







该篇主要模拟推演kafka从0到1的演变过程,看看一台消息中间件是怎么一点点搭建起来的,其中也会讲述到怎么预防消息丢失,重复消费等问题。
目录
kafka的搭建推演
我们来假设kafka是自己公司设计的系统,来推演下发展完善过程。
需求:目前我系统有两个应用A和B,现在B应用需要使用A应用的数据,于是A应用开了个接口给B应用调用。
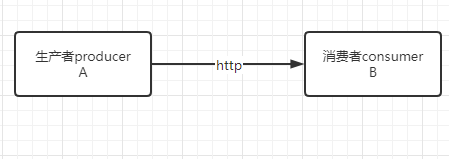
后来系统发展壮大,很多应用都需要使用A应用的数据,于是系统变成如下:
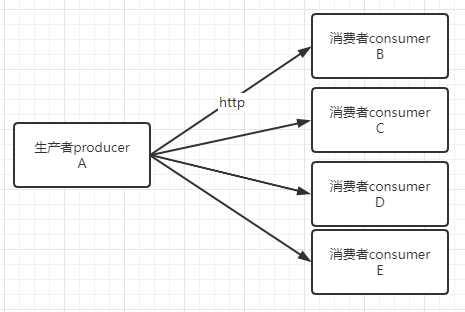
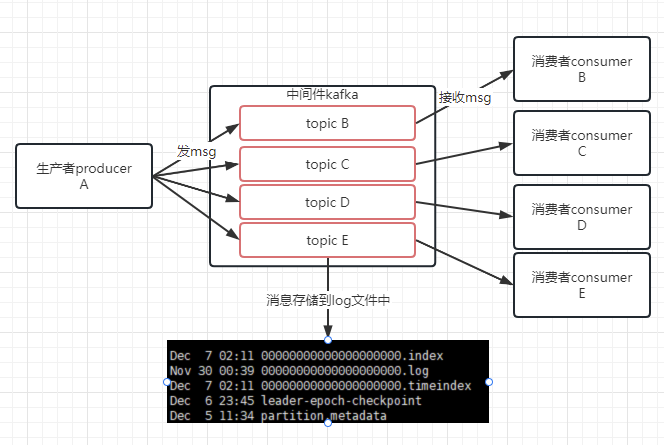
老大说 现在系统中A应用的耦合度太高了,不好扩展,需要把A应用摘出来,于是我们开发了个中间件叫kafka,A应用将BCDE应用需要的数据发送到kafka中,BCDE应用就从kafka中获取数据。
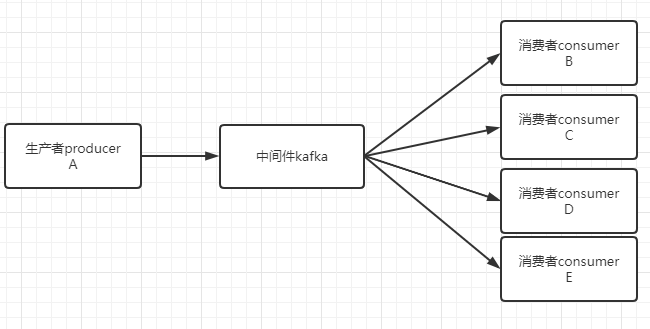
公司越发强大了,发送到kafka中的数据大小已经不是按MB来算了,而是按GB来算,单纯用内存已经不满足需求了,于是开始扩展kafka。
topic与partition
先对接收的数据进行管理先:
因为我们有很多应用系统要接收不一样的数据,数据多了容易混乱,于是我们定义了一个叫topic的主题队列,给数据做个分类,不同的数据发送到不同的topic中,被不同的消费者消费。
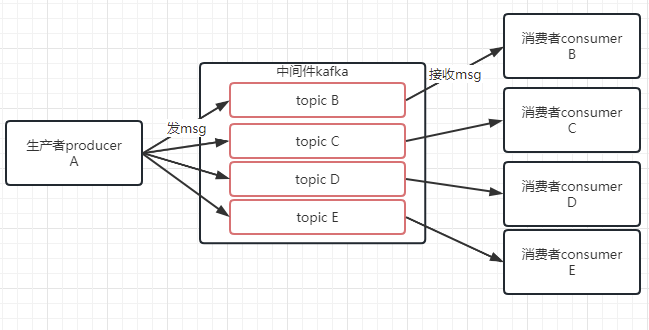
然后数据也不能存储在内存中,于是设计将数据以log的方式存储在log文件中。存储在配置文件中的定义的data/logs目录下。比如下方的主题test1和test2:
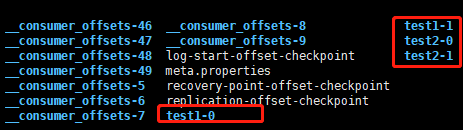
切换到test2-0(随意一个)目录下,都会有以下文件

我们将消息数据都存储在*.log文件里,为了方便检索数据,使用类似跳表的方式来存储数据索引,具体设计如下:
- 当消息发送到topic时,将消息存储到0000000000.log文件中,当文件0000000000.log已经存储了1GB的数据了,则新建一个0000000001.log文件来存储数据,再满1GB了则新建0000000002.log文件,依此类推文件名序号递增。
- 当消息存储到log文件时,如果消息数据达到了64kb时,则将消息对应的offset存储到0000000000.index文件中,以达到一个索引快速检索的目的。
- 在存储offset到对应的index文件中的同时,会将此时系统的时间戳存储到0000000000.timeindex文件中,方便以时间为单位检索数据。
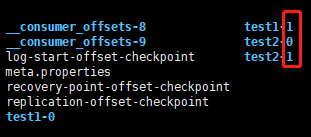
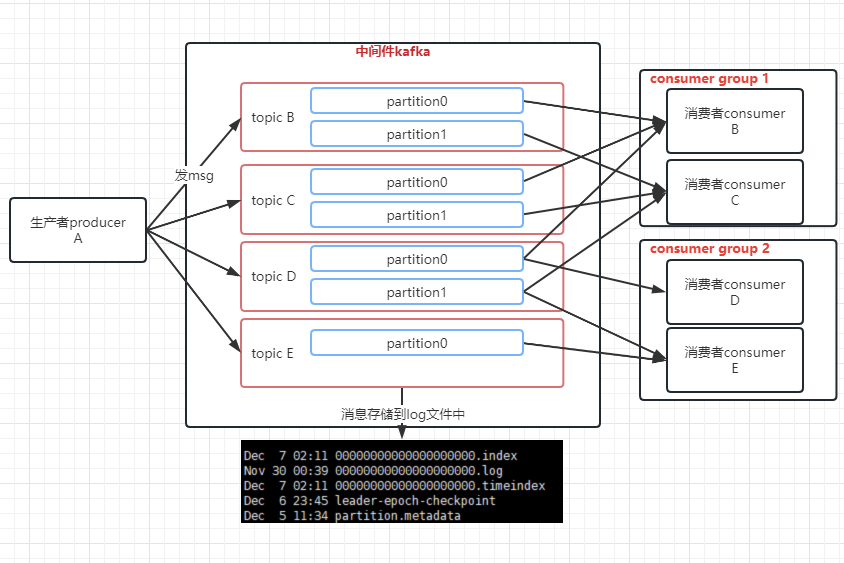
好了一段时间后发现,kafka的能够支撑的消费速度不够快啊,尝试着将topic的队列拆分一下,于是在topic的基础上引入了partition的概念,每个topic都可以拆分多个partition分区,你可以理解为topic里面可以有几个队列(partition分区)。分区用序号0,1,2…表示,你可以看到没有topic目录都有后缀,那个是partition的序号,即以topic名称 + “-” + partition序号作为目录名称。
kafka就发展到了如下图:
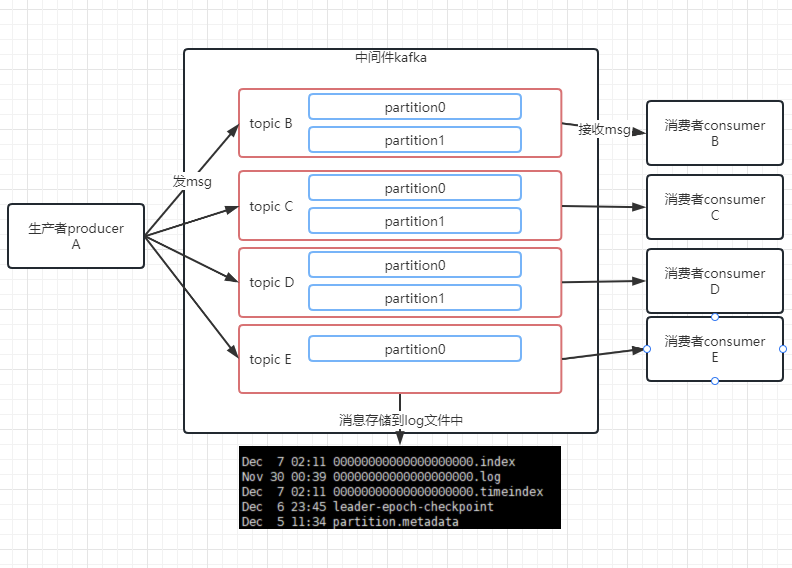
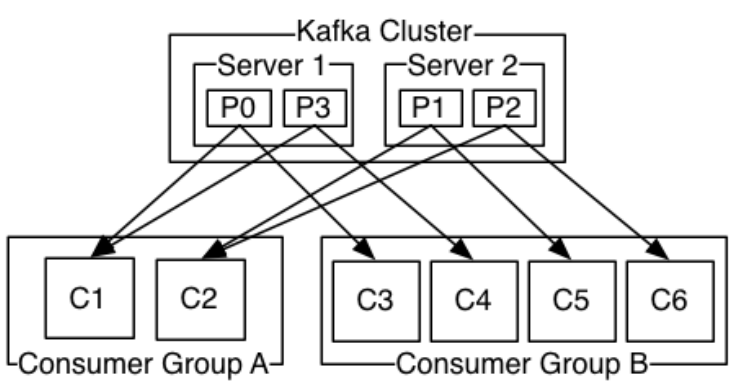
目前的topic消息都是单播给消费者的,即一个topic只被一个消费者消费,我们想让一个topic中的消息能够被多个consumer消费,思虑良久,于是决定引入一个叫消费组(consumerGroup)的概念,所有的topic消息都是针对消费组(订阅者的概念)的,多播功能也是多播到多个消费组,然后消费组里有多个消费者,接收到的消息就由某个消费者消费。
为了保证消息的消费正确性,规定一个partition只能由consumer group中的某个固定的consumer来消费。一个consumer只有唯一的一个consumer group。
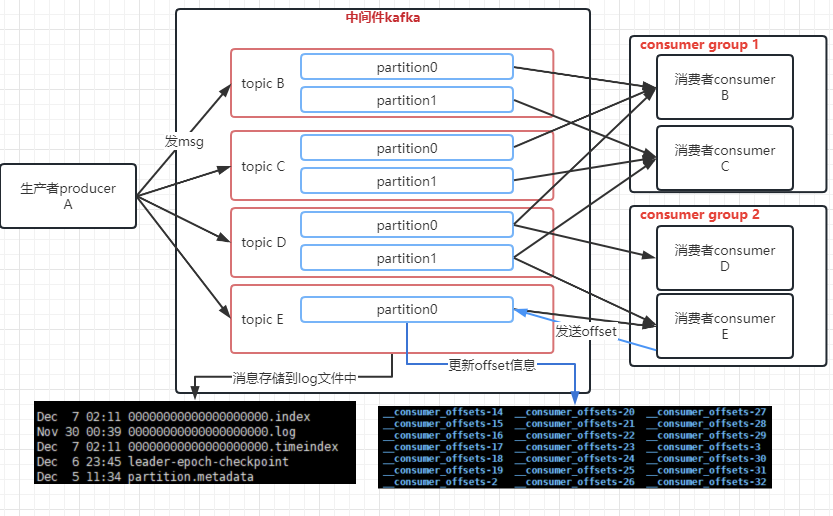
消费消息offset
消费者越来越多了,业务已经发展到上千个消费者了,我们也得管理下consumer消费到了partition里的哪个消息,用offset作为标识,考虑到后续可能需要存储的消费者的offset越来越多,我们也使用文件的方式来存储offset,并且使用多一些文件,能够抗住高并发的场景。
业务场景如下:
- consumer消费者这端自己保存了对应partition的消费消息的offset,即topic+partition区作为consumer端的唯一标识,相当于key,消费消息的offset作为value来保存。
- 消费者consumer会定时发送offset到kafka,就以<consumerGroupId+topic+partition分区号, offset_value>的键值对方式发送,随时更新最新的offset。
- kafka服务会将所有的offset信息存储在_consumer_offsets目录下,为了抗高并发,默认会创建50个目录,会根据公式定位到某个分区下:hash(consumer group id)%_consumer_offsets分区数
- 可以通过参数 offsets.topic.num.partitions设置默认目录数,所有的参数设置可以参考官网:kafka官方配置手册
kafka集群
我们发现当kafka遇到问题宕机时,就会导致我们的系统不可用,不能进行消息消费了,这就对我们的系统造成很大的影响,为了加强系统的可用性,我们就构造了一个kafka集群,选用zookeeper作为注册中心。
kafka的节点注册到zookeeper中,就是在zookeeper中建立一个目录节点。
网上找的一张图:保存kafka一些元数据信息到zookeeper中
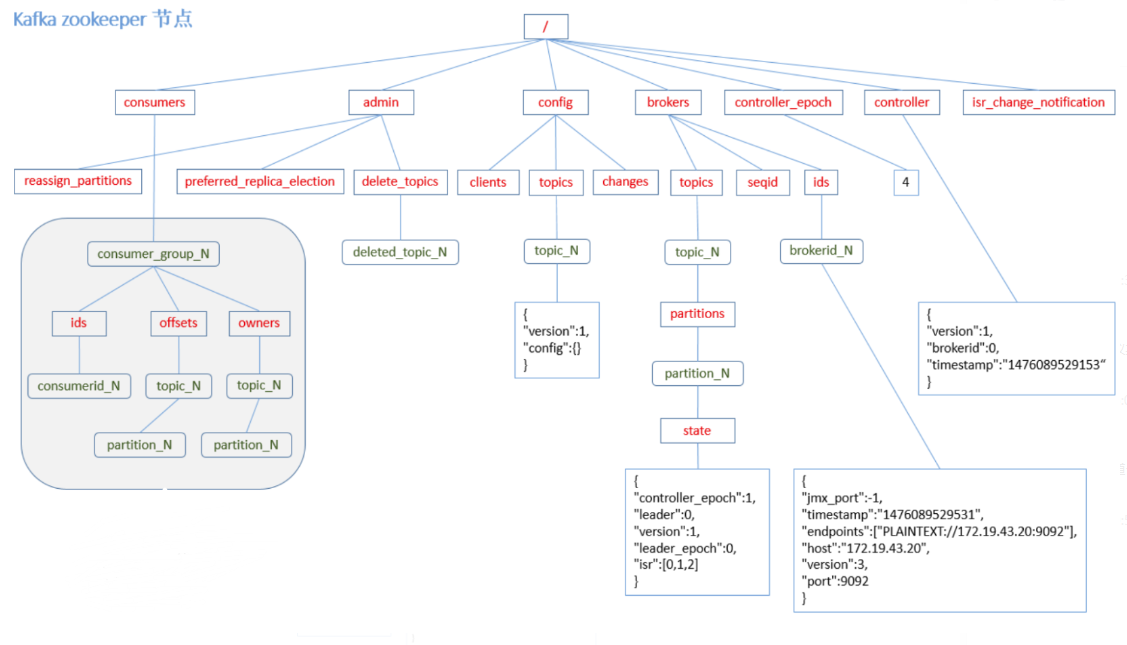
可以看到我们的consumer,brokers,topic等信息都会保存到zookeeper的根目录下。
既然是kafka集群,那么就不止一个broker节点,我们假设有3个节点,那么就需要有一个主节点(称为kafka controller),kafka总控制器需要负责整个集群间的节点管理,信息同步等,主要职能如下:
- 当leader partition挂掉了,则需要kafka控制器重新选举新的leader partition。
- 当检测到某个partition的ISR集合变化了,则需要kafka控制器通知所有的broker更新其元数据
- 当某个topic增加partition了,则需要kafka控制器通知其他broker有新的partition变化。
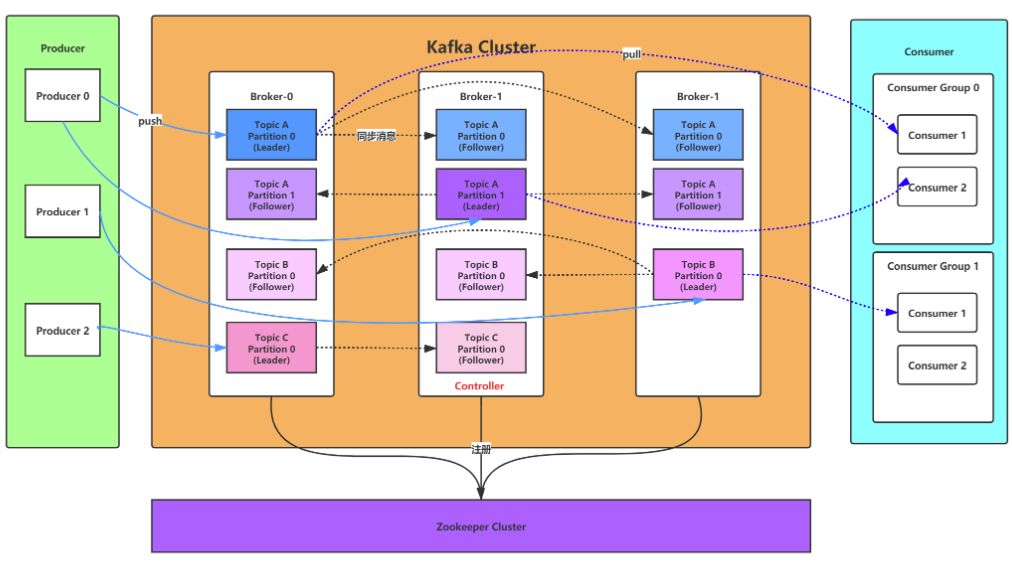
如何选举controller
是利用了zookeeper的特性来完成的,zookeeper支持建立临时节点目录,所有的broker都会尝试在zookeeper中建立/controller临时目录,zookeeper会保证只有一个broker能够建立成功,建立成功的broker则成为了kafka controller。zookeeper还提供了watch机制,就是监控某些节点的变化,当/controller目录被删除了则表示kafka没有了控制器,其他broker通过watch监控就能发现控制器丢失了,会重新进行选举操作。
controller的职责就是基于zookeeper的监听机制完成的:
- 监听broker的变化:给zookeeper的/brokers/ids节点添加BrokerChangeListener,能够知道broker节点的增减
- 监听topic的变化:给zookeeper的/brokers/topics节点添加TopicChangeListener,能够知道topic增减的变化,给/admin/delete_topics节点添加TopicDeletionListener,可以处理topic被删除的动作
- 监听partition的变化:对所有topic对应zookeeper中的节点,对/brokers/topics/[topic]节点添加PartitionModificationListener,可以监听分区的变化
- 从Zookeeper中读取获取当前所有与topic、partition以及broker有关的信息并进行相应的管理,更新集群的元数据信息,同步到其他普通的broker节点中
Partition leader选举
partition也是有副本和leader的,partition的leader也是需要选举的,一般在集群中partition的leader和其他副本都是放在不同broker中的,防止某个broker宕机了所有数据就会丢失了,那么partition是如何选举的呢?
首先kafka会维护一个ISR集合,里面有序保存了有最新同步数据的partition副本,当监听到leader partition所在的broker宕机了,就会选择ISR集合里的第一个作为leader。
可以通过以下命令查看ISR集合:
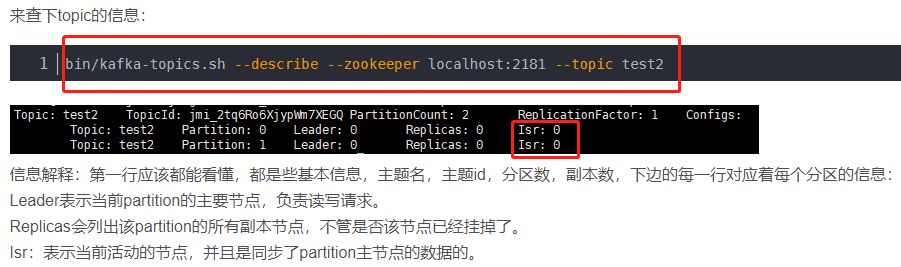
副本进入ISR列表有两个条件:
- 副本节点不能产生分区,必须能与zookeeper保持会话以及跟leader副本网络连通
- 副本能复制leader上的所有写操作,并且不能落后太多。(与leader副本同步滞后的副本,是由 replica.lag.time.max.ms 配置决定的,超过这个时间都没有跟leader同步过的一次的副本会被移出ISR列表)
消费者rebalance机制
还有一个问题就是:当我们系统的消费者数有变化或者partition数有变化时,我们是不是得重新进行分配消费关系,不然就会有空闲的消费者或者分区,显然不合理,所以我们设置了动态重新分配机制。
具体点就是说以下情况会触发rebalance机制:
- 当consumer数增加或者减少时
- 当topic的分区数添加时
- consumer group订阅了更多的topic时
还有需要注意的点就是:
- 如果我们代码里通过了assign方法指定了分区消费,则不会进行rebalance
- 在rebalance的过程中,kafka是无法进行消息消费的,这会影响系统的可用性
rebalance分区分配策略
主要设置了3种策略:range, round-robin, sticky。
可以通过参数partition.assignment.strategy来设置想要的策略,默认是range。
- range策略:基于均分原则,均分有余则将有余的分给前面的消费者,比如有10个分区,有3个消费者a b c,均分应该是3,还余1,则将3+1个分区分给消费者a(1-4分区),将3个分区分给消费者b(5-7分区),将3个分区分给消费者c(8-10分区)
- round-robin策略:轮询策略,还是上边的栗子,分区1分给消费者a,分区2 --> 消费者b,分区3 --> 消费者c,又一个循环将分区4分给消费者a,直到分区都分配完。
- sticky策略:前面两个策略都是全部分区重新分配给消费者的,但是sticky策略不是,它是基于原有基础上尽量公平分配,比如原先按range分配后,当消费者c挂掉了,该策略会将8-10分区中的8分区 --> 消费者a,9-10 --> 消费者b,这样就保证两个消费者都有5个分区了。
rebalance流程
为了实现rebalance,我们还引入了其他的概念,两个协调器:组协调器(GroupCoordinator)和消费者协调器。
- 先选出GroupCoordinator:所谓的GroupCoordinator,是从brokers中选取出来的,用来协调consumer group的,主要是负责接收consumer group中的consumer的心跳,判断consumers是不是宕机了,还有开启rebalance操作。
那么如何选出GroupCoordinator呢?通过consumer group id来确认的,是有个公式定位分区的,上面提到过:hash(consumer group id) % __consumer_offsets主题的分区数,通过该公式定位出分区后,找到该分区对应的leader partition,该leader partition在哪个broker上,则那个broker就是GroupCoordinator。
consumer group中的consumer会向kafka集群发送FindCoordinatorRequest请求,找到对应的GroupCoordinator,然后建立网络连接。 - 加入消费组:在找到了对应的GroupCoordinator之后,消费者会向GroupCoordinator发起JoinGroupRequest请求来发送分区方案,GroupCoordinator会将 第一个请求加入consumer group的consumer 当做该group的leader(消费组协调器),(GroupCoordinator)然后将消费组的情况信息发送给该leader,由leader来定制分区计划。
- 同步分区方案:consumer leader会向GroupCoordinator发送SyncGroupRequest,请求同步分区方案,GroupCoordinator会将方案分发给各个consumer,consumer就会根据方案找到leader partition来进行网络连接和消息消费。
流程图:
线上问题
经过了一段时间的稳定运行之后,突然发现有些消息丢失了,有些消息也重复了等问题,我们就设置了一系列方案来处理这些问题。
消息丢失
我们先来看看可能出现消息丢失的情况,只有要网络传输的地方都有可能丢失消息。
简单流程图:
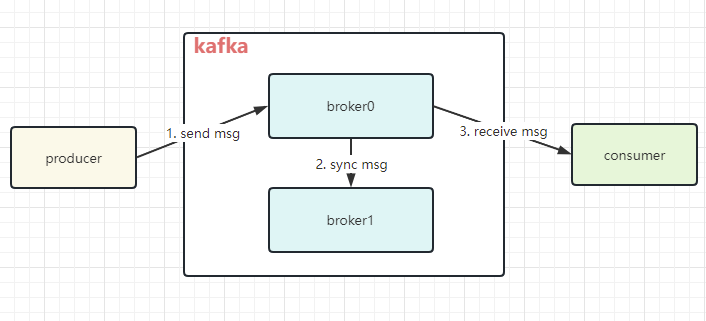
可以看到:这简单的流程图里有3个步骤是进行数据传输的,这就有可能因为网络等原因造成消息的丢失。
- 生产者发送msg到kafka的broker导致的消息丢失。
- kafka集群间的消息同步导致的信息丢失。
- 消费者从kafka中获取消息时丢失。
我们先来看看第一种情况,针对这情况我们设置了一个参数:acks
- 当acks = 0;表示producer发送消息到kafka后,不管kafka是否有反馈,都可以直接发送下一条消息了,类似于UDP协议,只负责发送。这种情况下最容易丢失消息,但是因为不需要等待kafka的确认,所以性能最高。
- 当acks=1;表示producer发送msg到kafka后,需要等kafka的leader broker成功将数据写入本地log并且反馈成功接收信息后才能发送下一个消息。这种情况下会安全些,但是当leader broker挂掉了,选举副本为新的leader时,会有消息的丢失情况发生。
- 当acks=-1或者all时,就表示需要等待leader同步消息到所有副本并且写入本地log成功后,才返回确认信息给producer。这种情况下只要有一个副本没挂掉,都不会丢失数据,这样是最安全的。也可以在该参数的条件下,设置min.insync.replicas参数,表示需要备份的副本个数,设置2个以上就能保证很安全的级别了。
所以通过使用最后一种策略就能保证producer端发送信息的安全性,但是相对的性能就会有点下降。
而且最后一种策略也保证了集群间同步消息的安全性,因为只有副本消息同步完成了才反馈回去,所以也保证了第二种情况,但是当设置acks=0或者1时则不能保证第二种情况。
我们再来看看第三种情况,消费者获取消息时的丢失数据情况。
这种情况下就需要我们自己开发过程中进行手动确认了,只有真的消费到消息了,才会反馈成功消息给kafka,不然则不确认。如果是自动确认的话,则有可能在消息确认提交offset的过程中宕机,导致没有消费完消息。
消息重复消费
对于这种情况,无论是生产者还是消费者,都有可能会因为网络原因而发生,对于这种情况,都得进行发送重试机制和消费幂等性。kafaka生产者这段提供了重试机制,幂等性这个得靠开发者自己处理了。
如果消息是有序的,则重发消息机制就有可能导致消息乱序,这种情况下没法子,只能另外做处理,而且在正常情况下,kafka也只能保证partition内有序,即是说kafka是局部有序的。如果你要想保证消费整体有序,那得在内存中建立一些队列,把需要有序的数据发送到该队列中,然后再进行消费。
消息积压
有时候我们会因为生产端发送消息太快或者消费端消费过慢,从而导致了消息的积压。那么我们就得把这些消息快速处理掉,那要怎么处理呢?
当我们的消费者有余时,即使增加再多的消费者都是没有用的,因为可以分配的分区已经没有了,此时可以起一个新的topic,然后让消费者将这些消息转发到这些topic中,然后用新的消费者来消费。
如果是因为bug导致的消息不能消费呢?
这时候我们会把这些消息转发到死信队列中,然后慢慢分析bug再处理。
延时队列
有时候我们需要存储一些延时消息,等到时间了才处理,比如商城订单下单,有30分钟的付款时间。
可以设置一些topic比如topic_30s, topic_1min等,然后将消息发送到这些topic中,设置一个定时器,定时去检查这些消息是否到时间,如果到时间了则可以处理了。
kafka生产者的幂等性
kafka生产端有可能因为发送消息失败而导致发送消息重试,实际上kafka已经接收到了消息,只是没有反馈回去到生产端,那么就会导致消息重复消费,这时候就可以使用kafka提供的幂等性功能。
只需要在生产端添加参数enable.idempotence即可:
props.put("enable.idempotence", true)
实现原理:
生产端发送消息到kafka时,会将PID(分配给每个producer的唯一id)和Sequence Number(消息的唯一编号,按序号递增)一起发送过去,和消息绑定在一起。kafka会检测消息的PID和Sequence Number,如果发现重复了,则不再接收。
为了保证kafka的高性能,我们实现了kafka磁盘的顺序读写,不会在中间删除数据或者插入数据。还有就是在消息传递过程中的使用了零拷贝技术。














 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









