isMaxWordLength="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" isMaxWordLength="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>中文分词器mmseg4j
mmseg4j-solr-2.3.0支持solr5.3
1.将两个jar包考入tomcat中solr项目里的lib文件内
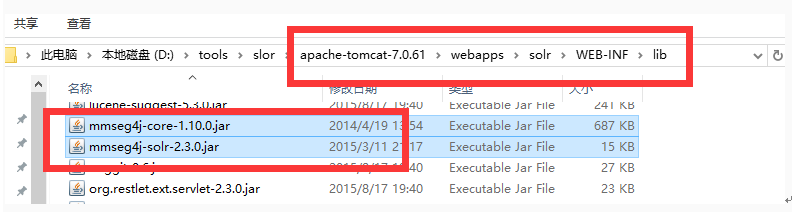
2.配置solr_home中的schema.xml
在下面标签
<fieldType name="currency" class="solr.CurrencyField" precisionStep="8" defaultCurrency="USD" currencyConfig="currency.xml" /></fieldType>
里新增:
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic"/>
</analyzer>
</fieldtype>
<fieldtype name="textMaxWord" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" />
</analyzer>
</fieldtype>
<fieldtype name="textSimple" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="n:/custom/path/to/my_dic" />
</analyzer>
</fieldtype>重启tomcat测试分词
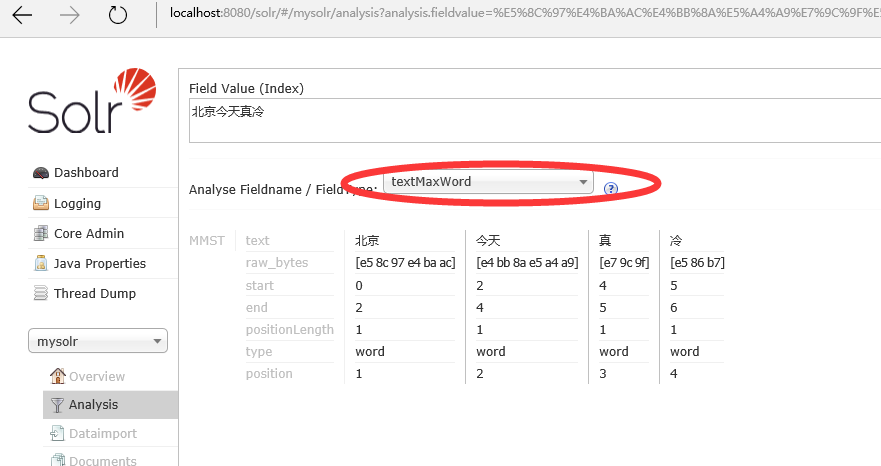
在schema.xml里定义:
<field name="content_test" type="textMaxWord" indexed="true" stored="true" multiValued="true"/>然后测试:















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









