







记录下kafka窗口命令的使用,以及springboot使用kafka开发项目,不太讲述理论。
kafka简历
kafka是由Linkedin公司开发的,使用的是scala语言开发的。它是一个分布式消息系统,支持分区,多副本,注册中心使用的是zookeeper。主要特性就是能实时的处理大量的数据,基于该特性,能够用于hadoop的批处理系统,storm/spark流处理引擎,nginx日志,消息服务等。
kafka的主要应用场景:
- 收集日志:可以使用kafka收集大量日志,然后做大数据分析等。
- 消息系统:解耦,削峰消费者和生产者系统,缓存信息。
- 用户活动跟踪分析:可以用于收集网站用户点击,搜索活动等,然后进行分析。
- 运营指标监控:可以用于收集自己系统的各种应用指标,监控系统健康状态。
就一句话:kafka最主要的是用来削峰,解耦的,当系统遇到高并发访问时,并且系统扛不住的时候,就可以使用kafka做缓存,kafka能够支持大量的数据缓存。同时也能够解耦系统间的联系。
来过一眼基本概念:
| 名词 | 解释 |
|---|---|
| broker | kafka启动的一个实例,也是作为kafka集群的一个节点 |
| topic | 消息主题,其实就是给消息进行分类,比如按表存储数据,按模块存储代码等都是一个道理 |
| producer | 消息生产者,主要向broker实例发送消息的,可以理解为向表insert数据的 |
| consumer | 消息消费者,主要从broker实例中获取数据,可以理解为从表中select数据 |
| ConsumerGroup | 消费组,每个消费者必定属于某个消费组的,一条消息只能消费组中的一个消费者消费,不限其他消费组,可以理解为连接池,一条sql只能由一个连接来执行 |
| partition | 一个topic可以分成多个partition,每个partition内的消息都是有序的,可以理解为多个队列存储数据 |
broker与consumer,producer之间都是通过TCP协议来通信的。
基本命令
先启动下kafka先
bin/kafka-server-start.sh -daemon config/server.properties
1.1、创建一个名为 test1 的topic主题,并且设定partition为1,副本也为1
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test1
创建成功会有提示:Created topic test1.
1.2、查看当前存在的topic
bin/kafka-topics.sh --list --zookeeper localhost:2181

1.3、删除主题
bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic test1
删除了会被提示:
Topic test1 is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
2.1、使用producer生产者发送消息
kafka提供了一个客户端,可以连接客户端,然后发送消息,默认情况下,一行就是一条记录信息。
先连上producer客户端:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test1
2.2、使用consumer消费者消费消息
同样的kafka也有一个consumer的命令客户端,会消费消息,默认是消费最新消息。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test1
在producer端发送消息,就能够在consumer客户端中接收到消息:

客户端已经接收到消息了

如果要消费consumer客户端启动之前发送的消息,则可以加个–from-beginning参数:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic test1
2.3、消费多主题
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --whitelist "test1|test2"
2.4、单播消费
一个消息只能由一个消费者消费(换句话说:一个消息只能由一个group消费组消费,至于消费组里是哪个消费者消费我们不管)
示例:打开两个消费者客户端,执行一下命令,即划分在一个group组里,然后用生产者客户端发送消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=test1_group --topic test1
该命令执行两次,即表示在group组test1_group中设置两个消费者。
生产者发送消息

消费者接收到消息

这个消费者没有接收到消息

2.5、多播消费
一个消费者被多个消费者消费的形式,要实现这种方式需要添加消费组group,往里面添加消费者。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=test2_group --topic test1
再加个test2_group 的group,就不演示了。
2.6、查看消费组名
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list

2.7、查看消费组的消费偏移量
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test1_group

其中的一些参数含义:
CURRENT-OFFSET:表示当前消费组的已消费偏移量
LOG-END-OFFSET:表示当前主题对应的分区的结束偏移量(总的偏移量数)
LAG:未消费的偏移量数
3.1、创建多个分区的主题
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic test2
partitions 2 指定分区数为2
来查下topic的信息:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test2

信息解释:第一行应该都能看懂,都是些基本信息,主题名,主题id,分区数,副本数,下边的每一行对应着每个分区的信息:
Leader表示当前partition的主要节点,负责读写请求。
Replicas会列出该partition的所有副本节点,不管是否该节点已经挂掉了。
Isr:表示当前活动的节点,并且是同步了partition主节点的数据的。

我们的kafka数据都存储在配置文件里的log路径下,如上图。而且可以看出来,但你的topic有partition时,后面的命名序号会跟着递增。
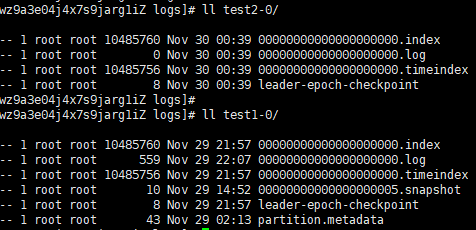
看文件名后缀都能猜到各自存储的是什么数据了。
3.2、增加topic的分区数量(不支持减少)
bin/kafka-topics.sh -alter --partitions 2 --zookeeper localhost:2181 --topic test1
可以看到之前的topic test1已经从一个partition变为2个partition了

主题Topic与消息日志log
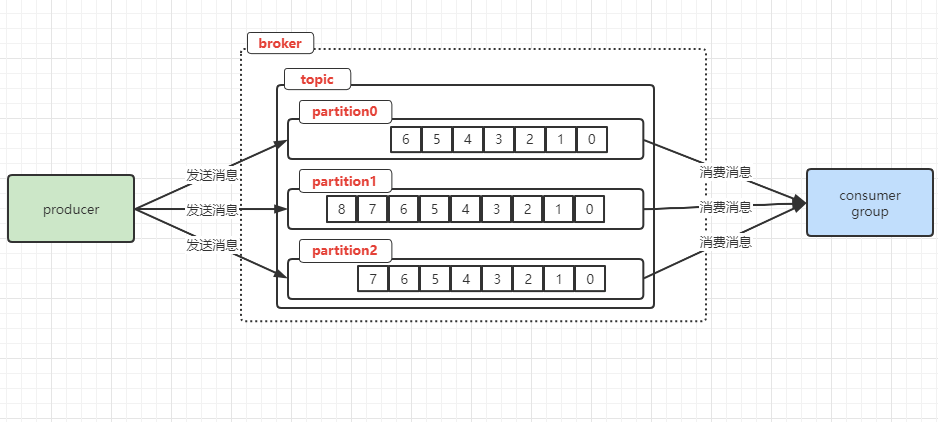
前边已经提过,topic主题就是一种分类,类别,用数据库的概念就类似于表,再在topic中进行分区partition,可以理解为原始情况就是:默认有一个partition,消息都存储在这里,然后要多几个partition来存储消息,就类似于分表来存储数据的情况。你也可以理解为队列的功能。
partition就是一个有序的message队列,会将这些message消息按顺序存储到一个叫做commit log的文件中。每个partition的消息是有offset的,把这个当做消息的编号,可以理解为partition内的消息的唯一编号,因为是offset,所以在不同的partition中是可能存在同样的offset的。
每个partition都会对应一个commit log文件。
消息是存储在log文件中的,kafka默认情况下是不会马上删除这些数据的,会根据参数(log.retention.hours)来确认保留的时间,默认是一周。kafka的性能跟消息数据量是没有什么关联的,所以你保存多少数据都是无所谓的。当然,数据还是会有基于系统文件的限制的,所以也不是无极限的存储。
每个consumer会保存自己在commit log中消费的offset,所以每个consumer都是依据自己的进度来消费消息的,和其他consumer是互不影响的;当然也可以通过指定offset来消费消息,以达到重复消费或者跳过消费的目的。
前面也提到过,我们机器的容量是可能受到容量限制的,所以我们可以进行topic的partition分区,partition分区都放置在不同的机器(即每个机器都有不同的commit log文件),这样就能达到分布式存储的目的;还有一个目的就是能够提高并行度,增加并发。
producer是可以发消息到指定的partition的。
4.1、开启3个broker实例
nohup bin/kafka-server-start.sh config/server.properties > /dev/null 2>&1 &
nohup bin/kafka-server-start.sh config/server-2.properties > /dev/null 2>&1 &
nohup bin/kafka-server-start.sh config/server-3.properties > /dev/null 2>&1 &
4.2、创建一个topic,3个副本,2个分区
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic test-rep-par
这个我就不演示了,资源不够。操作完了可以执行一下命令查看下变化。
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test-rep-par
然后通过producer发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092,localhost:9093,localhost:9094 --topic test-rep-par
可以通过consumer来接收消息,–from-beginning 从头开始接收消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094 --from-beginning --topic test-rep-par
4.3、kill一个broker校验集群可用性
ps -ef | grep server.properties
kill <pid>
然后再执行一下这个命令,会发现leader改变了,Isr也会改变
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test-rep-par
集群消费
对于topic的partition,最好有一个新的broker与之对应,如果有多个副本,则使用该broker作为leader,其他的副本作为follower,这样能保证系统的性能和可用性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









