







Motivation
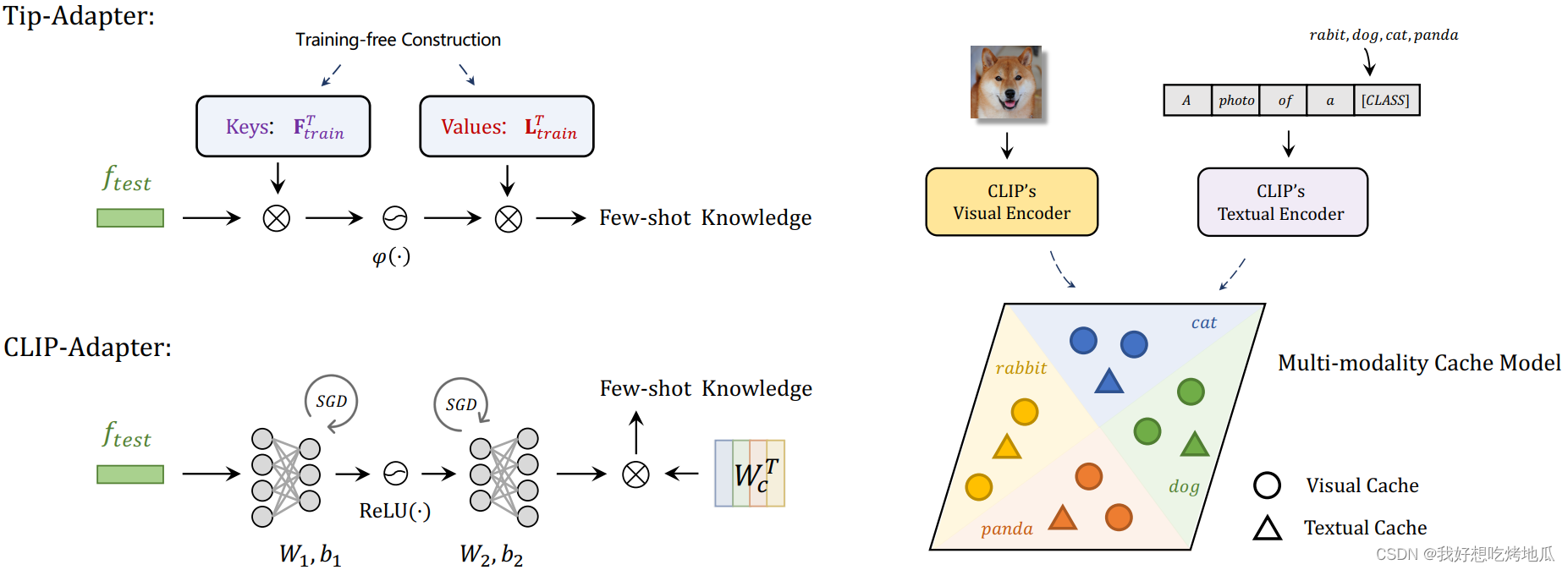
CLIP 通过 Zero-shot 知识迁移在下游任务上表现出令人印象深刻的性能。为了进一步提高 CLIP 的自适应能力,现有方法提出对附加可学习模块进行微调,这大大提高了 Few-shot 性能,但引入了额外的训练时间和计算资源。提出了一种无需训练的 CLIP 进行 Few-shot 分类的方法,称为 Tip-Adapter,它不仅继承了 Zero-shot CLIP 无需训练的优点,而且性能与需要训练的方法相当。
它们需要更多的计算资源来微调新引入的可学习参数。因此提出了以下问题:能否做到两全其美,既能利用 CLIP 在 Zero-shot 分类时无需训练的特性,又能在 Few-shot 分类时拥有需要训练的方法的强大性能?
Method
Training-free Adaption of CLIP
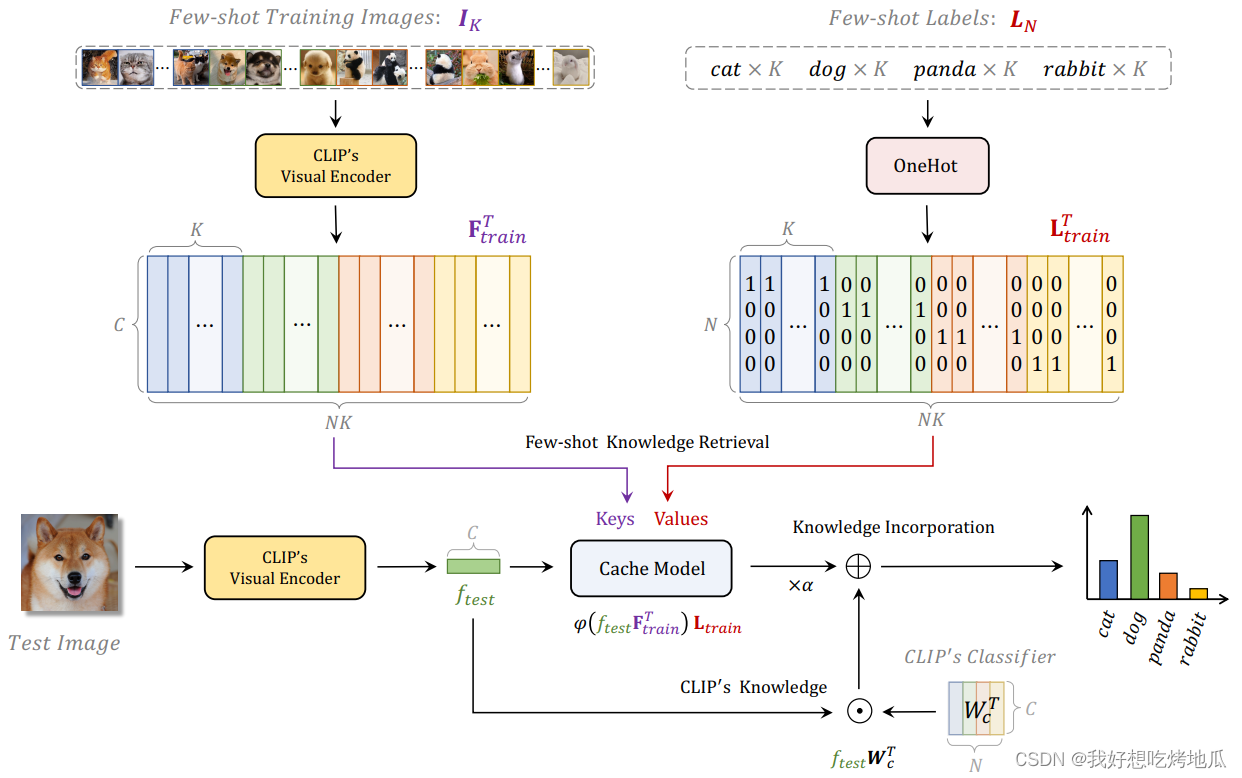
以非参数的方式从 Few-shot 训练集构造了一个 key-value 缓存模型。有了这个设计良好的缓存模型,Tip-Adapter 无需微调就可以达到与那些需要训练的方法 (包括 CoOp 和 CLIP-Adapter)相当的性能。此外,如果允许训练,Tip-Adapter-F 通过对缓存键进行微调,以超快的收敛速度进一步超越最先进的性能。
Cache Model Construction
给定预训练的 CLIP 和一个具有
K
K
K 个
N
N
N 类训练样本的新数据集,用于 FS 分类,则
N
N
N 个类别中每个类别有
K
K
K 个带标注的图像,记为
I
K
I_K
IK,标记为
L
N
L_N
LN。目标是创建一个键值缓存模型作为特征适配器,它在
N
N
N 个类中包含少量的知识。对于每个训练图像,利用 CLIP 预训练的视觉编码器提取其
c
c
c 维
L2
\text{L2}
L2 归一化特征,并将其真值标签转换为
N
N
N 维 one-hot 向量。对于所有
N
K
NK
NK 训练样本,表示它们的视觉特征和相应的标签向量为
F
t
r
a
i
n
∈
R
N
K
×
C
\mathbf{F}_{train}∈\mathbb{R}^{NK×C}
Ftrain∈RNK×C 和
L
t
r
a
i
n
∈
R
N
K
×
N
\mathbf{L}_{train}∈\mathbb{R}^{NK×N}
Ltrain∈RNK×N,
F
t
r
a
i
n
=
VisualEncoder
(
I
K
)
\mathbf{F}_{train}=\text{VisualEncoder}(I_K)
Ftrain=VisualEncoder(IK)
L
t
r
a
i
n
=
OneHot
(
L
N
)
\mathbf{L}_{train}=\text{OneHot}(L_N)
Ltrain=OneHot(LN)
对于 key-value 缓存,将 CLIP 编码的表示
F
t
r
a
i
n
\mathbf{F}_{train}
Ftrain 视为键,而将 one-hot ground-truth 向量
L
t
r
a
i
n
\mathbf{L}_{train}
Ltrain 用作其值。键值缓存存储了从 FS 训练集中提取的所有新知识,用于更新预训练 CLIP 中编码的先验知识。
Tip-Adapter
在构建缓存模型后,CLIP 的自适应可以简单地通过两次矩阵-向量乘法来实现。在推理过程中,首先由 CLIP 的视觉编码器提取测试图像的
L2
\text{L2}
L2 归一化特征
f
t
e
s
t
∈
R
1
×
C
f_{test}∈\mathbb{R}^{1×C}
ftest∈R1×C,并作为从键值缓存中检索的查询。查询和键之间的关系可以估计为:
A
=
exp
(
−
β
(
1
−
f
t
e
s
t
F
t
r
a
i
n
T
)
)
A=\text{exp}(-\beta(1-f_{test}\mathbf{F}^T_{train}))
A=exp(−β(1−ftestFtrainT))
其中
A
∈
R
1
×
N
K
A∈\mathbb{R}^{1×NK}
A∈R1×NK,
β
\beta
β 为调制超参数。由于查询特征和键值特征都是
L2
\text{L2}
L2 归一化的,术语
f
t
e
s
t
F
t
r
a
i
n
T
f_{test}\mathbf{F}^T_{train}
ftestFtrainT 等价于测试特征
f
t
e
s
t
f_{test}
ftest 和所有少量训练特征
F
t
r
a
i
n
T
\mathbf{F}^T_{train}
FtrainT 之间的余弦相似度。采用指数函数将相似度转换为非负值,并用
β
\beta
β 调制其锐度。然后,对缓存模型的预测可以通过查询键相似度加权的缓存值的线性组合得到,记为
A
L
t
r
a
i
n
∈
R
1
×
N
A\mathbf{L}_{train}∈\mathbb{R}^{1×N}
ALtrain∈R1×N。除了从缓存模型中检索到的 FS 知识外,预训练 CLIP 的先验知识由
f
t
e
s
t
W
c
T
∈
R
1
×
N
f_{test}W^T_c∈\mathbb{R}^{1×N}
ftestWcT∈R1×N 计算,其中
W
c
W_c
Wc 为预训练的文本编码器生成的 CLIP 分类器的权重。通过残差连接混合两种预测,Tip-Adapter 测试图像的输出 logits 被计算为
logits
=
α
A
L
t
r
a
i
n
+
f
t
e
s
t
W
c
T
=
α
φ
(
f
t
e
s
t
F
t
r
a
i
n
T
)
L
t
r
a
i
n
+
f
t
e
s
t
W
c
T
\text{logits}=\alpha A\mathbf{L}_{train}+f_{test}W^T_c=\alphaφ(f_{test}\mathbf{F}^T_{train})\mathbf{L}_{train}+f_{test}W^T_c
logits=αALtrain+ftestWcT=αφ(ftestFtrainT)Ltrain+ftestWcT
Tip-Adapter 的预测包含两项,前一项自适应地总结了来自 FS 训练数据集的信息,后一项保留了来自 CLIP 分类器
W
c
T
W^T_c
WcT 的先验知识。这两项通过权值
α
α
α 来平衡。如果预训练和下游的 FS 任务之间的域差距很大,则
α
α
α 被调大,因为需要从 FS 集获得更多的知识,否则调小。
Tip-Adapter with Fine-tuning
Tip-Adapter 可以通过将新知识融入到 FS 训练集中来极大地提升 CLIP。然而,经过更多的样本,未经训练的 Tip-Adapter 逐渐落后于需要训练的 CoOp 和 CLIP-Adapter。为了在保持效率的同时减小这种差距,提出了 Tip-Adapter-F,它将缓存模型中的键作为可学习参数的良好初始化,并通过 SGD 对它们进行微调。得益于缓存模型的有利起点,Tip-Adapter-F 与 CoOp 和 CLIP-Adapter 的 200 epochs 训练相比,在 ImageNet 上只需 20 epochs 微调即可达到 SOTA。
更具体地说,解冻了缓存的键,但仍然冻结了预训练 CLIP 的 L t r a i n \mathbf{L}_{train} Ltrain 和两个编码器。更新缓存模型中的键可以提高相近性的估计,更准确地计算测试图像和训练图像之间的余弦相似度。相比之下,缓存模型中的值是代表 ground-truth 注释的独热编码,需要保持冻结,以便更好地记忆类别信息。















 1462
1462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









