







 本文深入探讨了MySQL数据库处理SQL语句的内部机制,包括连接池、查询缓存、词法分析器、优化器和执行器的角色。连接池负责处理通信协议和线程,验证用户权限。查询缓存虽已废弃,但以前用于存储静态数据。词法分析器对SQL进行词语和语法分析,优化器则选择最优执行计划。执行器根据表引擎类型执行SQL,与存储引擎交互获取结果集。
本文深入探讨了MySQL数据库处理SQL语句的内部机制,包括连接池、查询缓存、词法分析器、优化器和执行器的角色。连接池负责处理通信协议和线程,验证用户权限。查询缓存虽已废弃,但以前用于存储静态数据。词法分析器对SQL进行词语和语法分析,优化器则选择最优执行计划。执行器根据表引擎类型执行SQL,与存储引擎交互获取结果集。
当我们执行一条sql语句时,是怎么流经mysql数据库的,又会怎么一步步被加工处理的,探索下以便对myqsl数据库有个宏观的认知。我觉得这个步骤是初识Mysql中很基层重要的一步,如同房子中的地基,是学好mysql的前提。
Mysql内部组件结构
平时我们都是使用navicat等客户端执行sql语句,发送到mysql服务器,然后mysql服务器返回执行结果给客户端。sql语句在mysql服务器端会被怎么处理呢?看如下结构图:
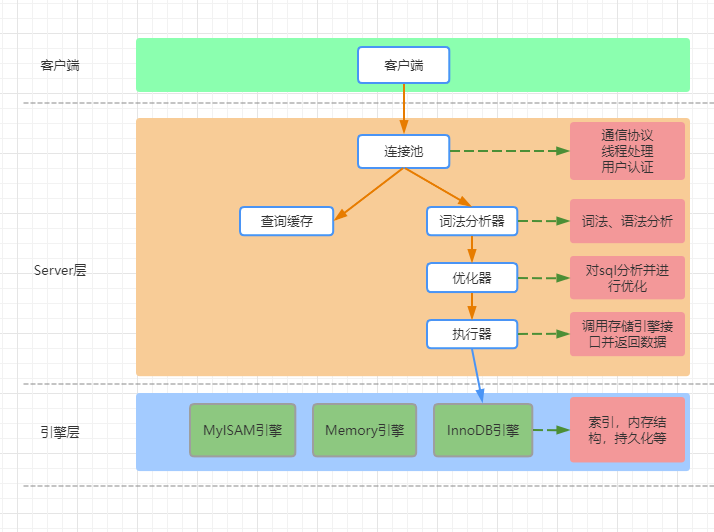
从上图可以看到Mysql体系结构分为两层:Server层和存储引擎层,其实Server层还能细分为连接层和SQL层。而连接池的主要工作就是处理通信协议,线程处理,用户认证;SQL层的工作主要是权限校验,查询缓存,词法分析器,优化器,执行器。接下来我们仔细看看这些都是干嘛的。
连接池
前面已经说了连接池的主要工作就是处理通信协议,线程处理,当我们使用navicat、jdbc等客户端向Mysql服务器发送sql查询时,第一步就是和mysql建立TCP连接(不懂TCP连接的可以看这篇网络通信原理),当连接建立好后,Server层就会分配一个线程来处理该sql语句,接着就要验证用户的有效性,密码是否正确等。
连接命令:
mysql -h [数据库地址] -u[用户名] -p[密码] -P [端口号]
验证完密码后就连接成功了。然后给用户赋予相应的权限,并且把相关权限都缓存起来,读取数据时就获取内存中的权限来验证,此时你修改用户权限是没有用的,因为你改不了内存的数据,只能是物理的数据。
取系统权限时按以下表顺序从mysql系统空间中获取:
user -> db -> tables_priv -> columns_priv
可以使用以下命令去创建用户尝试着验证下:
// 创建用户
create user 用户名@[host|%] identified by [password] 密码;
eg: create user 'hello'@'host' identified by 'iampassword';
// 赋予用户权限
grant all privileges on *.* to 用户名@host; //*.* 表示 所有库的所有表
eg: grant all privileges on *.* to 'hello'@'%';
// 刷新权限
flush privileges;
// 查看用户权限
show grants for hello@"%";
可以用show processlist;命令查看当前连接的线程;
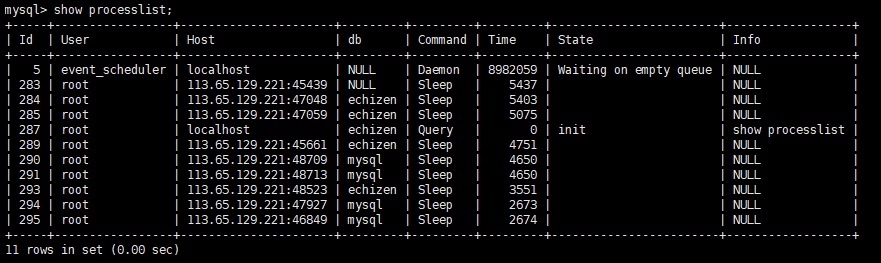
默认这些连接处于sleep状态8个小时后会被关闭,如下:
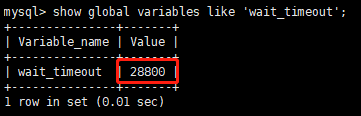
可通过一下命令修改:
set global wait_timeout=2880;
连接阶段结束了,sql就会继续往下流。
查询缓存
在验证完了相关连接权限后,sql就会到缓存里查询是否存在该sql需要的数据。
虽然mysql在Server层提供了一个查询缓存区域,但是非常的鸡肋啦,它只是存储些静态数据,万一有更新,则这个缓存的命中率就太低了。
当然啦,这是以前版本的,现在的版本mysql已经移除了该查询缓存,所以这里只当是做了解一下。可以通过以下命令查看下就知道了:
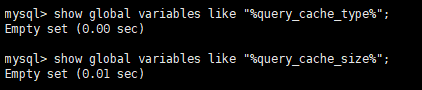
可以看到已经查询不出来了,被废除了。
词法分析器
上面的家伙已经不处理了sql了,所以就流到了词法分析器这里。分析器就需要对这条sql进行词语分析和语法分析,比如说看看这条sql语句书写的单词有没有错误,这条sql是否符合mysql规定的语义。
我们拿一条sql来解析下比较容易理解:
select name, age, address from user_properities where age > 15 and name like '张%' order by id;
- 首先分析器拿到sql语句,会分析select,from,where, order by这些关键字是否书写正确。
- 接下来就分析语法了,比如select是不是与from搭档,你总不能先写from再写select吧。
- 然后就做语义分析,目前该sql语句只是一个字符串而已,需要将其转化为mysql认识的语句,将字段,表解析出来,比如标记name, age, address 为列,user_properities为表。
在mysql做分析时,会使用Bison去分析语法,然后生成语法树:
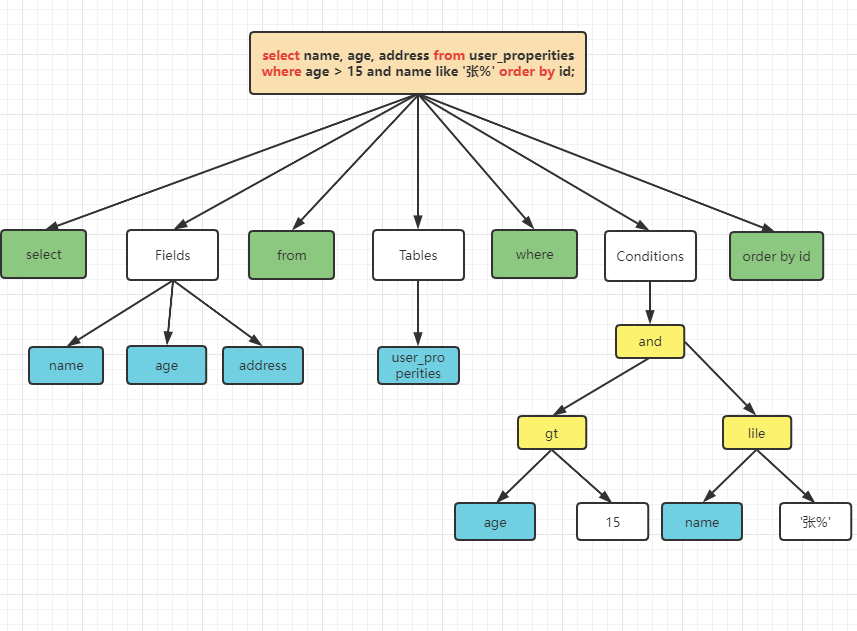
至此,分析器就分析完了,流到优化器这个工人来工作了。
优化器
优化器拿到sql之后,就会去优化这条sql,让sql执行的更加高效,那么优化器怎么知道该怎么优化sql呢?
mysql会根据sql做出一系列复杂的计算,比较下是用索引还是全表扫描等等查询数据比较快,这里会涉及IO成本和CPU成本的计算,考虑的因素有很多,比如索引的选择,回表的数据是否多,笛卡尔集的计算方式等等,将所有可能影响的因素做一个估算,有一点的偏差,毕竟不是用真实的sql执行一遍。
我们可以通过explain format=json来查看执行计划:
explain format=json select * from sys_role;
可以看到执行计划输出如下:

我这个sql语句非常简单,所以只能看到一个评估,如果很复杂的话,可能不止一个评估。
我们也可以看到一些花费时间项:
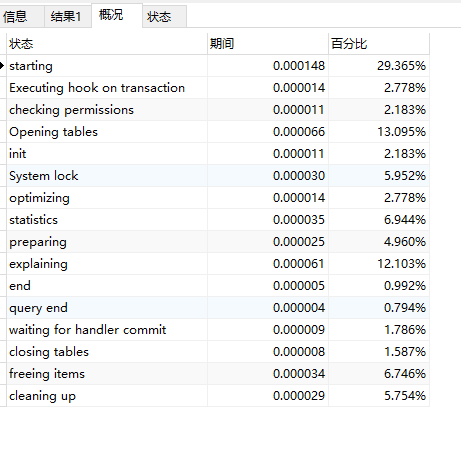
当执行计划有多个评估时,会使用query_cost字段最少花费来作为执行准则。
优化工作当然不止一个执行计划,mysql还会对sql语句做很多优化操作(如果你的sql不规范),比如将*号替换为字段名,如果使用Inner into连接表,做选择小表来驱动大表,还有很多,感兴趣的可以看官方文档:sql优化文档
执行器
该最后一位老铁上线了,该老铁拿到sql语句之后,会去判断表的引擎类型,然后去调用引擎接口获取结果集,执行器拿到结果集后就返回给客户端,当然,引擎里面还会做很多事的,比如Innodb引擎,
- 调用接口后会根据你的sql条件看看有没有索引,有的话就查询B+树中的数据。
- 如果是二级索引,则看看需不需要回表。
- 如果数据在buffer中,则直接返回。
- 如果是更新插入操作,则修改buffer数据,刷盘,写log等。
Innodb的操作很多,就不在这展开细说了。
这就是mysql执行一条sql语句的流水线了,这对于mysql来说是很重要的基石。

















 2829
2829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









