






论文:https://arxiv.org/abs/2111.03930
代码:GitHub - gaopengcuhk/Tip-Adapter
根据论文提供的代码基于stanford_cars数据集复现,起初计划使用imagenet数据集进行复现,但imagenet官方下载失败,于是就采用了stanford_cars数据集。下面是具体步骤:
步骤
下载数据集
首先在DATASET.md中找到stanford_cars的下载方法:
我们按照官方提示在根目录下创建各个数据集的子目录,方便各个数据集的切换:
```
$DATA/
|–– imagenet/
|–– caltech-101/
|–– oxford_pets/
|–– stanford_cars/
```其次找到stanford_cars模块下载链接,并按照提示创建好文件夹:
### StanfordCars
- Create a folder named `stanford_cars/` under `$DATA`.
- Download the train images http://ai.stanford.edu/~jkrause/car196/cars_train.tgz.
- Download the test images http://ai.stanford.edu/~jkrause/car196/cars_test.tgz.
- Download the train labels https://ai.stanford.edu/~jkrause/cars/car_devkit.tgz.
- Download the test labels http://ai.stanford.edu/~jkrause/car196/cars_test_annos_withlabels.mat.
- Download `split_zhou_StanfordCars.json` from this [link](https://drive.google.com/file/d/1ObCFbaAgVu0I-k_Au-gIUcefirdAuizT/view?usp=sharing).
The directory structure should look like
```
stanford_cars/
|–– cars_test\
|–– cars_test_annos_withlabels.mat
|–– cars_train\
|–– devkit\
|–– split_zhou_StanfordCars.json
```下载好后在本地路径的保存地址如下:(注:这里一定要先建一个caches根目录!之后再创建数据集的子目录!)
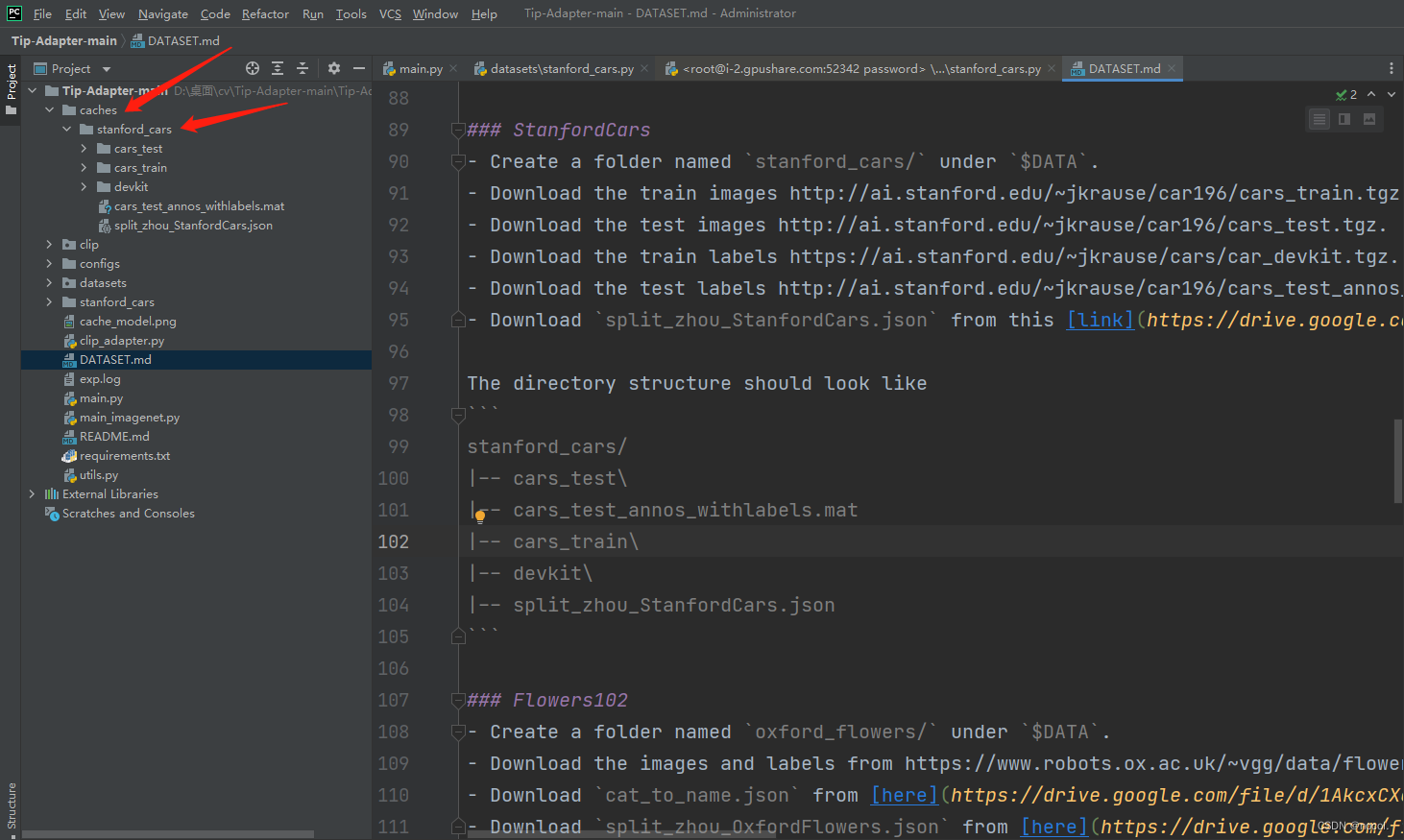
为什么要创建根目录caches。
在main.py中定义:

链接远程服务器
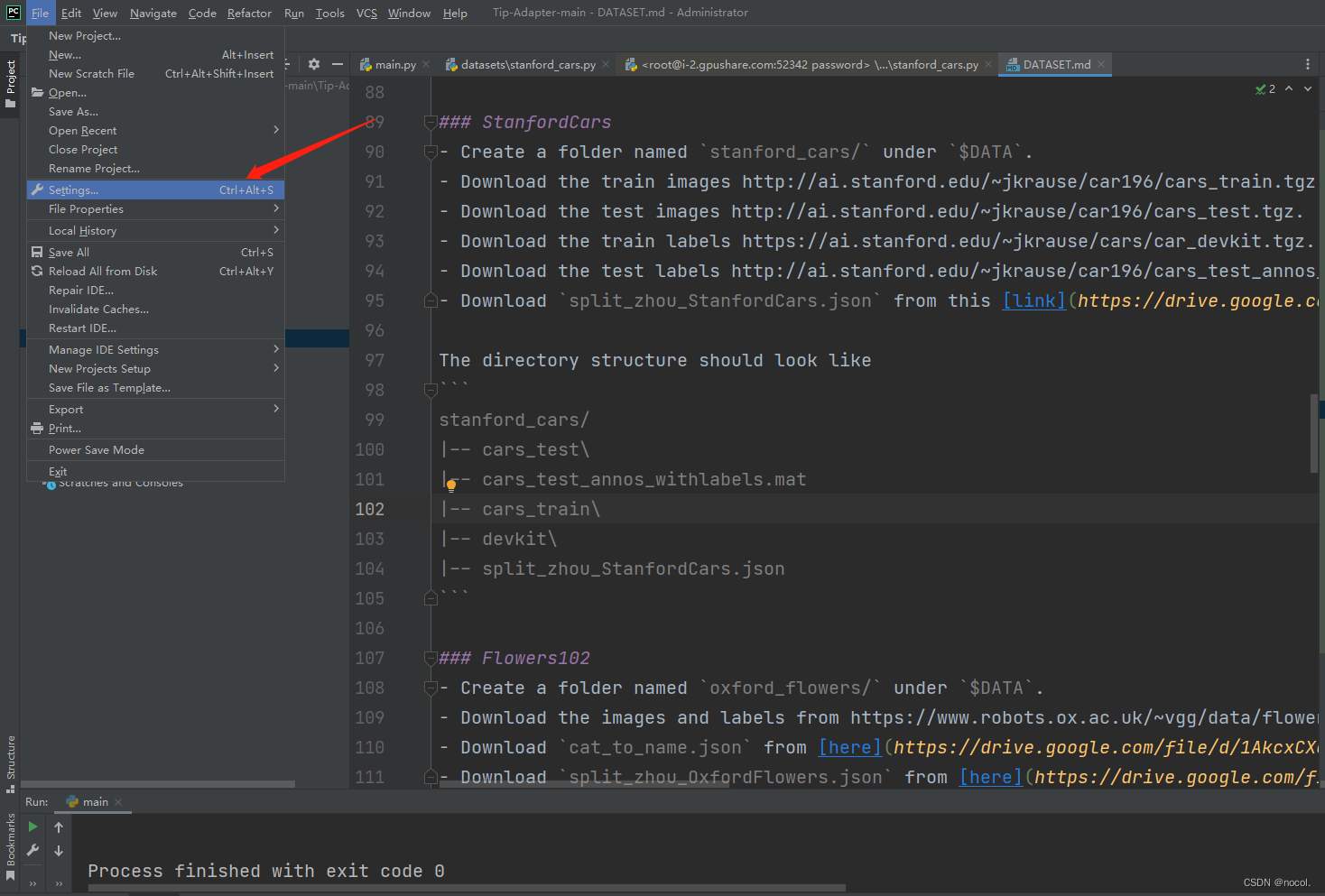
之后点击齿轮选择ADD
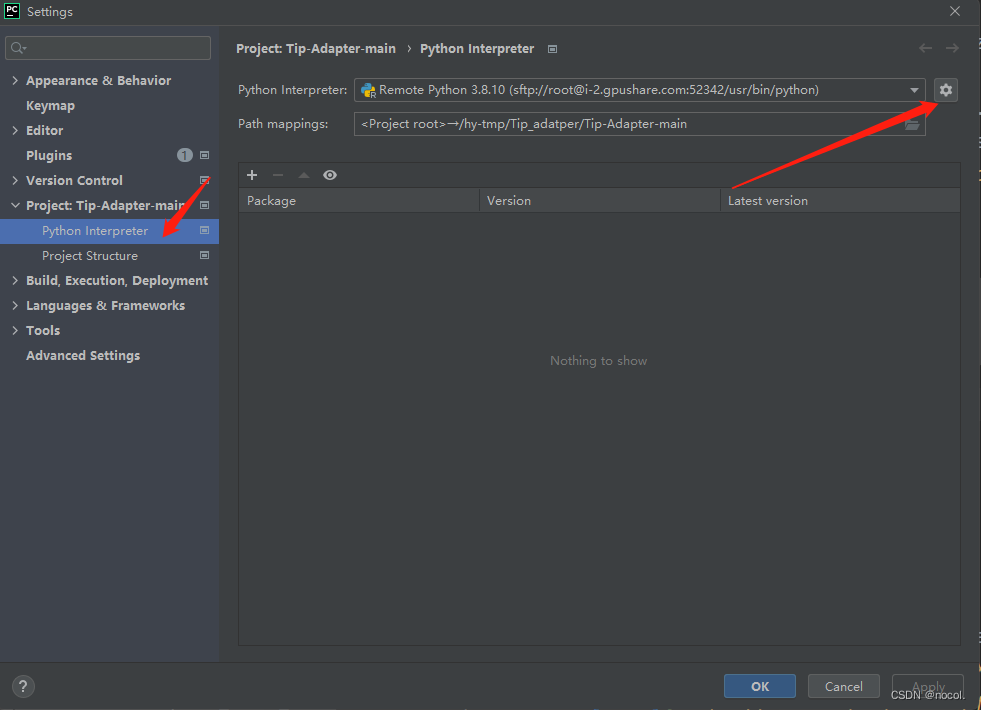
选中SSH,输入租的服务器账号和端口号以及密码,一路next,(这里要记得自己本地和远程服务器的映射地址,方便后期调试代码)
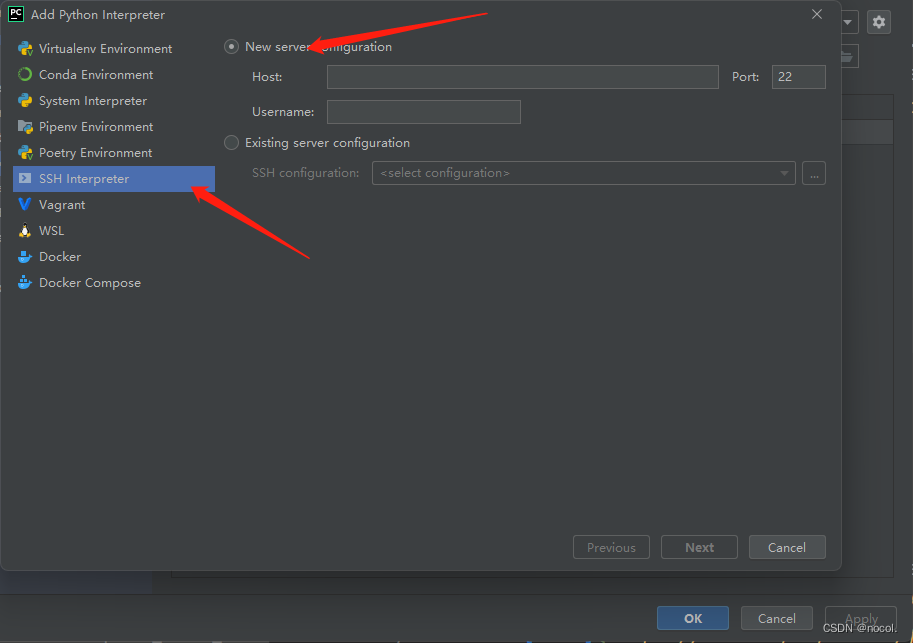
之后配置configurations
Script path是项目本地路径,Parameters是运行文件指定的配置文件。python解析器选择远程服务器。
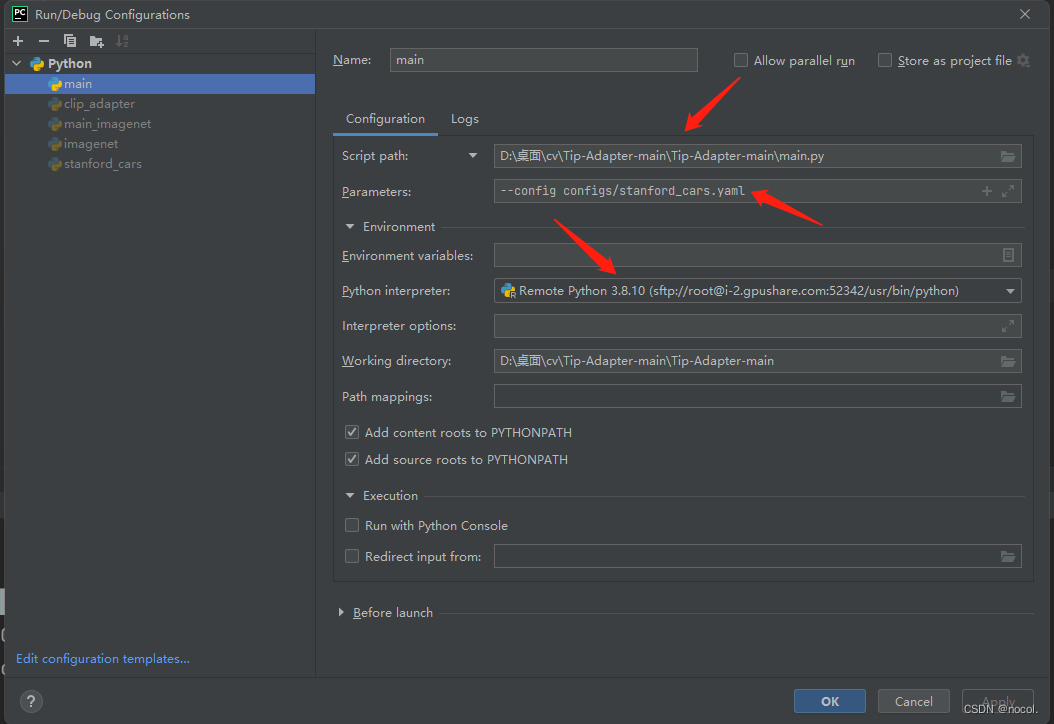
这里解释一下Parameters为什么是--config configs/stanford_cars.yaml,因为REDME中运行指引中要求运行代码格式为(把源代码中的dataset.yaml换成指定的stanford_cars.yaml):
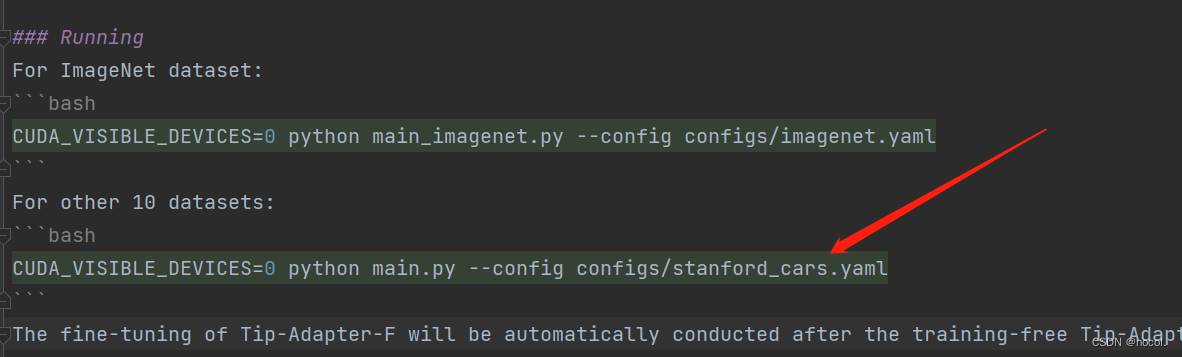
基于此环境配置差不多结束了,然后我们按照REDME的指引一步步运行代码:
首先我们在git上下载代码(已下载的可以省略)

之后我们cd到Tip-Adapter下:
![]()
之后我们创建一个名为tip_adapter的python环境(官方默认python3.7,这里我使用的是3.8)
![]()
然后激活:

接着下载环境需要的包

最后安装对应版本的pytorch和cuda

最后我们运行代码:

运行结果:
默认的一些超参数,后期可以调

通过视觉和文本标签的特征构建缓存模型:
加载文本和视觉特征:

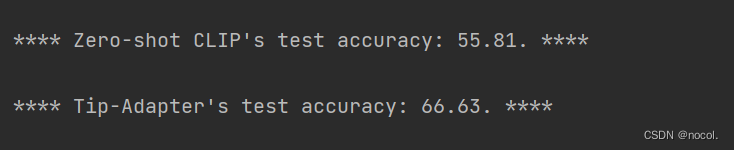
zero-shot CLIP 和Tip-adapter的精度:
训练Tip-adapter-F(20个epoch):
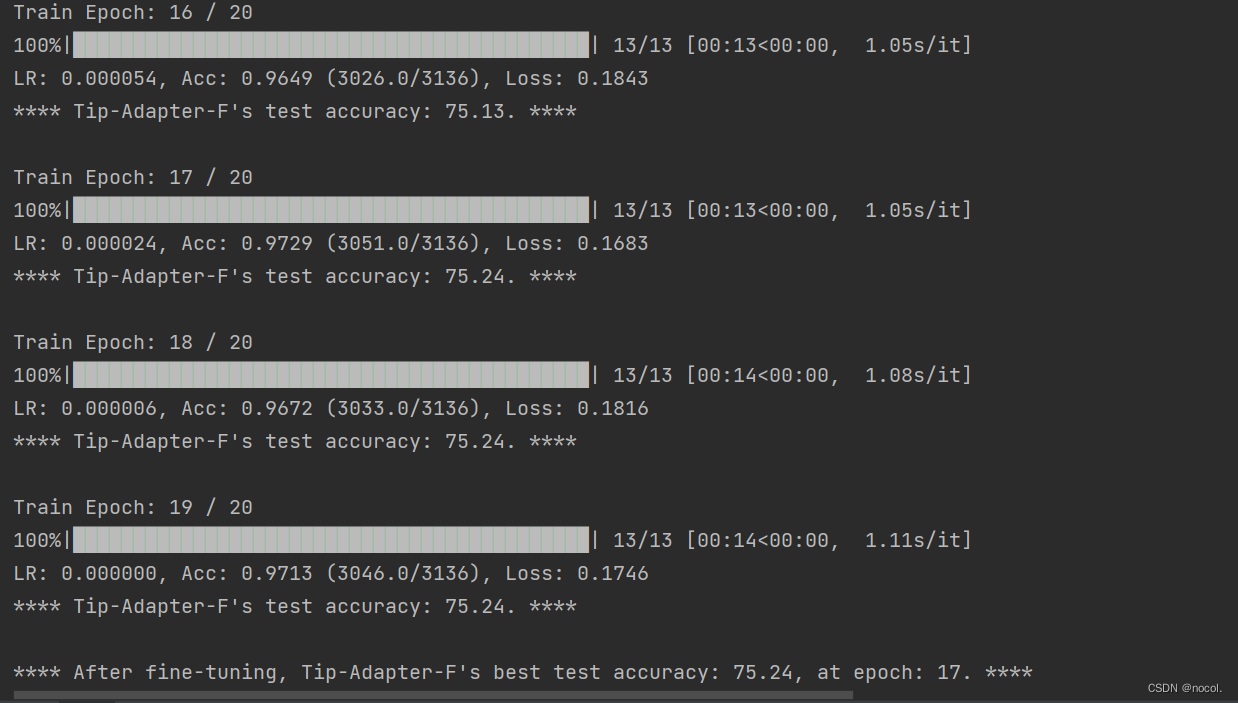
第17轮训练精度最高,达到75.24,效果要比zero-shot CLIP和Tip-adapter的55.81和66.63好不少

欢迎大家指正!














 5060
5060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









