







2016_Person Re-identification Past, Present and Future
Liang Zheng, Yi Yang, and Alexander G. Hauptmann
这是一篇有关于Person re-ID 综述性文章。
转载请附原文地址:http://blog.csdn.net/zdh2010xyz/article/details/53741682
Abstract
re-ID变得越来越important。早期,主要是有关hand-crafted算法与小规模的evaluation的文章。近些年,large-scale datasets 与 deep learning系统兴起。文章将目前的re-ID问题分为两大类,image-based和video-based。在每一类的讨论中,都会回顾hand-crafted和deep learning system问题。同时,讨论了两个接近真实应用的new re-ID任务:end-to-end re-ID 与 fast re-ID in very large galleries。
文章贡献:1)介绍了person re-ID的历史,以及其与image classfication 和 instance retrievial的关系。2)详细分析了image-based 与 video-based re-ID任务中的hand-crafted systems与 large-scale methods。3)描绘了end-to-end re-ID与fast tetrieval in large galleries是未来的方向。4)最后简短的叙述了一些under-developed但又很important的问题。
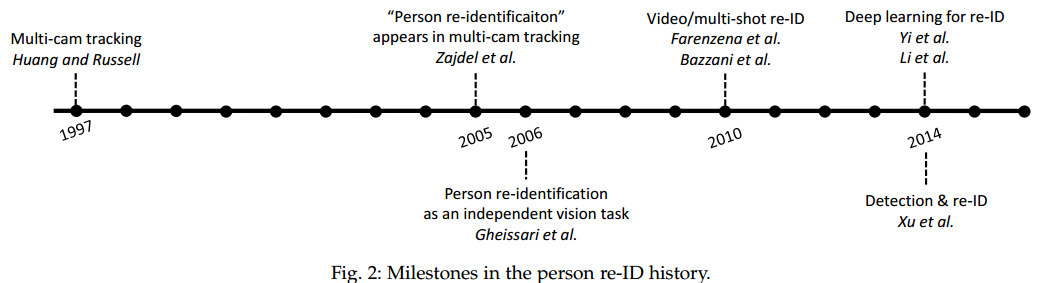
1 Introduction
讲什么是re-ID。开头有关特洛伊战争,没看懂。。。反正就是re-ID很重要,有实践价值。
从技术上讲,实际视频监控系统的person re-ID系统可分为三个模块:person detection,person tracking,和 person retrieval。前两个任务是独立的计算机视觉任务,所以大家主要的工作还是最后一个模块。
论文安排:文章主要讨论的是re-ID的vision part。文章与以前的综述性文献不同的是,本文注重re-ID的subtask(现在available的以及未来可能的),而没有过分细讲techniques或者architectures。特别强调的是:deep learning methds、end-to-end re-ID 以及 large scale re-ID。1.2节介绍re-ID的历史。1.3节介绍re-ID与classification和retrieval的关系。第2、3章分别介绍image-based、video-based的相关文献,每一类都分为hand-crafted与deeply systems方法。第4章回顾了detection、tracking以及re-ID相关的技术,并指出未来研究重点。第5章介绍代表当前最好的retrieval models:large-scale re-ID,这也是未来研究的方向。第6章介绍了一些open issues。第7章结论。
至于与Classification和Retrieval的关系,person re-ID 结合了二者的优势。一方面,在训练阶段,可以从person space学习到区别能力强的ditance metrics或者feature embeddings。另一方面,在检索阶段,有效的indexing structures和hashing techniques将有助于large gallery中query的检索。

2 Image-based person re-ID
主要模型是使用单张图像作为query,模型可描述为closed-word model,G是gallery,包含N张图像,特征可描述为
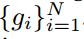
这N张图像属于N个不同的identities。给定一个probe(query)q,其identity号可以通过过以下公式获得:
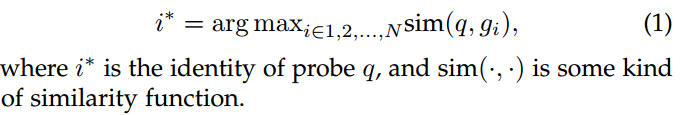
2.1 Hand-crafted Systems
从公式(1),可以看出一个re-ID 系统,包括两个组成部分,image decription与distance metrics。
(1)pedestrian description
使用最多的feature是color,texture features使用相对较少。一般使用的是weighted color histogram(WH)、maximally stable color regions(MSCR)和recurrent high-structured patches(RHSP)。WH 赋予对称轴附近像素更高的权重,对于每个part得到一个color histogram。MSCR主要处理stable color regions,提取特征包括color、area、centroid等。RHSP是纹理特征,recurrent texture patches。
近些年,hand-crafted features所注重的特征多多少少都是一样。Zhao et al. 提取10*10图像块的32-dim LAB color histogram和128-dim SIFT特征。同时,采用Adjacency constrained search技术,按水平划线分块对应匹配的方式,从gallery image中找到最合适的匹配块。这种方式也有很多人研究,代表性的有SCNCD、LOMO以及BoW等。
除了直接提取low-level color和texture features,还有一种选择:attribute-based features,可以看成是mid-level representations。可以确信,相对于low-level descriptors,采用attributes进行image translation具有更强的鲁棒性。已经有很多文献做了这方面的工作,结果表明效果优秀。
(2)Distacne Metric Learning
在hand-crafte re-ID systems中,一个良好的distance metric是至关重要的。原因:high-dimensional visual features typically do not capture the invariant factors under sample variances. 关于metric learning methods,已经有文章详细综述。文章将其分为 w.r.t supervised learning versus unsupervised learning与global learning versus local learning等。在person re-ID,主要是supervised global distance metric learning。
global metric learning,一般而言就是使属于同一类的vector距离尽量closer,不属于同一类的尽量further apart。最常采用的是马氏距离(Mahalanobis distance)。在person re-ID中,最出名的metric learning method 是KISSME(原理没弄懂,以后再补)。
在马氏距离的基础上,一大批metric learning method涌现。Weinberger提出large margin nearest neighbor Learning (LMNN) method、Davis提出information-theoretic metric learning (ITML)。最近,Hirzer提出relaxing the positivity constraint,具有更低的计算开销。Chen在马氏距离中,融合了bilinear similarity,使得cross-patch similarities can be modeled。等等。。。
除了learning distance metrics,也有人关注learning discriminative subspaces(不懂,待以后详述)。同时,也有人采用其他的学习工具,比如说SVM、Boosting。
2.2 Deeply-learned Systems
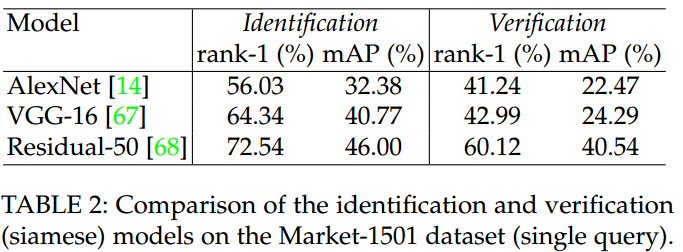
自从Krizhevsky赢得了ILSVRC 12比赛,CNN-based的深度学习模型得以流行。两类CNN模型广泛应用:1)classification model,用于image classification和object detection。2)siamese model,用于image pairs or triplets。在re-ID使用深度学习的瓶颈是lack of training data。由于大部分数据集为每个identity提供两张图像,所以目前CNN-based re-ID方法主要是采用siamese model。
siamese model的一个缺点是不能完全利用re-ID annotations。其实,siamese model仅仅使用了pairwise (or triplet) labels。另外一个与潜力的策略是采用classification/identification mode,这样可以充分利用re-ID labels。在大规模数据集,如PRW、MARS,classification model取得了在without careful training sample selection情况下的优秀性能。但为了模型收敛,应用identification loss需要更多的training instances per ID。
以上所提到的工作是以end-to-end的方式learn deep features。也可以采用 提取low-level features作为输入,比如SIFT、color histograms,整合进入Fish Vector。
2.3 Datasets and Evaluation
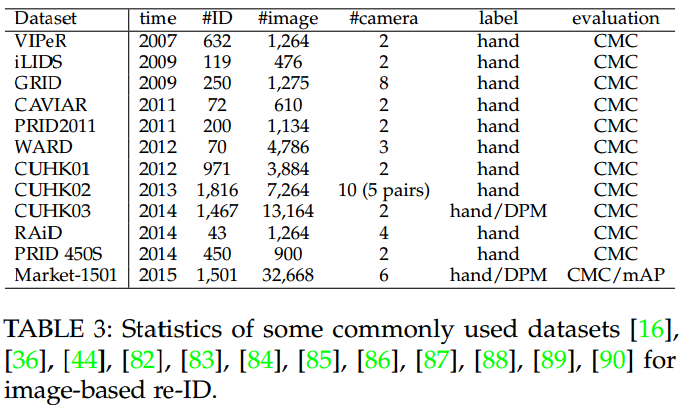
第一,数据集的规模在不断扩大。第二,bounding boxes开始采用pedestrian detectors获得,例如DPM、ACF等。第三,采用了更多的摄像头。
Evaluation Metrics,主要是cumulative matching characteristics (cmc) curve。但随着研究的输入,尤其是multiole ground truths的存在,也有人提出mean average precision (mAP)。
Re-ID Accuracy Over the Years,在不断提升。
3 Video-Based Person Re-ID
Vedio-based methods主要关注的multi-shot matching 方案和对temporal imformation的整合。
3.1 Hand-crafted Systems
主要是color-based descriptors。与image-based re-ID类似。主要的不同是距离计算上,这涉及到两个sets of bounding box features。称为“multi-shot”person re-ID。
这些方法主要是基于multiple shots,构建appearance models。现在一个新趋势是incorporate temporal cues in the model。Wang采用spatial-temporal descriptors来再识别行人。特征包括HOG3D,以及the gait energy image (GEI) 步态能量图像。Gao 利用周期性行人,将步态分为几个片段,进行识别。
3.2 Deeply-learned Systems
video-based 和image-based re-ID的明显区别是,with multiple images for each matching unit (video sequence), 在video pooling 后,要么采用multi-match strategy,要么采用a single-match strategy. 在以前的工作中,采用multi-match strategy,但计算量大。另一方面,pooling-based methods,将多个query的vector池化到一个global vector,扩展性好。由此,目前的video-based re-ID都会包含pooling step,可以是max/average pooling,或者从一个fully connected layer获得。
Another good practice:injecting temporal information in the final representation。
3.3 Datasets and Evaluation
multi-shot re-ID的数据集包括ETH、3DPES、PRID-2011、iLIDS-VID,和MARS。
4 Future:Detection,Tracking,and person Re-ID
4.1 Previous Works
尽管现在person re-ID是一个独立的研究任务,但文章认为未来会结合pedestrian detection 和tracking。特别的,文章认为end-to-end re-ID 系统(spotting a query person from raw videos),把raw videos作为输入,整合pedestrian detection 和tracking,再进行re-identification。
目前,大部分re-ID工作都是假定两点:1)给定行人边界匡的gallery。2)边界匡hand-drawn。这样会有很好的检测精度。但是在实际中,这两种假设是不成立的。一方面,gallery 大小会随着detector threshold而变化。低的阈值会产生更多的bounding boxing(更大的gallery,高的recall,但低的precision),反之亦然。re-ID检测的准确度将会由于不同的阈值,而不问题。另一方面,使用pedestrian detectors,bounding boxes中不可避免的会出现错误(misalignment, miss-detection, and false alarms),这将大大影响re-ID的检测准确性,这现在还很少有人考虑这个问题。
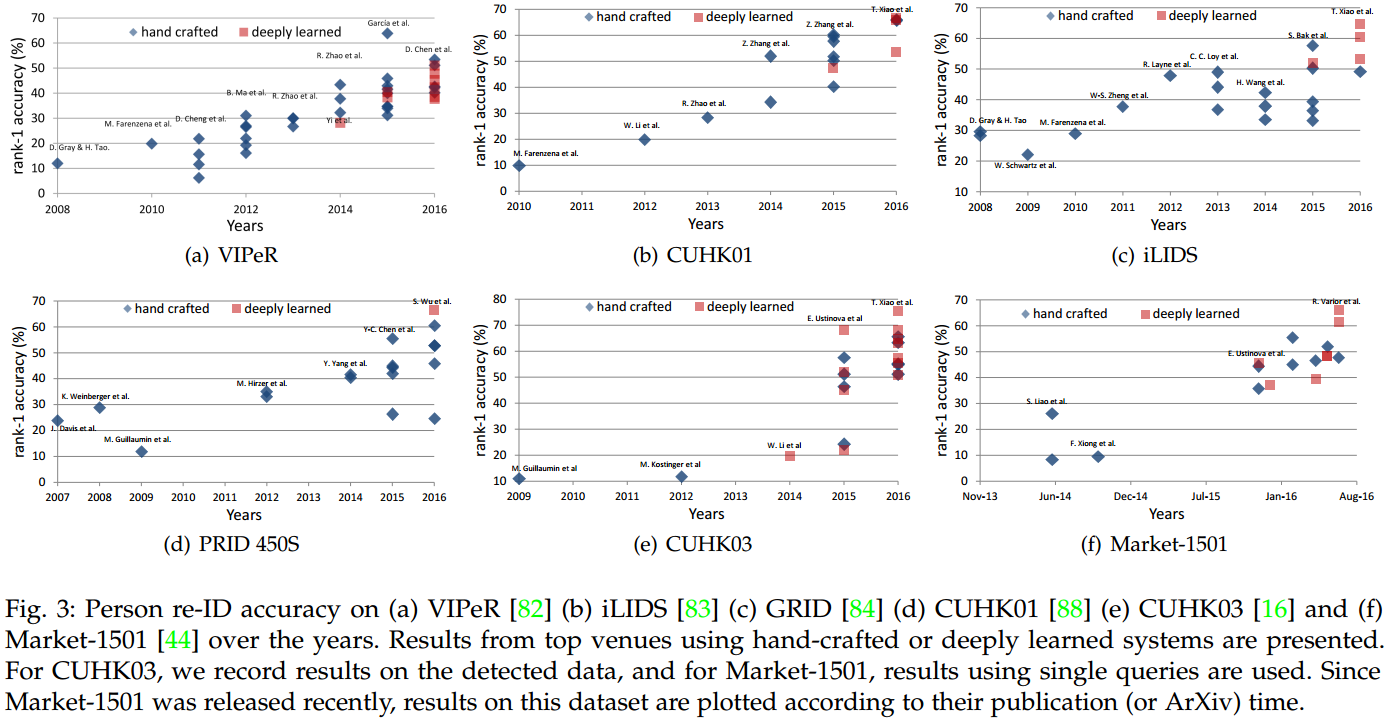
第二个问题,很多数据集,如CUHK03, Market-1501, and MARS,与实际场景很类似。在这些数据集中,采用检测器检测的bounding boxes与采用hand-drawn bounding boxes,前者所获得检测精度要比后者低。在MARS数据集中,虽然提出了tracking errors与detection error,但我们不知道tracknig errors是怎么影响re-ID accuracy的。这在end-to-end person re-ID 系统中,如何挑选detectors和tracker将是一个难题。 2016年,xiao和zheng差不多同时提出了基于large-scale dataset的end-to-end re-ID system。都是将raw video frame与query bounding box作为输入。如下图所示:

从图中可以看出,在给定同样re-ID feature的情况下,better better pedestrian detector会产生higher re-ID accuracy。从多篇论文中,可以得出结论,良好的pedestrian detection将有助于person re-ID。
但是,在这些所谓的end-to-end系统中,还没有人研究pedestrian tracking。这一工作被视为整合detection、tracking与retrieval为一个框架的终极目标。此项研究需要提供用于这三个任务的的bounding box annotations的大规模数据集支持。
4.2 Future Issues
1)System performance evaluation
一个适当的evaluation methodology对于end-to-end re-ID任务异常重要,end-to-end re-ID不同于常规的re-ID问题,它带有dynamic galeries。同时,现在还不知道如何evaluate detection/tracking 在person re-ID中的性能表现。下面从两个方面提出问题:
1。针对re-ID中pedestrian detection和tracking的evaluation metrics相当重要。evaluation protocol应该能够quantify and rank detector/tracker performance in a realistin,同时是unbiased manner and informative of re-ID accuracy。由于在person re-ID任务中,只是要找出这个person,并不太关心person检测的准确性。所以,文章认为可以采用miss rate与average precison作为person re-ID中pedestrian detection性能的评价。
另外一个就是AP/MR的计算,这个涉及IoU的值,试验结果表明,IoU阈值取0.7要比取0.5,检测精度更加稳定。文章的建议是larger IoU criteria能保证better localization results,但这个也得根据不同的情况而定。
虽然有了关于pedestrian detection的evaluation,但对于person re-ID中的tracking,现在还是largely unknown。在以前的multiple object tracking (MOT) benchmark,常用multiple object tracking precision (MOTP)、mostly track (MT) targets、the total number of false positives (FP)、the total number of ID switches (IDS)、the total number of times a trajectory is fragmented (Frag)、the number of frames processed per second (Hz)等,可能一些指标会受到处理速度的影响,因为person re-ID中的tracking任务是off-line step。For re-ID, we envision that tracking precision is critical as it is undesirable to have outlier images in the tracklets which
compromise the effectiveness of pooling. We also speculate that 80% might not be an optimal threshold for evaluating MT under re-ID. 在未来的数据集中,一旦考虑考虑re-id的tracking问题,首要任务就是设计出适当的metrics来评价不同的tracker。
2。w.r.t the evaluation procedure concerns the re-ID accuracy of the entire system.
这里涉及到detector的threshold问题,太strict,则gallery少,则目标可能包含不全;太loose,则gallery多,则可能会有更多的背景包含进去。这两种结果对re-ID结果都不好。暂时还没有有效的解决办法,但记住一点,这个gallery的大小是受detector threshold控制,在设计new evaluation metrics要考虑到这个问题。
另外一个点,就是如何从一段给定的视频中定位到query的identy出现的位置,这个任务要比detection/tracking+reidentification相对简单,不要求有那么高的检测精度,只要能定位就行。这个任务中,可以设定loose IoU,将更多的精力放到matching上,即从一大堆的bounding box或者spatial-temporal tube中找到特定的person。
2)The Influence of Detector/Tracker on Re-ID
对于end-to-end re-ID系统,研究detection/tracking methods/data对re-ID的贡献。
第一:pedestrian/tracking errors确实影响re-ID accuracy。但也有去研究表明,detection/tracking errors可以在更早的阶段避免。举个例子,Xiao所提出网络中,他在fast R-CNN sub-model网络中加入localization loss,这对re-ID system的有效定位很有帮助。未来的研究,可以关注person re-ID中detection/tracking quality的独立性。鉴于开发无错误的detector与 tracker是不现实的,文章建议在re-ID matching scores中整合detection confidence。举例:how to correct errors by effectively identifying outliers、how to train context models that do not rely solely on detected bounding boxes.
第二,需要更加关注detection和tracking,如果设计得当,将会大大促进re-ID。虽然我们暂时不能直接看出pedestrian detection/tracking对re-ID有帮助,但可以参考通用image classification and fine-grained classification,可以获取一些线索。如果能够更好的区分不同的identity,会对区分行人与背景有帮助,同样相反也是。
另外一个可以研究的点是unsupervised tracking data。在视频中进行行人跟踪是一件没有那么难得事,虽然不可避免的是会存在错误。但是,人脸识别、颜色、非背景信息都有利于提高tracking的准确性。在追踪的过程中,行人会有比较大的变化。运用这些序列图,即racking results,用来训练pedestrian verification/identification.以减轻对大规模supervised data的依赖。
5 Future:person re-ID in very large galeries
虽然数据库的规模一直在扩大,但很明显,还远未达到时用的地步。所以,person re-ID in very large galleries should be a critical direction in the future.
6 Other important yet Under-developed open issues
6.1 Battle Against Data Volumn
person re-ID中数据集的标注是一件非常难得事情,因为不仅要标注边界匡,还得标注出ID。最近两年,有一些大规模的数据集出现,如Market-1501、PRW、LSPS和MARS,首先得感谢这些数据集的制作者,但这些数据集也还是远未达到实用的地步。文章认为可以有两种替代策略来改善这一问题。
第一:在tracking和detection中使用annotation还有待深入探讨。第二:transfer learning。transfers a trained model from the source to the target domain。
6.2 Re-ranking Re-ID Results
re-identification可以看成是retrieval过程,则re-ranking对于提高检索的精度变得非常重要。
7 结论
略















 1856
1856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









