







https://www.cnblogs.com/infaraway/p/8645133.html
前言
特征是数据中抽取出来的对结果预测有用的信息,可以是文本或者数据。特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。过程包含了特征提取、特征构建、特征选择等模块。
特征工程的目的是筛选出更好的特征,获取更好的训练数据。因为好的特征具有更强的灵活性,可以用简单的模型做训练,更可以得到优秀的结果。“工欲善其事,必先利其器”,特征工程可以理解为利其器的过程。互联网公司里大部分复杂的模型都是极少数的数据科学家在做,大多数工程师们做的事情基本是在数据仓库里搬砖,不断地数据清洗,再一个是分析业务不断地找特征。 例如,某广告部门的数据挖掘工程师,2周内可以完成一次特征迭代,一个月左右可以完成模型的小优化,来提升auc。
1. 数据采集 / 清洗 / 采样
数据采集:数据采集前需要明确采集哪些数据,一般的思路为:哪些数据对最后的结果预测有帮助?数据我们能够采集到吗?线上实时计算的时候获取是否快捷?
举例1:我现在要预测用户对商品的下单情况,或者我要给用户做商品推荐,那我需要采集什么信息呢?
-店家:店铺的评分、店铺类别……
-商品:商品评分、购买人数、颜色、材质、领子形状……
-用户:历史信息(购买商品的最低价最高价)、消费能力、商品停留时间……
数据清洗: 数据清洗也是很重要的一步,机器学习算法大多数时候就是一个加工机器,至于最后的产品如何,取决于原材料的好坏。数据清洗就是要去除脏数据,比如某些商品的刷单数据。
那么如何判定脏数据呢?
1) 简单属性判定:一个人身高3米+的人;一个人一个月买了10w的发卡。
2) 组合或统计属性判定:号称在米国却ip一直都是大陆的新闻阅读用户?你要判定一个人是否会买篮球鞋,样本中女性用户85%?
3) 补齐可对应的缺省值:不可信的样本丢掉,缺省值极多的字段考虑不用。
数据采样:采集、清洗过数据以后,正负样本是不均衡的,要进行数据采样。采样的方法有随机采样和分层抽样。但是随机采样会有隐患,因为可能某次随机采样得到的数据很不均匀,更多的是根据特征采用分层抽样。
正负样本不平衡处理办法:
正样本 >> 负样本,且量都挺大 => downsampling
正样本 >> 负样本,量不大 =>
1)采集更多的数据
2)上采样/oversampling(比如图像识别中的镜像和旋转)
3)修改损失函数/loss function (设置样本权重)
2. 特征处理
2.1 数值型
1. 幅度调整/归一化:python中会有一些函数比如preprocessing.MinMaxScaler()将幅度调整到 [0,1] 区间。
2.统计值:包括max, min, mean, std等。python中用pandas库序列化数据后,可以得到数据的统计值。

3.离散化:把连续值转成非线性数据。例如电商会有各种连续的价格表,从0.03到100元,假如以一元钱的间距分割成99个区间,用99维的向量代表每一个价格所处的区间,1.2元和1.6元的向量都是 [0,1,0,…,0]。pd.cut() 可以直接把数据分成若干段。
4.柱状分布:离散化后统计每个区间的个数做柱状图。
2.2 类别型
类别型一般是文本信息,比如颜色是红色、黄色还是蓝色,我们存储数据的时候就需要先处理数据。处理方法有:
1. one-hot编码,编码后得到哑变量。统计这个特征上有多少类,就设置几维的向量,pd.get_dummies()可以进行one-hot编码。
2. Hash编码成词向量:
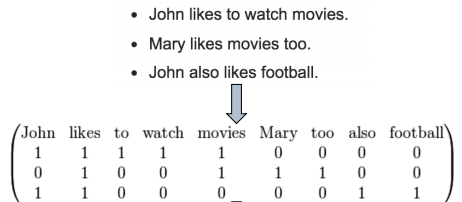
3. Histogram映射:把每一列的特征拿出来,根据target内容做统计,把target中的每个内容对应的百分比填到对应的向量的位置。优点是把两个特征联系起来。
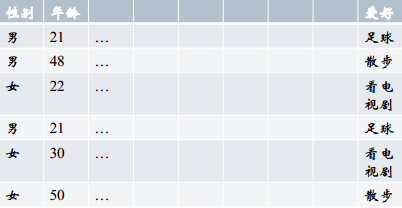
上表中,我们来统计“性别与爱好的关系”,性别有“男”、“女”,爱好有三种,表示成向量 [散步、足球、看电视剧],分别计算男性和女性中每个爱好的比例得到:男[1/3, 2/3, 0],女[0, 1/3, 2/3]。即反映了两个特征的关系。
2.3 时间型
时间型特征的用处特别大,既可以看做连续值(持续时间、间隔时间),也可以看做离散值(星期几、几月份)。
连续值
a) 持续时间(单页浏览时长)
b) 间隔时间(上次购买/点击离现在的时间)
离散值
a) 一天中哪个时间段(hour_0-23)
b) 一周中星期几(week_monday...)
c) 一年中哪个星期
d) 一年中哪个季度
e) 工作日/周末
数据挖掘中经常会用时间作为重要特征,比如电商可以分析节假日和购物的关系,一天中用户喜好的购物时间等。
2.4 文本型
1. 词袋:文本数据预处理后,去掉停用词,剩下的词组成的list,在词库中的映射稀疏向量。Python中用CountVectorizer处理词袋.
2. 把词袋中的词扩充到n-gram:n-gram代表n个词的组合。比如“我喜欢你”、“你喜欢我”这两句话如果用词袋表示的话,分词后包含相同的三个词,组成一样的向量:“我 喜欢 你”。显然两句话不是同一个意思,用n-gram可以解决这个问题。如果用2-gram,那么“我喜欢你”的向量中会加上“我喜欢”和“喜欢你”,“你喜欢我”的向量中会加上“你喜欢”和“喜欢我”。这样就区分开来了。
3. 使用TF-IDF特征:TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF(t) = (词t在当前文中出现次数) / (t在全部文档中出现次数),IDF(t) = ln(总文档数/ 含t的文档数),TF-IDF权重 = TF(t) * IDF(t)。自然语言处理中经常会用到。
2.5 统计型
加减平均:商品价格高于平均价格多少,用户在某个品类下消费超过平均用户多少,用户连续登录天数超过平均多少...
分位线:商品属于售出商品价格的多少分位线处
次序型:排在第几位
比例类:电商中,好/中/差评比例,你已超过全国百分之…的同学
2.6 组合特征
1. 拼接型:简单的组合特征。例如挖掘用户对某种类型的喜爱,对用户和类型做拼接。正负权重,代表喜欢或不喜欢某种类型。
- user_id&&category: 10001&&女裙 10002&&男士牛仔
- user_id&&style: 10001&&蕾丝 10002&&全棉
2. 模型特征组合:
- 用GBDT产出特征组合路径
- 组合特征和原始特征一起放进LR训练
3. 特征选择
特征选择,就是从多个特征中,挑选出一些对结果预测最有用的特征。因为原始的特征中可能会有冗余和噪声。
特征选择和降维有什么区别呢?前者只踢掉原本特征里和结果预测关系不大的, 后者做特征的计算组合构成新特征。
3.1 过滤型
- 方法: 评估单个特征和结果值之间的相关程度, 排序留下Top相关的特征部分。
- 评价方式:Pearson相关系数, 互信息, 距离相关度。
- 缺点:只评估了单个特征对结果的影响,没有考虑到特征之间的关联作用, 可能把有用的关联特征误踢掉。因此工业界使用比较少。
- python包:SelectKBest指定过滤个数、SelectPercentile指定过滤百分比。
3.2 包裹型
- 方法:把特征选择看做一个特征子集搜索问题, 筛选各种特征子集, 用模型评估效果。
- 典型算法:“递归特征删除算法”。
- 应用在逻辑回归的过程:用全量特征跑一个模型;根据线性模型的系数(体现相关性),删掉5-10%的弱特征,观察准确率/auc的变化;逐步进行, 直至准确率/auc出现大的下滑停止。
- python包:RFE
3.3 嵌入型
- 方法:根据模型来分析特征的重要性,最常见的方式为用正则化方式来做特征选择。
- 举例:最早在电商用LR做CTR预估, 在3-5亿维的系数特征上用L1正则化的LR模型。上一篇介绍了L1正则化有截断作用,剩余2-3千万的feature, 意味着其他的feature重要度不够。
- python包:feature_selection.SelectFromModel选出权重不为0的特征。
《注:以上总结来自于七月在线课程》

















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









