







Java浮点数存储格式
JAVA中浮点数有两个基础类型:float和double。float占据4个字节,double占
据8个字节。下面将以float类型为例,介绍浮点数的存储方式。double类型和
float类型的存储方式雷同。
1.浮点数的存储方式
浮点数的存储格式比较特殊,下图是4字节的float变量的存储示意图:

根据IEEE754浮点数表示标准,一个float变量在存储中由三部分组成,分别是:
符号位:1位(31),表示float的正负,0为正,1为负
幂指数:8位(23-30),表示2进制权的幂次
有效位:23位(0-22),表示有效数字
2.浮点数的取值范围
在float的存储中,有4个特殊的存储值,分别是:
0x7f800000:正无穷大,Float.intBitsToFloat()打印显示为infinity
0xff800000:负无穷大,打印显示为-infinity
0x00000000:正零,打印显示为0.0
0x80000000:负零,打印显示为-0.0
注意,在Java中,infinity!=-infinity,但是0.0==-0.0
以上4个特殊存储值将float的存储分为4个段
[0x00000001,0x7f7fffff]:正float数,共2^31-2^23-1个
[0x7f800001,0x7fffffff]:非数字,打印显示NaN,共2^23-1
[0x80000001,0xff7fffff]:负float数,共2^31-2^23-1个
[0xff800001,0xffffffff]:非数字,打印显示NaN,共2^23-1
3.浮点数的格式转换
令bits表示一个整数,其存储空间为4字节,下面我们求出这4个字节表示的float
类型数字为多少。
int s = ((bits>>31) == 0)?1:-1; //取出1bit符号位
int e = ((bits>>23) & 0xff); //取出8bit的幂指数
//取出23位有效位
int m = (e==0)?((bits & 0x7fffff) << 1):((bits& 0x7fffff) | 0x800000);
则该存储空间表示的浮点数为 s*m*2^(e-150)
分析:
[0x00000001,0x007fffff]:相应实数范围为[(2^-149),(2^-126)-(2^-149)],即
大约为[1.4E-45,1.2E-38],离散间隔固定为(2^-149)即约为1.4E-45,
实数个数为2^23个。
[0x00800000,0x7f7fffff]:相应实数范围为[(2^-126),(2^128 - 2^104)],即大约为
[1.2E-38,3.4E38],以后每增加2^23个实数,离散间隔增大一倍。
所以,浮点数设计完成了整个A=[0x00000000,0x7f7fffff]离散空间到B=[0.0,3.4E38]区间
部分值的一个映射,该映射具有以下属性:
<1>B中被映射实数的初始间隔为c=2^-149,并且每经过2^23个数间隔变为c=2*c
<2>该映射是单调递增的
评价:
浮点数的存储设计,从本质上来说是设计了一个优秀的数值映射,充分利用了2进制存储
的特点。
Java的double类型探索
一.double类型的存储表示
Java的浮点类型表示完全按照IEEE754标准(Standards of IEEE 754 floatingpoint numbers),有兴趣可以上IEEE标准网站(www.ieee.org)查阅.该标准的内容基本上描述了浮点类型的存储格式(Storage Layout),下面我从中总结几段,来概括该标准,详细信息请查阅标准原文.
1.什么是浮点数.
计算机上表达实数有两中方法:定点表示(fixed-point)和浮点表示(floating-point).定点表示法就是在现有的数字中间的某个位 置固定小数点,整数部分和小数部分的表示和一个普通整数的表示法没什么两样.例如,我们的数字长度为4,小数点位于中间,那么你可以表示10.28,也可 以表示00.01,与这种方法性质类似的定点表示还有使用分数的形式.定点数的固定窗口形式使得他既不能够表示非常大的数又不能表示非常小的数.并且当除 法发生时,大量 的精度丢失.
浮点数采用科学计数法的形式来表示实数.例如123.456可以表示成1.23456×102.相对于定点数的固定窗口(fixed Window)的限制,它采用的是浮动窗口(sliding window),因此可以表示较大精度范围的一个实数.
2.存储布局(StorageLayout)
所谓的存储布局就是一个浮点数在内存中如何表示.我们知道浮点数有float和double,前者是4个字节也就是32位,后者是8个字节也就是64位.布局分别为:
符号 指数 小数部分 偏移附加(bias)
单精度 1[31] 8[30-23] 23[22-00] 127
双精度 1[63] 11[62-52] 52[51-00] 1023
中括号内为位的编号范围,外面为该部分所占有的位的数量.偏移附加不属于位表示的内容,是一个常量,稍后解释.
符号只有一位:0-表示正数 1-表示负数
指数部分:用指数部分的值(8位/11位,unsigned)的值 减去 偏移附加 得到该数实际的指数 例如值为200,实际指数为73=200-127.对于双精度的double来说常量bias=1023
尾数:尾数是什么?对于一个科学计数法来讲,形式象这样的 L.M×BE,那么这个L.M就是所谓的尾数(mantisa).它由一个起始位和一个小数部分组成.举个例子,5可以用科学计数法表示成不同形式:
5*100
0.5*101
50*10-1
那么我们引进一个概念,规范化形式(normalized form)和非规范化形式(denormalized form).我们定义规范化形式为小数点位于第一个不为0的数字后面的表达形式为规范化形式,因此上面的第一种形式为规范化形式,其他的为非规范化形 式,Java中的浮点表示完全按照这个标准,只有两种形式规范化形式:1.f 和 非规范化形式 0.f .
那么,对于我们的位布局来说,选用底数为2的话,只有一个数字是非零的,那就是1.所以我们的隐含起始数字可以不用占用一个位,因为除了0就只能是1,具体的隐含规则,稍后展示.
3.表示的意义.
对应于上面的表格,每一个区域对应的值的范围所表示的浮点数的意义:
符号位s 指数位e 小数位f 所表示的意义v
0 00..00 00..00 +0
0 00..00 00..01
:
11..11 正的非规范实数,计算方法v=0.f × 2(-b+1)
0 00..01
:
11..10 XX..XX 正的规范化实数,计算方法v=1.f × 2(e-b)
0 11..11 00..00 正的无穷大
0 11..11 00..01
:
01..11 无意义的非数字SNAN
0 11..11 10..00
:
11..11 无意义的非数字QNAN
其中b=127(float)/b=1023(double),SNAN表示无效运算结果,QNAN表示不确定的运算结果,都是无意义的.
如果把符号位s改成1,那么就全部都是负数的含义,其他意义和这相同.
另外我们看到,对于无意义的数字是指数部分为全1时,也就是说这里有很多种组合都是无意义的非数字,而我们的Java中,判断一个数字是否是NAN的做法相当简单
static public boolean isNaN(double v) {
return (v != v);
}
从这里可以看出来,虚拟机对于double类型的数据比较时,肯定是先做了指数值的判定,发现不是全1时才作内存的逐位比较.当然这是我得推测,真像不知道是否如此.
再另外,我们'现在十分清楚,double类型所能表示的最小值就是它的值之间的距离,也就是我们所说的精度,数字按这种精度向整数"1阶梯式的累加时, 正好不能和1完全匹配,换句话说,1不是最小值(精度/距离)的整数倍.因此如果你设置变量 double d = 0.1;而结果不会是0.1,因为无法表示0.1;
二.怎么查看double类型的存储结构?
我们很清楚Java的Double类型提供一个函数叫做doubleToLongBits函数,这个函数的其实很简单,我们知道,long类型和 double类型都是64位的,他们的内存大小一样,这个函数的做法就是把double对应的内存结构复制到同样大小的long类型变量的内存结构中.返 回这个long值.因为Java不支持对double类型做位运算,因此:
1.该函数不可能用Java语言完成,所以他是JNI实现
2.我们利用对long类型的位运算可以把该内存结构打印出来查看.
/**
* 测试
*/
public static void main(String[] args){
myTest t = new myTest();
double d = 0.1d;
long l = Double.doubleToLongBits(d);
System.out.println(t.getLongBits(l));
}
/**
* 得到常整数的bit位表示字符串
* @param a
* @return
*/
public String getLongBits(long a){
//8个字节的字节数组,读出来
byte[] b = new byte[8];
for(int i=7;i>=0;i--){
b[i] = (byte)(a&0x000000FF);
a = a>>8;
}
return this.byte2hex(b); //调用下面一个函数
}
/**
* 字节数组转换成字符串
* @param b
* @return
*/
public static String byte2hex(byte[] b){
StringBuffer sb=new StringBuffer();
String stmp="";
for(int n=0;n<b.length;n++){
stmp=(Integer.toHexString(b[n]&0XFF));
if(stmp.length()==1){
//不足两位的末尾补零
sb.append("0"+stmp);
} else{
sb.append(stmp);
}
if(n<b.length-1){
//":"作为分割符
sb.append(":");
}
}
return sb.toString().toUpperCase();
}
0.1打印出来的内存结果是:
3F:B9:99:99:99:99:99:9A
我们恢复一下和第一节的表示意义对照表对照一下:
0 01111111011 1001.....1010
有兴趣的话,可以那科学计算器按照第一节的规则计算一下它的值,哦,正好就是我们通过System.out.println(d)打印的结果.
好了.这就是全部,我不认为我把问题表达的很清楚,因为我的总觉得文字和我的想法还是有一点距离,大概这就是表达能力吧.如果你不至于糊涂,我将很高兴.
java学习之数值型别(int,float,double等)
1. 代码
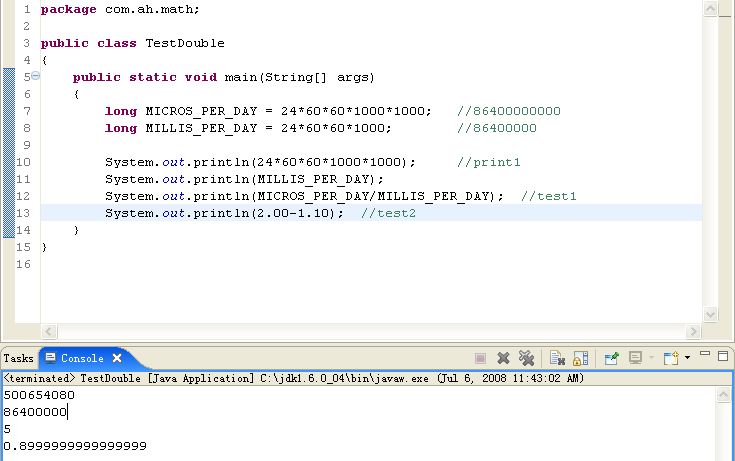
2.Java中数字类型的转换法则
test1中看似除数中的所有的因子都被约掉了,只剩下了1000。但实际的输出却是5,而不是我们期望的1000。究其原因,是因为MICROS_PER_DAY按int类型进行的计算,而计算的结果是86400000000,已经超出了int类型的最大值,即溢出了(因int为32位,2^31-1=2147483647),24*60*60*1000*1000最后的结果是500654080(见程序中的print1的输出)。
在产生了错误的计算结果后,该结果被付给了long型的MICROS_PER_DAY,long型为64位,故保持了这个错误的结果,最终导致了最终结果的错误。
解决该问题的方法是,通过使用long常量来代替int常量作为每一个乘积的第一个因子,这样就可以强制表达式中所有的后续计算都使用long运算来完成,这样就不会丢失精度,即:
long MICROS_PER_DAY= 24L*60*60*1000*1000;
图中的六个实箭头表示了无信息损失的转换,而三个虚箭头表示的转换则可能丢失精度。
3.浮点类型float, double的数据不适合在不容许舍入误差的金融计算领域。
例如上面的test2,我们预期的得到的结果是0.1,但实际的输出却是0.8999999999999999。
这种误差产生的原因是因为浮点数实际上是用二进制系统表示的。而分数1/10在二进制系统中没有精确的表示,其道理就如同在十进制系统中无法精确表示1/3一样。看完下面的第4点就可以明白其中的原因了。
如果需要进行不产生舍入误差的精确数字计算,需要使用BigDecimal类。
4.既然说到了浮点型是使用二进制表示的,那么就再来复习以下这方面的内容。
1)简单介绍下IEEE754标准
Java中的float,double以及其对应的包装类Float和Double,都依据IEEE754标准。
一个实数V在IEEE754标准中可以用V=(-1)s×M×2E的形式表示,说明如下:
(1)符号s (sign)决定实数是正数(s=0)还是负数(s=1),对数值0的符号位特殊处理。
(2)有效数字M是二进制小数,M的取值范围在1≤M<2或0≤M<1。
说明:尾数M用原码表示。
根据原码的规格化方法,最高数字位(整数部分)总是1,该标准将这个1缺省
存储,使得尾数表示范围比实际存储的一位。即M存储的只是小数部分。
(看到后面的例子就会明白啦)
(3)指数E是2的幂,它的作用是对浮点数加权。
说明:由于E是用移码表示,32位的float类型需要加上偏移量127,64位的double
类型要加上偏移量1023
下图即为float(32位)和double(64位)的存储格式:
2)十进制小数与二进制小数的相互转换
例1:二进制转十进制
例2:十进制数转换成二进制数,是把整数部分和小数部分分别转换,整数部分用2除,取余数,小数部分用2乘,取整数位。
如:把(13.125)10转换成二进制数
1)整数部分:13/2 商6 余1
6/2 商3 余0
3/2 商1 余1
1/2 商0 余1
故整数部分为 1101
2)小数部分:
因此,
3) 下面再举几个规范化表示的例子(以float类型为例):
a) 十进制小数1.25
二进制表示为1.01
规范化二进制表示即 *1.01*
符号位:0
指数部分:0+127=127
即01111111
尾数部分:01000000000000000000000
注:尾数部分只存储了小数部分的(0.01),整数部分的1是默认存储的。这正好
验证了4-1)-(2)要说明的问题。
最终结果为 0 0111111101000000000000000000000
b) 十进制小数0.75
二进制表示为0.11
规范化表示即 *1.1*
符号位:0
指数部分:-1+127=126
即01111110
尾数部分:10000000000000000000000
最终结果: 0 0111111010000000000000000000000
c) 十进制-2.5
二进制表示为 -10.1
规范化后为 *1.01*
符号位:1
指数部分:1+127=128
即10000000
尾数部分:01000000000000000000000
最终结果:1 10000000 01000000000000000000000
注:浮点数一般都存在舍入误差,很多数字无法精确表示(例如0.1),其结果只能是接近,
但不等于。一般情况下,分母不是 的情况下,一般都无法精确表示(虽然这种表
述可能不太严谨)。
5.补充知识
IEEE754的四种舍入方向
向最接近的可表示的值;当有两个最接近的可表示的值时首选“偶数”值;向负无穷大(向 下);向正无穷大(向上)以及向0(截断)。
说明:舍入模式也是比较容易引起误解的地方之一。我们最熟悉的是四舍五入模式,但是,IEEE 754标准根本不支持,它的默认模式是最近舍入(Round to Nearest),它与四舍五入只有一点不同,对.5的舍入上,采用取偶数的方式。举例比较如下:
例2:
最近舍入模式:Round(0.5) = 0; Round(1.5) = 2;Round(2.5) = 2;
四舍五入模式:Round(0.5) = 1; Round(1.5) = 2;Round(2.5) = 3;
主要理由:由于字长有限,浮点数能够精确表示的数是有限的,因而也是离散的。在两个可以精确表示的相邻浮点数之间,必定存在无穷多实数是IEEE浮点数所无法精确表示的。如何用浮点数表示这些数,IEEE 754的方法是用距离该实数最近的浮点数来近似表示。但是,对于.5,它到0和1的距离是一样近,偏向谁都不合适,四舍五入模式取1,虽然银行在计算利息时,愿意多给0.5分钱,但是,它并不合理。例如:如果在求和计算中使用四舍五入,一直算下去,误差有可能越来越大。机会均等才公平,也就是向上和向下各占一半才合理,在大量计算中,从统计角度来看,高一位分别是偶数和奇数的概率正好是50% : 50%。至于为什么取偶数而不是奇数,大师Knuth有一个例子说明偶数更好,于是一锤定音。
原码、反码、补码、移码
对于正数,原码和反码,补码都是一样的,都是正数本身。 对于负数,原码是符号位为1,数值部分取X绝对值的二进制。 反码是符号位为1,其它位是原码取反。 补码是符号位为1,其它位是原码取反,未位加1。 也就是说,负数的补码是其反码未位加1。 移码就是将符号位取反的补码。
在计算机中,实际上只有加法运算,减法运算也要转换为加法运算, 乘法转换为加法运算,除法转换为减法运算。
在计算机中,对任意一个带有符号的二进制,都是按其补码的形式进行运算和存储的。 之所以是以补码方式进行处理,而不按原码和反码方式进行处理,是因为在对带有符号位的 原码和反码进行运算时,计算机处理起来有问题。(具体原因见理解原码,反码与补码) 而按补码方式,一方面使符号位能与有效值部分一起参加运算,从而简化运算规则. 另一方面使减法运算转换为加法运算,进一步简化计算机中运算器的线路设计















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









