






NDH Impala 集群的 impalad 节点可以被划分成多个独立分组,我们称之为节点组。节点组可以仅有 executor 组成,也可以有 coordinator 节点。

上图 Impala 集群包含 3 个节点组,每个节点组的 impalad 中必须至少有一个 executor 节点。此外还有 2 个 coordinator 节点独立于节点组之外。独立的 coordinator 节点可以将请求路由到任一节点组中的 executor,节点组中的 coordinator 只能将请求分发给本分组内的 executor 节点执行。根据查询路由规则的差异,有两种虚拟数仓实现方式。
2 实现方式
NDH Impala 支持两个虚拟数仓实现,分别是基于 zookeeper 地址的静态配置方案和基于会话(session)参数的动态配置方案,下面分别展开介绍。
2.1 静态配置
该方案将不同节点组的 coordinator 节点注册到不同的 zookeeper 地址上,Hive JDBC 客户端连接不同的 zookeeper 地址即可获取到不同业务组的 coordinator,从而进行连接并下发 SQL 请求。此种方式中每个节点组都会拥有自己独有的一到多个 coordinator 节点,负责将 SQL 生成的执行计划下发给组内的 executor 节点执行。
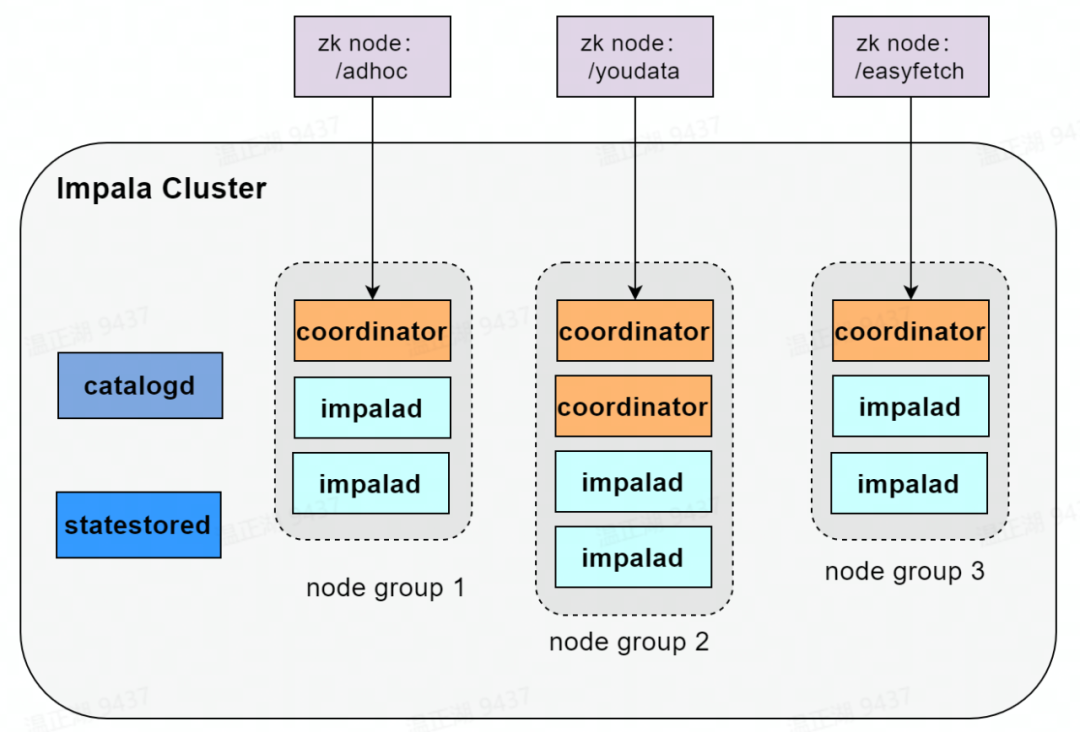
上图所示集群有 3 个虚拟数仓:group 1,group 2 和 group 3。它们共用相同的 statestored 和 catalogd,共用同一份数仓元数据。虚拟数仓间的 impalad 资源是物理隔离的,某个虚拟数仓的 coordinator 节点只会将查询下发到组内的 executor 节点。在生产环境中,可通过配置多个虚拟数仓来接收不同类型业务的查询请求,以便不同业务的查询在计算资源的使用上互相隔离,互不影响,图中 group 1 用于进行 ad-hoc 查询,group 2 用于有数 BI 报表,group 3 用于有数 BI 自助取数。相比多集群方式,多虚拟数仓的方式所需要资源更少,配置更灵活。
2.2 动态路由
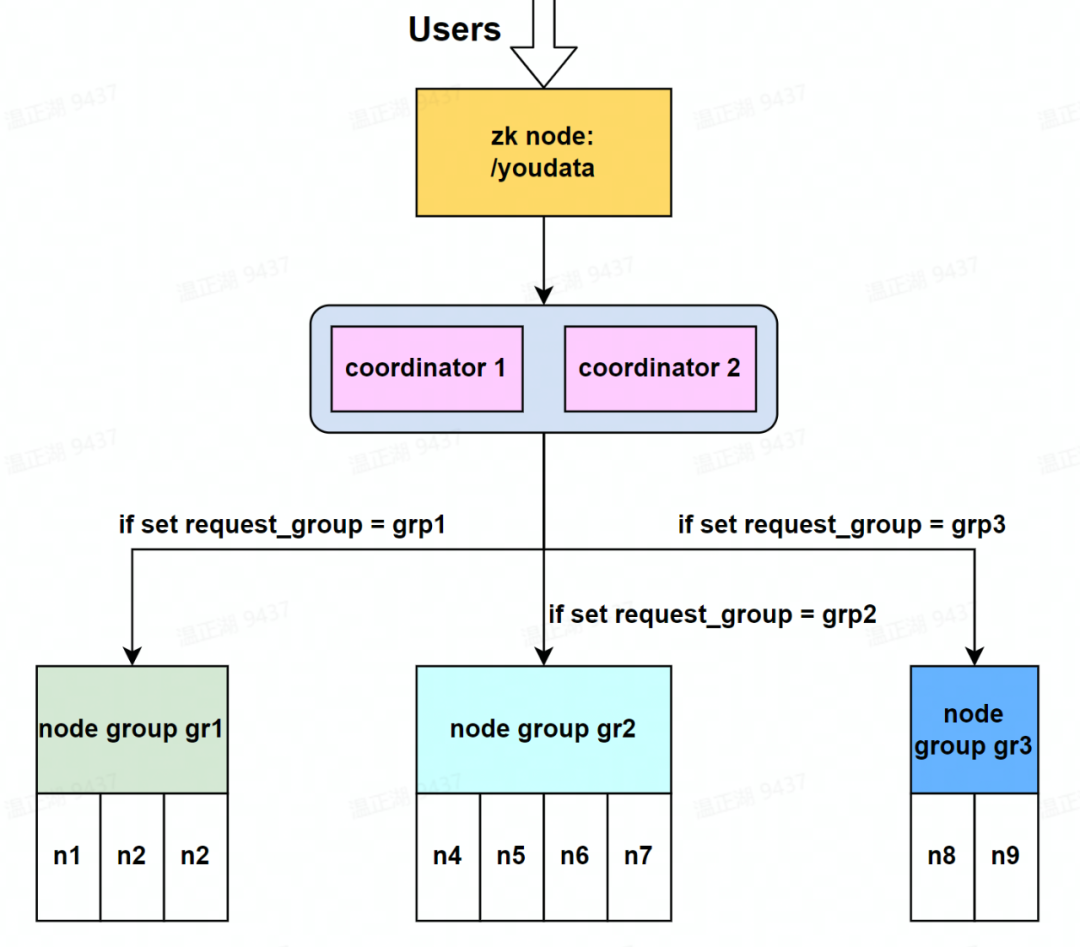
本方案在会话连接中增加一个 query option 参数 request_group,通过 set request_group=xxx 语句,coordinator 会自动将查询路由到指定分组上执行。request_group 默认为 default,对应 group_name 的默认值也为 default。换言之,若不指定 request_group,那么查询会下发到默认的 default 分组执行。
在本方案中 coordinator 节点是公共的,仅对 executor 节点进行分组,在实现上更类似 Snowflake 的虚拟数仓。如下图所示,有 2 个公共的 coordinator,3 个分组,由于不存在 default 分组,可将默认分组配置为 grp1。可以通过参数动态配置,相比基于 zookeeper 的方案更加灵活,用户能够根据需要自由地将查询在不同的虚拟数仓上切换。
上述两种方案均已实现,由于 NDH 的生产环境一般通过 Hive JDBC 连接 zookeeper 来访问 Impala,前者的使用方法兼容性更好,目前线上主要使用以该方式部署虚拟数仓。本小节接下来介绍的虚拟数仓进阶特性也主要围绕前者展开。
3 主要特性
3.1 水平扩展
若虚拟数仓的单个节点组资源和并发数已经达到瓶颈,单纯在组内增加节点无法有效提升查询并发数,此时可以新增一个规格相同或相近的节点组加入该虚拟数仓中,需将新节点组中 coordinator 的 zookeeper 地址配置成与原节点组相同。借助 Hive JDBC 在选择 zookeeper 下 coordinator 地址时的随机性特点,可将查询负载均衡到新旧节点组上。这种方式可以接近线性地提升集群的查询并发数。
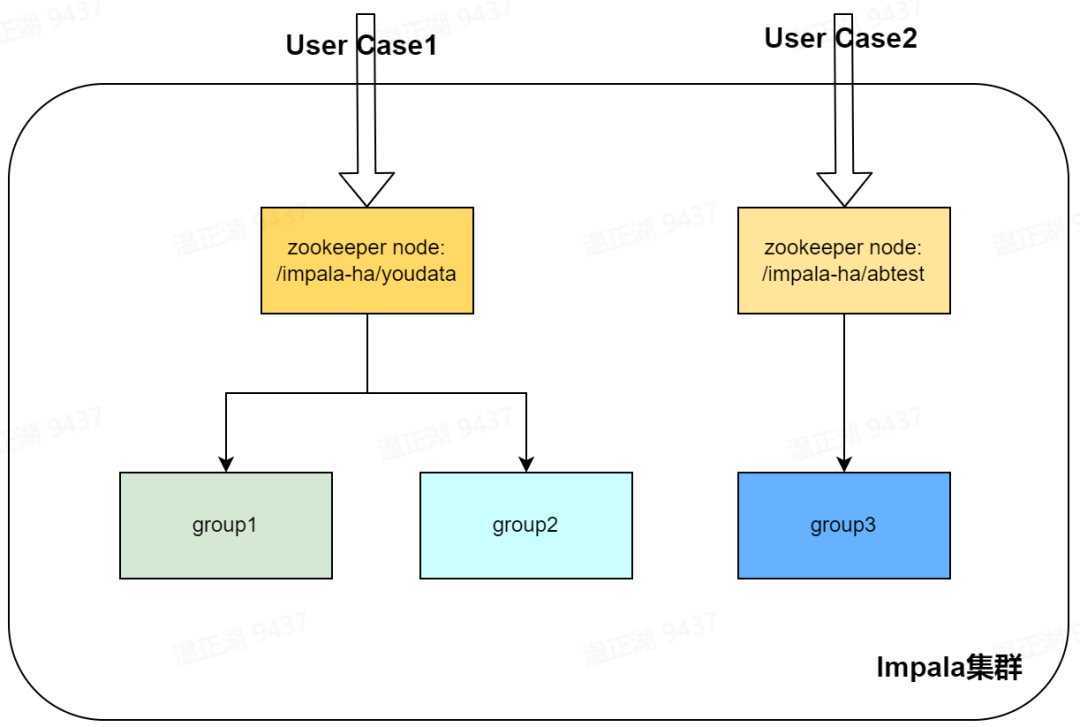
上图所示 Impala 集群有 2 个虚拟数仓,对应的节点组分别为 group1 和 group3,承接的业务分别是业务的有数 BI 报表和 ABTest 场景。假设 group1 为原分组,有 3 个 impalad 节点(1 个 coordinator,2 个 executor)。新增分组 group2,也是 3 个 impalad 节点,使用与 group1 相同的配置,即可起到水平扩展的效果。















 1963
1963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









