






 文章讨论了在外呼系统中,如何通过聚合和排序功能避免多次联系同一客户的问题。提出的方法包括减少对最新跟进时间的依赖,尝试冗余国家客户代码到机会表,以及考虑使用ES进行数据存储。但最终发现,即使优化了部分查询,性能提升有限,可能需要考虑更换技术栈以提高效率。
文章讨论了在外呼系统中,如何通过聚合和排序功能避免多次联系同一客户的问题。提出的方法包括减少对最新跟进时间的依赖,尝试冗余国家客户代码到机会表,以及考虑使用ES进行数据存储。但最终发现,即使优化了部分查询,性能提升有限,可能需要考虑更换技术栈以提高效率。
背景
PS做外呼时,由于线索/试驾会出现多条,会出现多次联系同一个客户的情况,现对线索和试驾等列表根据统一的国家客户维度进行聚合,提高通过客户维度查询和外呼效率
需求内容
点击后展开/收起属于同一国家客户的多条线索
同一国家客户内/不同国家客户间根据前端的传参时间类型(比如更新时间,跟进时间,创建时间)进行排序,即原先是什么顺序,排序完还是什么顺序
问题方案
select any_value(t.number) as number,o.id from opportunity o inner join
(select count(1) as number,substring_index(group_concat(q.id order by last_follow_time,q.id asc),',',1)as minFollowTimeId from opportunity q join store_customer_relation s on q.store_customer_id = s.id group by s.country_customer_code) t
on t.minFollowTimeId = o.id
生产有几十万数据
执行10条需要0.7s,比较耗时。
想到的方案
1、可以根据创建时间或更新时间,而不选最新跟进时间。因为最新跟进时间会为null,null的话就排不了 ----pass,性能太差了
select count(1) as number,q.id from opportunity q join store_customer_relation s on q.store_customer_id = s.id group by s.country_customer_code order by q.create_time
2、也可以跟进时间来排,只是说要再加个id的排序 ----pass,性能太差了
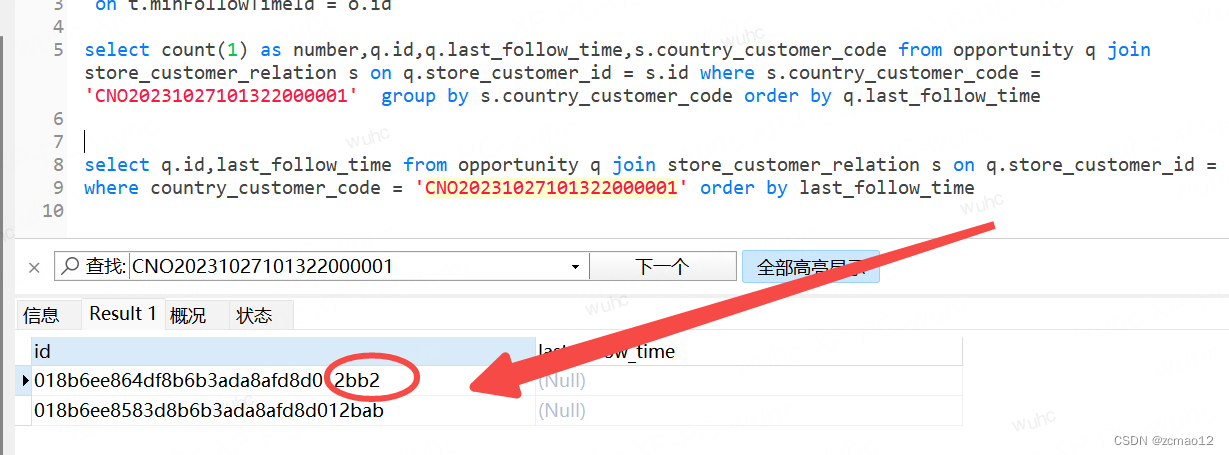 原来这里的列表非聚合前和聚合后的null值的排序不一定相同的,因为group by后的排序是根据分组的数据集来的,排序字段要统一,因为last_follow_time会有null,加个id就好了。
原来这里的列表非聚合前和聚合后的null值的排序不一定相同的,因为group by后的排序是根据分组的数据集来的,排序字段要统一,因为last_follow_time会有null,加个id就好了。
select count(1) as number,q.id,q.last_follow_time,s.country_customer_code from opportunity q join store_customer_relation s on q.store_customer_id = s.id group by s.country_customer_code order by q.last_follow_time,id
可是查询出来的性能更差了,需要1.1s
原因:第一条 SQL 查询在执行过程中会对整个结果集进行分组操作,然后对每个分组进行排序,并且在排序后的结果集中进行聚合计算。这意味着数据库系统需要在内存中维护整个结果集,进行分组、排序和聚合计算,消耗了大量的系统资源和时间。
而第二条 SQL 查询使用了子查询,首先对数据进行一次聚合操作,然后再通过子查询的结果来过滤和获取需要的数据。这种方式可以大大减少内存消耗和排序操作的负担,因此通常具有更好的性能表现。


3、冗余国家客户code到opportunity表这样就可以不用关联表了
性能有提高,但是还是慢。0.5s
4、使用es(发现group by 的字段返回数据量大,就是会慢。除了换技术栈,没有更好的选择。)















 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









