







[算法说明]
堆排序是对简单选择排序的改进
简单选择排序是从n个记录中找出一个最小的记录,需要比较n-1次。但是这样的操作并没有把每一趟的比较结果保存下来,在后一趟的比较中,有许多比较在前一趟已经做过了,但由于前一趟排序时未保存这些比较结果,所以后一趟排序时又重复执行了这些比较操作,因而记录的比较次数较多。
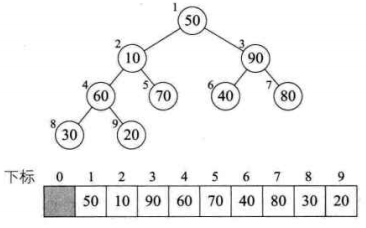
堆是具有下列性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。
[算法思想]
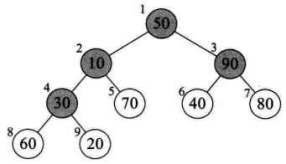
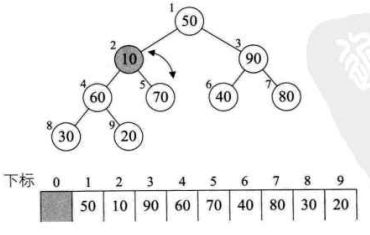
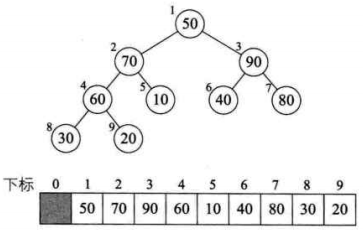
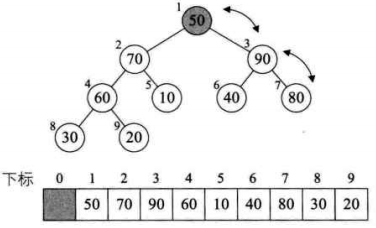
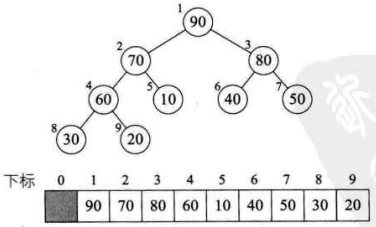
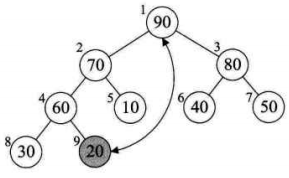
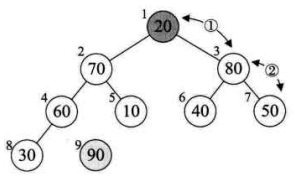
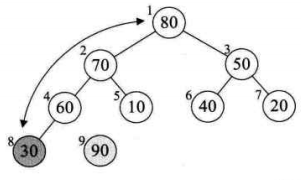
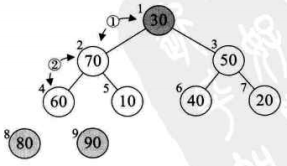
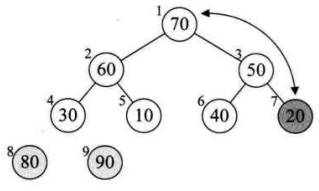
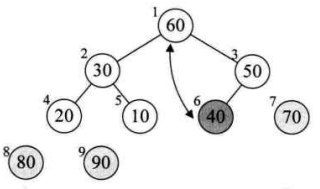
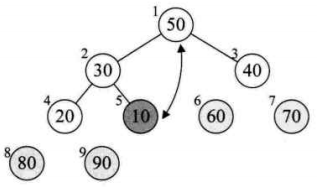
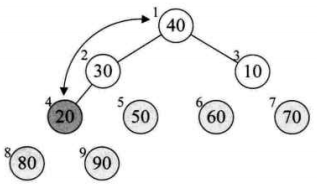
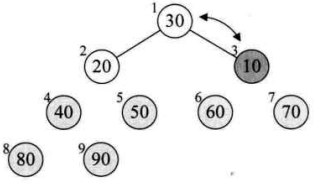
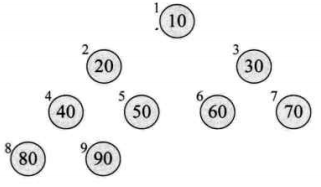
将待排序的序列构造成一个大顶堆。此时,整个序列的最大值就是堆顶的根节点。将它移走(其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值),然后将剩余的n-1个序列重新构造成一个堆,这样就会得到n个元素中的次最大值。如此反复执行,就能得到一个有序序列了。
问题:
1. 如何由一个无序序列构建成一个堆?
2. 如何在输出堆顶元素后,调整剩余元素成为一个新的堆?
[java实现]
public class HeapSort {
public static void main(String[] args) {
int[] arr = { 50, 10, 90, 30, 70, 40, 80, 60, 20 };
System.out.println("排序之前:");
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
// 堆排序
heapSort(arr);
System.out.println();
System.out.println("排序之后:");
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
/**
* 堆排序
*/
private static void heapSort(int[] arr) {
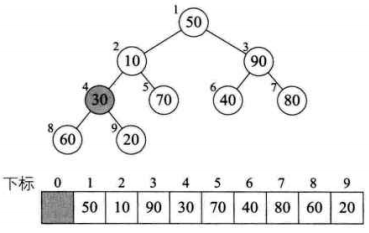
// 将待排序的序列构建成一个大顶堆
for (int i = arr.length / 2; i >= 0; i--){
heapAdjust(arr, i, arr.length);
}
// 逐步将每个最大值的根节点与末尾元素交换,并且再调整二叉树,使其成为大顶堆
for (int i = arr.length - 1; i > 0; i--) {
swap(arr, 0, i); // 将堆顶记录和当前未经排序子序列的最后一个记录交换
heapAdjust(arr, 0, i); // 交换之后,需要重新检查堆是否符合大顶堆,不符合则要调整
}
}
/**
* 构建堆的过程
* @param arr 需要排序的数组
* @param i 需要构建堆的根节点的序号
* @param n 数组的长度
*/
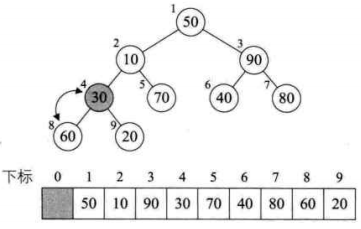
private static void heapAdjust(int[] arr, int i, int n) {
int child;
int father;
for (father = arr[i]; leftChild(i) < n; i = child) {
child = leftChild(i);
// 如果左子树小于右子树,则需要比较右子树和父节点
if (child != n - 1 && arr[child] < arr[child + 1]) {
child++; // 序号增1,指向右子树
}
// 如果父节点小于孩子结点,则需要交换
if (father < arr[child]) {
arr[i] = arr[child];
} else {
break; // 大顶堆结构未被破坏,不需要调整
}
}
arr[i] = father;
}
// 获取到左孩子结点
private static int leftChild(int i) {
return 2 * i + 1;
}
// 交换元素位置
private static void swap(int[] arr, int index1, int index2) {
int tmp = arr[index1];
arr[index1] = arr[index2];
arr[index2] = tmp;
}
}
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
[算法总结]
堆排序时间复杂度:O(nlogn)
堆排序对原始记录的排序状态并不敏感,其在性能上要远远好过于冒泡、简单选择、直接插入排序。















 3420
3420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









