







目录
一、前言之链表的引入
顺序表的问题及思考 :1. 中间/头部的插入删除,时间复杂度为O(N)2. 增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。3. 增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到200,我们再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。
基于以上的问题,我们可以考虑使用链表的结构来看看。
二、链表的概念及分类
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表
中的指针链接次序实现的 。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。
组成:每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。

注:1、链式结构在逻辑上是连续的,但是在物理上不一定连续。
2、结点一般都是从堆上申请出来的(因为我们要自己开辟空间)。
3、从堆上申请的空间中,两次申请的空间可能连续,也可能不连续。
链表的分类:
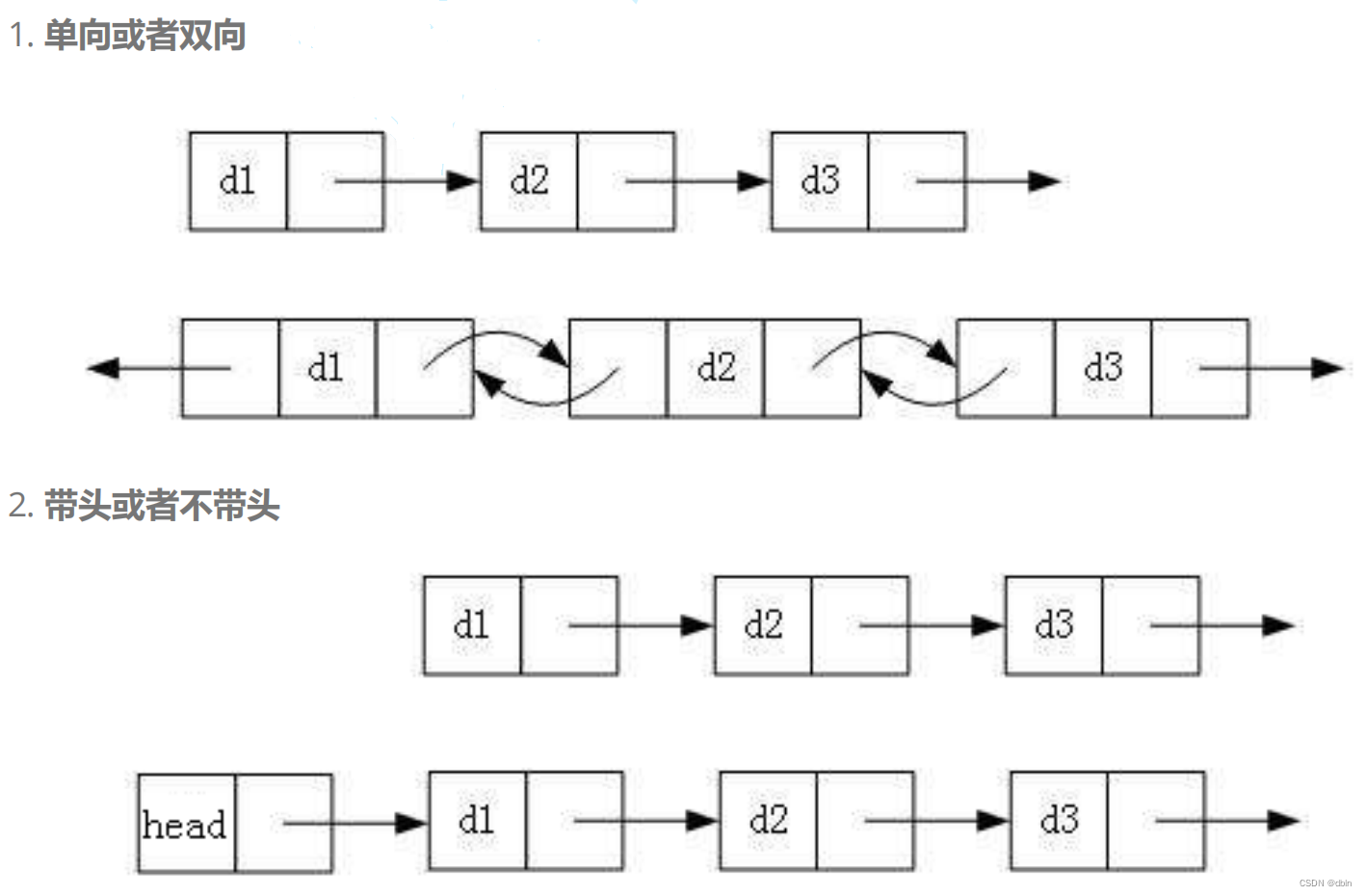
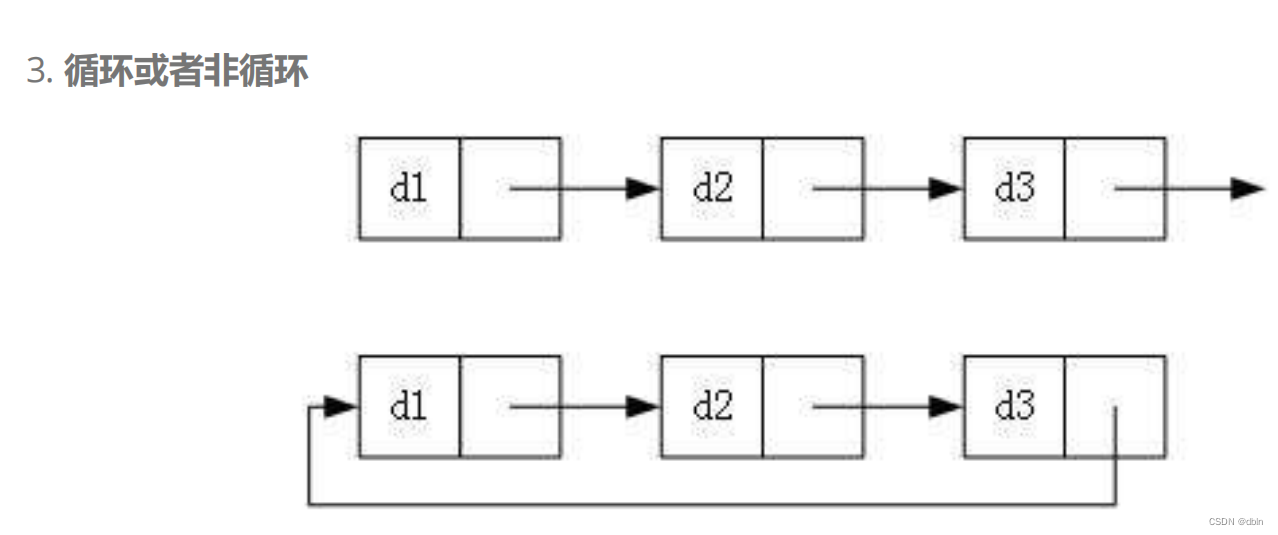
而我们在实际应用中最主要使用的是下面两种结构:
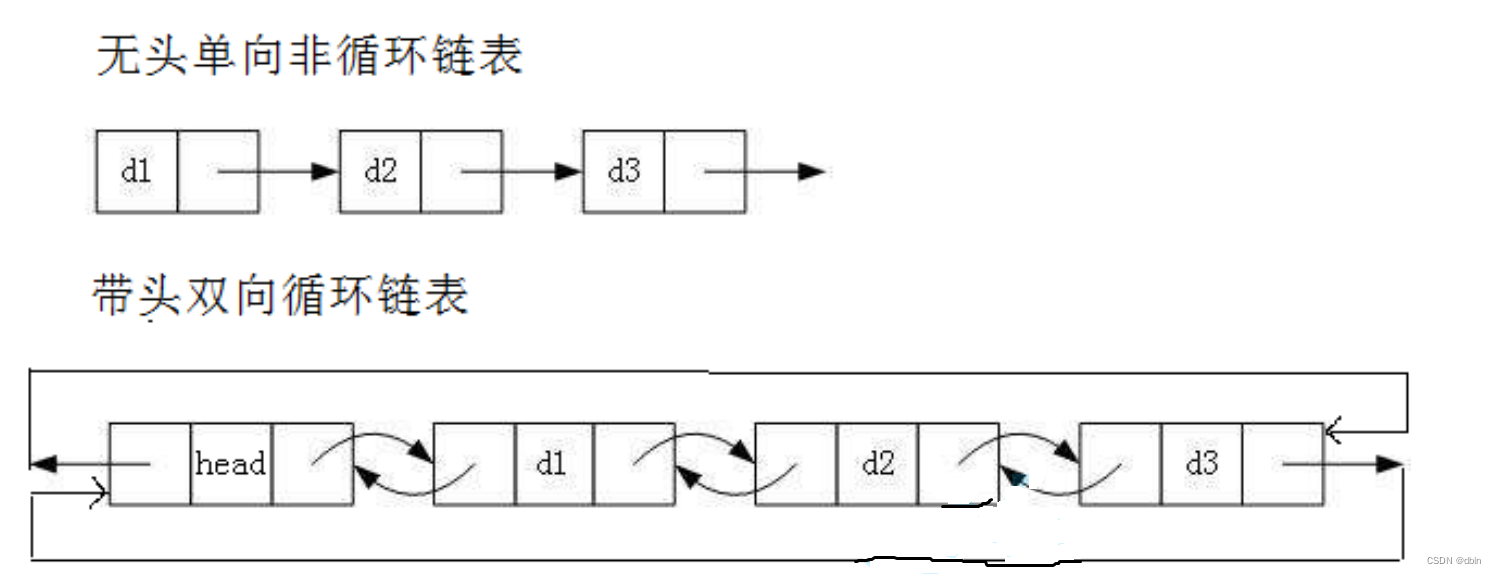
三、无头单向非循环链表的实现
首先我们先要定义一个单向链表
typedef int DataType;
typedef struct SListNode
{
DataType data; //数据域
struct SListNode* next; //指针域
}SL;
接下来我们实现它的一下相关接口函数:
1、创建一个新的结点
//创建一个新的节点
SL* CreatNewNode(DataType x)
{
SL* newnode = (SL*)malloc(sizeof(SL));
if (newnode == NULL)
{
printf("malloc fail");
exit(-1);
}
else
{
newnode->next = NULL;
newnode->data = x;
}
return newnode;
}
2、头插
//头插
void SLPushFront(SL** pphead, DataType x)
{
assert(pphead);
SL* newnode = CreatNewNode(x);
newnode->next = *pphead;
*pphead = newnode;
}3、头删
//头删
void SLPopFront(SL** pphead)
{
assert(pphead);
assert(*pphead);
SL* cur = (*pphead)->next;
free(*pphead);
*pphead = cur;
}4、尾插
//尾插
void SLPushBack(SL** pphead, DataType x)
{
assert(*pphead);
SL* newnode = CreatNewNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
//找尾
else
{
SL* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}5、尾删
//尾删
void SLPopBack(SL** pphead)
{
assert(pphead);
assert(*pphead != NULL);
SL* tail = *pphead;
SL* prev = NULL;
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{//找尾和前一个
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
prev->next = NULL;
free(tail);
tail = NULL;
}
}6、链表的销毁
//销毁
void SLDestroy(SL** pphead)
{
assert(pphead);
SL* cur = *pphead;
while (cur)
{
SL* next = cur->next;
free(cur);
cur = next;
}
*pphead = NULL;
}7、打印函数
//打印
void print(SL* phead)
{
SL* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL");
}8、查找
//查找
SL* SListFind(SL* pphead, DataType x)
{
assert(pphead);
SL* cur = pphead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}9、在任意位置之前插入
//在pos之前插入,需要找前一个
void SListInsert(SL** pphead, SL* pos, DataType x)
{
assert(pphead);
assert(pos);
if (pos == *pphead)
{
SLPushFront(pphead, x);
}
else
{
SL* newnode = CreatNewNode(x);
SL* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
assert(prev);
}
prev->next = newnode;
newnode->next = pos;
}
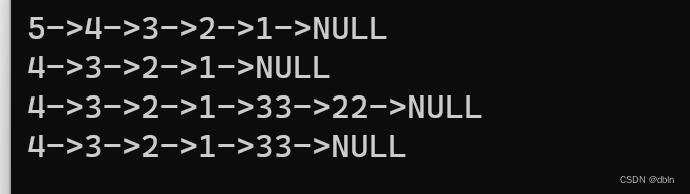
}测试一下我们的单向链表:
void SListTest()
{
SL* plist = NULL;
SLPushFront(&plist, 1);
SLPushFront(&plist, 2);
SLPushFront(&plist, 3);
SLPushFront(&plist, 4);
SLPushFront(&plist, 5);
print(plist);
printf("\n");
SLPopFront(&plist);
print(plist);
printf("\n");
SLPushBack(&plist, 33);
SLPushBack(&plist, 22);
print(plist);
printf("\n");
SLPopBack(&plist);
print(plist);
printf("\n");
}
int main()
{
SListTest();
return 0;
}运行结果:
四、带头双向循环链表的实现
首先我们先要定义一个双向链表
typedef int DLdataType;
typedef struct DListNode
{
DLdataType data;
struct DListNode* next;//后一个
struct DListNode* prev;//前一个
}DL;接下来我们实现它的一下相关接口函数:
1、初始化
//初始化
DL* ListInit()
{
DL* phead = (DL*)malloc(sizeof(DL));
if (phead == NULL)
{
printf("malloc is fail");
exit(-1);
}
phead->next = phead;
phead->prev = phead;
return phead;
}2、打印函数
//打印
void print(DL* phead)
{
assert(phead);
DL* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}3、创建一个新的结点
//创建一个新的节点
DL* CreatNode(DLdataType X)
{
DL* newnode = (DL*)malloc(sizeof(DL));
if (newnode == NULL)
{
printf("malloc is fail");
exit(-1);
}
newnode->data = X;
newnode->prev = NULL;
newnode->next = NULL;
return newnode;
}4、尾插
//尾插
void DLPushBack(DL* phead, DLdataType X)
{
assert(phead);
DL* newnode = CreatNode(X);
DL* tail = phead->prev;
phead->prev = newnode;
tail->next = newnode;
newnode->prev = tail;
newnode->next = phead;
}5、头插
//头插
void DLPushFront(DL* phead, DLdataType X)
{
assert(phead);
DL* newnode = CreatNode(X);
if (phead->next == NULL)
{
phead->next = newnode;
newnode->prev = phead;
newnode->next = phead->prev;
}
else
{
DL* cur = phead->next;
newnode->prev = phead;
newnode->next = cur;
phead->next = newnode;
cur->prev = newnode;
}
}6、头删
//头删
void DLPopFront(DL* phead)
{
assert(phead);
DL* cur = phead->next;
DL* idx = cur->next;
phead->next = idx;
idx->prev = phead;
free(cur);
cur = NULL;
}7、尾删
//尾删
void DLPopBack(DL* phead)
{
assert(phead);
DL* tail = phead->prev;
DL* tailprev = tail->prev;
free(tail);
tailprev->next = phead;
phead->prev = tailprev;
}8、在pos位置之前插入x
void ListInsert(DL* pos, DLdataType x)
{
assert(pos);
DL* prev = pos->prev;
DL* newnode = CreatNode(x);
prev->next = newnode;
newnode->prev = prev;
newnode->next = pos;
pos->prev = newnode;
}9、链表的销毁
void DLDestory(DL* phead)
{
assert(phead);
DL* cur = phead->next;
while (cur != phead)
{
DL* next = cur->next;
free(cur);
cur = next;
}
free(phead);
}下面测试一下我们的双向链表:
void TestList1()
{
DL* plist = ListInit();
DLPushBack(plist, 1);
DLPushBack(plist, 2);
DLPushBack(plist, 3);
DLPushBack(plist, 4);
print(plist);
DLPushFront(plist, 317);
print(plist);
DLPopFront(plist);
print(plist);
DLPopBack(plist);
print(plist);
}
int main()
{
TestList1();
return 0;
}运行结果:

五、总结
链表和顺序表相比,对于空间的利用率更优,插入删除的效率更优,但是顺序表可以通过下标随机访问任意位置的元素,而链表则不能。因此他们各有各的优缺点,我们则需要根据不同的应用场景去使用合适的结构来帮助我们。















 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









