







指针就是指针,指针变量在32 位系统下,永远占4 个byte ,其值为某一个内存的地址。指针可以指向任何地方,但是不是任何地方你都能通过这个指针变量访问到。
数组就是数组,其大小与元素的类型和个数有关。定义数组时必须指定其元素的类型和个数。数组可以存任何类型的数据,但不能存函数。
数组的本质:
数组是一段连续的内存空间
数组的空间大小为 sizeof(array_type) * array_size
数组名可看做指向数组第一个元素的常量指针,其值不能改变
指针的运算:
指针本质是变量,保存的值被看做内存中的地址
指针是一种特殊的变量,与整数的运算规则为
p + n; <--> (unsigned int)p + n*sizeof(*p);
当指针p指向一个同类型的数组元素时:p+1将指向当前元素的下一个元素;p-1将指向当前元素的上一个元素。
指针之间只支持减法运算,且必须参与运算的指针类型必须相同
p1 - p2; <--> ( (unsigned int)p1 - (unsigned int)p2) / sizeof(type);
注意:
只有当两个指针指向同一个数组中的元素时,指针相减才有意义,其意义为指针所指元素的下标查
当两个指针指向的元素不在同一个数组中时,结果未定义
此处未定义含义:
1、当两个指针分别指向栈空间和对空间上的数组,则这两个指针相减无意义
2、如同下例1,虽然两个指针指向的数组都在栈上,但是p0 - p2的值是由于内存对齐后相减得到的,也无意义
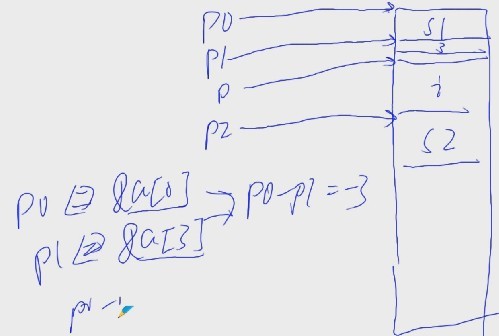
例1:
char s1[] = {'H', 'e', 'l', 'l', 'o'};
int i = 0;
char s2[] = {'W', 'o', 'r', 'l', 'd'};
char* p0 = s1;
char* p1 = &s1[3];
char* p2 = s2;
int* p = &i;
printf("%d\n", p0 - p1); //输出-3
printf("%d\n", ((unsigned int)p0 - (unsigned int)p1) / sizeof(char)); //输出-3,等价于上一句
printf("%d\n", p0 + p2); //编译报错
printf("%d\n", p0 - p2); //输出-12,无意义
printf("%d\n", p0 - p); //编译报错
printf("%d\n", p0 * p2); //编译报错
printf("%d\n", p0 / p2); //编译报错




指针的比较:
指针也可以进行关系运算 < <= > >=
指针关系运算的前提是同时指向同一个数组中的元素
任意两个指针之间的比较运算(==,!=)无限制
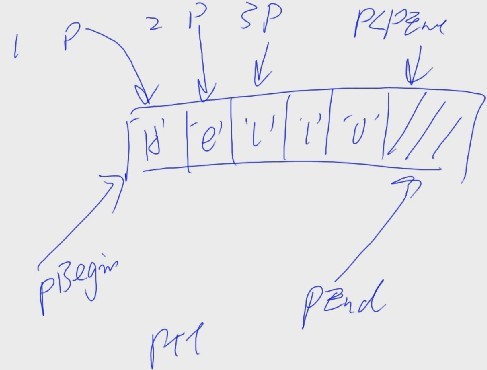
例2:
#define DIM(a) (sizeof(a) / sizeof(*a))
int main()
{
char s[] = {'H', 'e', 'l', 'l', 'o'};
char* pBegin = s;
char* pEnd = s + DIM(s);
char* p = NULL;
for(p=pBegin; p<pEnd; p++) //编译数组,用的指针比较,判断是不是结束
{
printf("%c", *p);
}
printf("\n");
return 0;
}
——以下摘自 陈正冲《C语言深度剖析》
以指针的形式访问 和 以下标的形式访问 指针
char* p = "abcdef";
定义了一个指针变量p ,p本身在栈上占4 个byte ,p里存储的是一块内存的首地址。这块内存在常量区,其空间大小为7 个byte ,这块内存也没有名字。对这块内存的访问完全是匿名的访问。比如现在需要读取字符‘e ’,我们有两种方式:
1)以指针的形式:*(p+4)。先取出p 里存储的地址值,假设为0x0000FF00,然后加上4 个字符的偏移量,得到新的地址0x0000FF04 。然后取出0x0000FF04 地址上的值。
2)以下标的形式:p[4] 。编译器总是把以下标的形式的操作解析为以指针的形式的操作。p[4]这个操作会被解析成:先取出p 里存储的地址值,然后加上中括号中4 个元素的偏 移量,计算出新的地址,然后从新的地址中取出值。也就是说以下标的形式访问在本质上 与以指针的形式访问没有区别,只是写法上不同罢了。
以指针的形式访问 和 以下标的形式访问 数组
char a[] = "123456";
定义了一个数组a,a拥有7 个char 类型的元素,其空间大小为7 。数组a 本身在栈上面。对a 的元素的访问必须先根据数组的名字a 找到数组首元素的首地址,然后根据偏移量找到相应的值。这是一种典型的“具名+匿名”访问。比如现在需要读取字符‘5 ’,我们有两种方式:
1)以指针的形式:*(a+4)。a 这时候代表的是数组首元素的首地址,假设为0x0000FF00,然后加上4 个字符的偏移量,得到新的地址0x0000FF04 。然后取出0x0000FF04 地址上的值。
2)以下标的形式:a[4] 。编译器总是把以下标的形式的操作解析为以指针的形式的操作。a[4]这个操作会被解析成:a 作为数组首元素的首地址,然后加上中括号中4 个元素的偏移量,计算出新的地址,然后从新的地址中取出值。
由上面的分析,我们可以看到,指针和数组根本就是两个完全不一样的东西。只是它们都可以“以指针形式”或“以下标形式”进行访问。一个是完全的匿名访问,一个是典型的具名+匿名访问。一定要注意的是这个“以XXX 的形式的访问”这种表达方式。
另外一个需要强调的是:上面所说的偏移量4 代表的是4 个元素,而不是4 个byte 。只不过这里刚好是char 类型数据 1 个字符的大小就为1 个byte 。记住这个偏移量的单位是元素的个数而不是byte 数,在计算新地址时千万别弄错了。
下标 VS 指针
从理论上而言,当指针以固定增量在数组中移动时,其效率高于下标产生的代码
当指针增量为1且硬件具有硬件增量模型(硬件加速)时,表现更佳
注意:现代编译器的生成代码优化率已大大提高,在固定增量时,下标形式的效率已经和指针形式相当;但从可读性和代码维护角度来看,下标形式更优。
int a[10000];
int b[10000];
int* pEnd = &a[10000];
int* pa = NULL;
int* pb = NULL;
for(k=0; k<10000; k++)
{
for(i=0; i<10000; i++)
{
b[i] = a[i];
}
}
for(k=0; k<10000; k++)
{
for(pa=a, pb=b; pa<pEnd;)
{
*pb++ = *pa++;
}
}
从运行结果来看,指针赋值方式比下标更省时。因为下标形式会多做两次乘法操作,所以更加耗时。

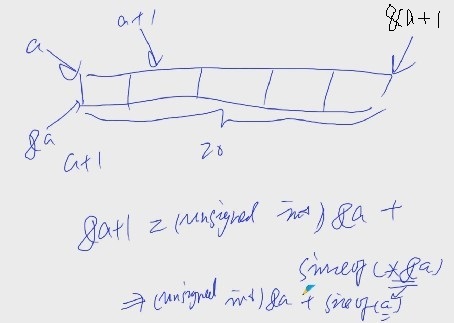
a和&a的区别
a为数组是数组首元素的地址
&a为整个数组的地址
a和&a的意义不同其区别在于指针运算
a + 1 ==> (unsigned int)a + sizeof(*a)
&a + 1 ==> (unsigned int)(&a) + sizeof(*&a)
例3:
int main()
{
int a[5] = {1, 2, 3, 4, 5};
int* p1 = (int*)(&a + 1); //p1[-1] <==> a[4] = 5
int* p2 = (int*)((int)a + 1); //p2[0] <==> 0x02000000 十进制为33554432
int* p3 = (int*)(a + 1); //p3[1] <==> a[2] = 3
printf("%d, %d, %d\n", p1[-1], p2[0], p3[1]);
return 0;
}
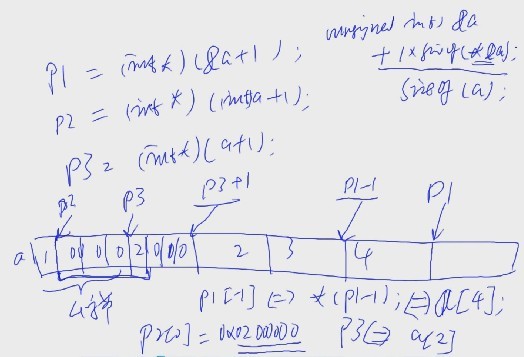
编译运行

数组参数
C语言中,数组作为函数参数时,编译器将其编译成为对应的指针
void f(int a[]); <--> void f(int* a);
void f(int a[5]); <--> void f(int* a);
但丢失了长度信息,所以一般情况下,当定义的函数中有数组参数时,需要定义另一个参数来标示数组的大小。
例4:
void f(int a[1000]) //会退化为void f(int* a)
{
printf("%d\n", sizeof(a));
}
int main()
{
int a[5] = {0};
f(a);
return 0;
}
编译运行,没报错
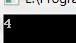
所以在作为函数参数时,数组参数和指针参数等价















 364
364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









