







最近看《深入理解计算机系统》系统级IO部分,突然想起之前和同学讨论的关于文件描述符和FILE*的差别,很不好意思的是,当时我说了一个错误的答案,,
在继续下文之前,先抛出几个问题:
1、可不可以对同一文件open两次?如果可以,关闭呢?
2、我们知道进程创建是父子进程复制,也即子进程继承父进程打开的文件描述符,那父进程还是子进程关闭?
3、当open时,发生了什么?文件内容从硬盘传入内存了吗?
4、为什么当不再操作文件描述符时要close,不close不行吗?或者说close时发生了什么?
5、什么叫带缓冲区的读?理论上,内存与硬盘交互数据大小是以页为单位的(通常是4K),那缓冲区中就已经包含了文本文件的数据,为什么还需要应用级缓冲?
6、系统IO与标准IO库是什么关系?文件描述符和FILE*是什么关系?可不可以混用?作为程序员应该用哪种?
一、Linux系统关于文件的数据结构
既然题目是从Linux看IO,那当然得看真家伙(Linux 0.11)。每个进程的控制结构PCB(Linux中用task_struct结构)中都有一个文件描述符表,通常说的文件描述符就是文件描述符表的索引。文件描述符表的内容是指向文件表(file table)的指针,其中文件表是所有进程共用的,由内核来维护。文件表也是一个数据结构(struct file file_table[]),也即file_table指向一个文件的Inode表,当然iNode表也是由内核维护的,由所有进程共享的。
struct task_struct{
....
struct file* filp[NR_OPEN];//文件描述符表,NR_OPEN=32,数组内容类型为struct file*,也即指向下面的file_table项
}
struct file file_table[NR_FILE];//文件表,NR_FILE=64,每一项为struct file类型
struct file{
unsigned short f_mode;
unsigned short f_flags;//与f_mode都是open时传入open(pathname,f_flags,f_mode),当然与传入参数不大一样
unsigned short f_count;//文件的引用计数
struct m_inode *f_inode;//文件的iNode
off_t f_pos;//文件的偏移位置,默认打开时为0,可以通过lseek来更改文件的位置。
}
//文件的iNode
struct m_inode{
unsigned short i_mode;//访问权限控制
unsigned short i_uid;//用户
unsigned long i_size;//文件大小(byte)
unsigned long i_mtime;//修改时间
unsigned char i_gid;//使用者ID组
unsigned char i_nlinks;//hard link
unsigned short i_zone[9];//块区!
/* these are in memory also */
struct task_struct * i_wait;//等待唤醒的进程
unsigned long i_atime;//最后访问时间
unsigned long i_ctime;//最后改变时间
unsigned short i_dev;//设备号
unsigned short i_num;
unsigned short i_count;//引用计数
unsigned char i_lock;//加锁
unsigned char i_dirt;//数据是否修改
unsigned char i_pipe;//管道信息
unsigned char i_mount;
unsigned char i_seek;
unsigned char i_update;//缓冲区的数据可否代表硬盘
}二、Unix系统级IO概述
我们知道Linux/Unix哲学是:一切皆文件。这是一个非常美妙的抽象,将各种不同的外设、文件系统都归为一类,而用简单的文件操作就可以操作。
Unix系统级IO函数只有如下几个:
int open(const char * filename,int flag,int mode);//打开文件
int close(int fd);//关闭文件,fd为open返回的文件描述符
int read(int fd,void *buf,int maxlen);//从当前位置读取最大maxlen字节到buf中
int write(int fd,const void *buf,int maxlen);
int lseek(int fd,int offset,int origin);//移动当前文件位置,origin:代表移动的模式,0为从头开始定位offset,1表示从当前位置定位offset,2表示从文件结尾定位offset,当然,offset可正可负。结果返回当前文件位置,若定位文件位置<0,返回负数。
int stat(const char *filename,struct stat *buf);
int fstat(int fd,struct stat *buf);//读取文件的metadata(元数据这个翻译太难受了)三、调用open()时发生了什么?
记得之前最头痛的就是各种高级语言的open,虽然知道每次进行IO操作时都要open,但是open之后发生了什么?把文件内容读到了内存?
open函数是一个系统调用,事实上所有的上面说的系统级IO函数都是系统调用,每次调用都会陷入内核。
当调用open函数时,会发生如下步骤:
- 检查是否可用获得一个文件描述符,即在PCB(task_struct->flip[])中找到一个合适的位置,因为flip只有32项,所有每个进程最多打开32-3项,为啥要减3,因为进程默认打开了输入(fd = 0),输出(fd = 1),错误(fd = 2)。
- 检查是否可用获得一个文件表项,即在file_table中获取一个合适的 位置,因为file_table有64项,且为所有进程共享。所以所有进程最多可用同时打开64个文件。当然前3项是输入、输出、错误。这里所谓的合适指struct file中的引用计数为0,即对应文件没有被使用的。
- 如果满足上述条件,将加载对应文件的iNode(每个iNode唯一对应一个文件,同理,每个文件只有一个iNode),为了体现进程共享的思想,如果对应的iNode已经在inode数组里,就将其返回,并将引用计数+1,如果没有其他进程加载该iNode,将从iNode数组里分配一个空的项,并从硬盘加载iNode。
四、当调用read函数时发生了什么?
这是个非常有趣的问题,当我们调用read时,要传入三个参数,文件描述符、指向缓冲区的指针、已经读取字节数。
- 首先,根据f_pos和count数判断读取文件是否超过文件大小,如果超过,将count截断。如count为0,即已经到文件结尾,返回0
- 根据f_pos/BLOCK_SIZE,得到文件数据块号,经过bmap映射到硬盘中的逻辑块号,而设备号存在于iNode中
当得到设备号和块号后,会先检查该块是否已经在缓冲区里了,如果在,返回buffer_head。如果不存在才会读盘。然后将从f_pos开始的count字节的数据复制到应用程序的buf中。这里是Linux共享文件思想的另一个体现。
所以,我们得到如下结论:缓冲区与硬盘块以block为单位进行数据交换;当我们读取文件时,并不会将全部文件读入到内存,特别地,当文件特别大时,如果将文件全部读入到内存可能并不合适,所以可以显式的调整f_pos和count来读取数据;
所以,我们依次回答上述问题:
对同一文件可以open多次吗?
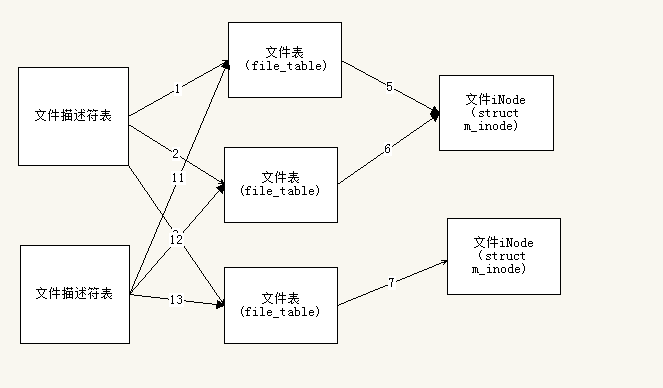
可以,如果进程(不管是否同一个)中多次open同一个文件,那么将会产生多个文件描述符项和文件表项。注意到文件表项中struct file中存在着f_pos字段,所以进程可以用不同文件描述符从不同位置开始读写文件。同理,如果关闭的话,打开几次就要关闭几次。否则对应资源永远不会回收,这里的资源主要指进程文件描述符数组资源、文件表数组的资源、iNode数组的资源。(此时,如上图1,2线所示)当父进程调用fork()函数创建子进程后呢?
当父进程创建子进程,根据父子进程复制的思想,子进程将继承父进程的文件描述符表。此时,父子进程各自一套文件描述符表,只是内容完全一样,也即,此时父子相同的文件描述符指向同一个文件表项。当时该文件表项的引用计数+1,此时,如上图,1&11,2&12,3&13线所示。
所以这也就解释了,为什么当对文件操作结束后,父子进程都要关闭文件。因为如果某一个没关闭,文件表中对应项的引用计数将为1,那么将永远占据该项。
当然了,当进程退出时,将会自动关闭的。当open时发生了什么?文件数据从硬盘传递到内存了吗?
open只是将文件的iNode加载到内存中,但文件的数据并没有传递到内存。为啥要这样设计?我们知道读盘是非常耗费时间的,量级大概在10ms(如果CPU主频是1GHz的话,那么也已经执行了百万条指令了),所以操作系统的设计思想是能不读盘就不读盘,一定要到非读不可的时候才会选择读盘,而且读的时候是以块为单位读的(典型为4K),即使只读一个字节。为啥要以块为单位读?因为磁盘读数据的时间主要花费在了寻道上,也就是说读第一个字节的时间,而顺序读的时间是很低的,所以如果,只读几个字节的话,整体效率太低了。close(int fd)时发生了什么?
首先,将文件描述符对应项清空,将原对应的文件表项的引用计数-1,如果此时该项引用计数为0,释放inode。为什么有了内存缓冲区还要显式的要添加应用级缓冲区呢?
内核缓冲区是由内核来维护的,是不对应用可见的。每次读内核缓冲区时都要显式的陷入内核状态才可以。这样会增大花销。所以可以维护一个应用级缓冲区。相当于是内核缓冲区的一个子集。当应用级缓冲区不够用时,显式的调用read函数,如果此时内核缓冲区有需要的数据,直接返回,如果没有,就从硬盘读。这个过程是对程序员友好和透明的。
五、系统级IO vs 标准IO库
几乎每种高级语言都有自己的标准IO库,但是这些都是对系统级IO的封装。比如C语言的fopen,fclose,fseek,fread,fwrite等等等等。
一般来说,对普通文件的操作,建议使用系统级IO函数,因为对程序员更友好些。但是对于网络应用,比如socket文件,标准IO库便不太好使了,这时候使用系统级IO更好。
六、文件描述符 VS FILE指针
文章开头提到的文件描述符和FILE指针的关系,现在是时候揭开面纱了。实际上,FILE数据结构中包含一个文件描述符,毕竟要通过该描述符进行读写数据。与此同时,内部还维护着一个指向缓冲区的指针。注意,该缓冲区指的不是内核缓冲区,而是应用级缓冲区,这样可以提高读取速度。
那问题来了,那能不能标准C库与系统级IO函数混用呢?共同操作同一文件描述符?答案是否定的。因为FILE结构里面维护着一个缓冲区。也就是说使用fread()时,读取的个数实际上是缓冲区的个数,而不是程序指定的读取字节数。所以两者不可混用,因为f_pos与程序员看到的可能已经不一致了。
这也就是为什么对于网络应用而言,我们希望迅速将数据传递出去,而不是存放在缓冲区里,此时,不应该使用标准C库的IO函数,而应该使用系统级IO。
七、关于文件结尾
我们如何标识一个文件在硬盘中的结尾呢?很多人以为硬盘中有个特殊的字符EOF,当硬盘读到这个字符时就截止。但这是错误的。硬盘里并没有什么特别的东西标志文件的结束。作限制的是iNode中的i_size,即文件的大小。当读取文件的位置+读取数>i_size时,这时候就要显式的对读取数做限制。当f_pos指向了文件结尾,但还在读时,将返回0,这也就是标志EOF的来历了。















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









