






前一段时间需要利用某个学校的教务网的数据来构建一个web应用,后台使用Java。
本来这应该是一个很简单的任务,只需要利用JSoup写好爬虫就可以了,但没想到打开教务网之后发现每次都需要输入验证码,那么一方面为了简化用户操作另一方面也为了练手,我决定识别这个验证码来实现无验证码登录。
能这样做的主要原因是它的验证码长得还是比较规整的,基本上是这个样子:

但还是不够规整,不能直接用图像处理然后匹配来做,如果长这个样子完全可以匹配像素点然后来识别数字的:
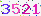
当时正好在学tensorflow,于是我决定利用tensorflow训练一个简单的NN模型来对验证码进行识别(当时本来想着如果效果不好就改CNN,没想到简单的NN就已经有90多的正确率了),然后再把模型放到Java的爬虫上作为登录的工具。
1.训练模型
1.1.数据获取
由于没有现成的数据集,所以我自己用python写了一个爬虫爬了1000张的验证码图片作为训练数据集:
import requests
from PIL import Image
import time
def getOnePic(code):
r=requests.get('http://xx.xx.xx.xx/CheckCode.aspx') #获取验证码页面
f=open('./oriPic/'+code+'.gif','wb') #打开文件
f.write(r.content) #写出图片
f.close() #关闭文件
time.sleep(1) #休眠一段时间防止频率过高爆炸
for i in range(1001): #获取1000张图片
getOnePic(str(i))
执行完成之后,我就已经拥有了比较多的数据可以用于训练了:

1.2.数据处理
按照以往的经验,把图片黑白化之后,会使得识别效果更好,此外这个验证码每个字符所处的位置还是比较规整的,可以将字符切分之后分别识别,如果不切分的话这个数据量应该是不够的,因为四个字符输出会有 3 6 4 36^{4} 364种可能。
1.2.1.工具文件实现
from PIL import Image
import numpy as np
# 阅读标签列表
def readList(filename):
li=[]
with open(filename,'r') as fp: # 打开文件
for l in fp: # 遍历每一行
strs=l.split(',')
for w in strs[:-1]:
li.append(w)
return li
# 打开图片文件为图片或数组
def openPic(filename,arr=False):
return np.array(Image.open(filename)) if arr else Image.open(filename)
#打印一个数组
def printArray(arr,spl=False):
for i in arr:
count=-1
for j in i:
count+=1
#if(count%5==0 and count!=0):
# print('\033[50m ',end='')
if(spl and (count==13 or count==26 or count==39)):
print('\033[40m ',end='')
print('\033[42mx' if j>=128 else '\033[46mx',end='')
print()
# 获取分割后的子图
def getSplitPic(pic):
res=[]
for i in range(4): # 共四个子图
res.append(pic.crop((3+i*12,0,3+(i+1)*12,20)))
return res
# 判断一个像素点是否为黑色
def isBlack(dot):
return dot<128
# 清除孤立点
# f=0 上 1 左 2 下 3 右
def check_neiber(arr,y,x,f,w):
if w==0: # 如果超过了最大栈 撤回
return False # 不是要清除的点
if x>0 and isBlack(arr[y][x-1]) and f!=1: # 如果在左边发现黑点并且不来自左边
if not check_neiber(arr,y,x-1,3,w-1): # 递归检查左边,如果不需要清除
return False # 返回
if x<len(arr[0])-1 and isBlack(arr[y][x+1]) and f!=3: # 检查右边
if not check_neiber(arr,y,x+1,1,w-1):
return False
if y>0 and isBlack(arr[y-1][x]) and f!=0: # 检查上边
if not check_neiber(arr,y-1,x,2,w-1): # 表示从下边过来的
return False
if y<len(arr)-1 and isBlack(arr[y+1][x]) and f!=2: # 检查下边
if not check_neiber(arr,y+1,x,0,w-1):
return False
arr[y][x]=255 # 清除
return True
# 黑白化并去噪
def clearPic(arr):
for i in range(len(arr)):
for j in range(len(arr[0])):
arr[i][j]=0 if arr[i][j]<128 else 255 # 首先设置黑白点
if isBlack(arr[i][j]): # 如果是黑点
check_neiber(arr,i,j,-1,2) # 处理噪音
1.2.2.黑白化并分割字符
import sys
sys.path.append("../")
import tool
import numpy as np
from PIL import Image
import readData
#获取处理之后的子数组
def handlePicToPics(pic):
pic=np.array(pic.crop((4,0,56,20)))
tool.clearPic(pic) #黑白化并去噪
#tool.printArray(pic) #打印看看
pic=Image.fromarray(pic) #获取图片
pics=tool.getSplitPic(pic) #获取分割后的子图
arrays=[]
for i in range(4):
arrays.append(pics[i]) #添加一个数组
return arrays#返回子数组
def regCheckCode(pic):
arrays=handlePicToArrays(pic)
for array in arrays:
readData.printOneData(array)
return getCheckCode(arrays)
def saveLetter(code,pics):
for j in range(4):
pics[j].save('./letter/'+str(code)+str(j)+'.jpg')
if __name__=='__main__':
NUM=6
for i in range(NUM): #处理图片的循环
pic=tool.openPic('./oriPic/%d.gif'%i)
pics=handlePicToPics(pic)
saveLetter(i,pics) #保存图片
分割后可以在letter文件夹下找到分割、黑白化后的字母图片,命名方式是图片代号+(0~3)。

1.2.3.手工标注数据
这也是整个过程中最复杂的过程了,不过也只是相对而言的,这里人工识别分割出来的字母比较困难,所以我决定直接用原图来进行标注,每标注十张就向目标文件中输出一次,防止中途出现异常导致前功尽弃。
import sys
sys.path.append("../")
import tool
PATH='./oriPic/'
NUM=1000
#处理图片%ids%
def handlePic(url):
pic=tool.openPic(url,True)
tool.clearPic(pic)
tool.printArray(pic)
return input('请输入人工识别结果:')
def writeToFile(li,start,end,filename):
with open(filename,'a+') as fp:
for i in range(start,end):
fp.write(li[i]+',')
fp.write('\n')
if __name__=='__main__':
li=[]
for i in range(NUM): #处理1000张图片
li.append(handlePic(PATH+str(i)+'.gif'))
if i!=0 and i%10==0:
writeToFile(li,i-10,i,'data.txt')
print('文件已写出')
if NUM % 10 !=0: #如果不是10的倍数
writeToFile(li,NUM-NUM%10,NUM,'data.txt')
print('文件已写出')
标注之后会在目录下出现data.txt,也就是刚才标注的标签。

标注时参考的图片会在终端这样打印出来,这里使用了\033来打印出不同的颜色方便识别,如果是windows下可以考虑修改打印的代码。

1.3.模型训练
1.3.1.读取数据
由于模型输入是一维的,所以这里需要把字母图片拉成一个长条,也就是一个一维的列表。此外还需要根据标签文件的格式来读取标签。
import tool
#处理一条数据,拉长图片到一维
def handleOneData(pic):
resLi=[]
for col in pic:#遍历每一列
for row in col:
resLi.append(0 if row<128 else 1);
return resLi #返回扩展结果
#读取数据
def readData(num,path):
datList=[] #数据列表
for i in range(num):
for j in range(4):
pic=tool.openPic(path+str(i+1)+str(j)+'.jpg',True) ; #读入图片数组
datList.append(handleOneData(pic)) #处理并添加
return datList
#读取标签
def readLabel(filename):
labList=[] #结果列表
li=tool.readList(filename)[1:] #读取列表
for w in li: #遍历每一个词
for l in w: #遍历每一个字母
ele=[0 for i in range(36)]
if l.isdigit(): #如果是数字
ele[ord(l)-48]=1
else: #如果不是数字
ele[ord(l)-87]=1
labList.append(ele)
return labList
#打印一个测试数据
def printOneData(data):
for i in range(20):
for j in range(12):
print('\033[37m1' if data[i*12+j]==1 else '\033[30m0',end='')
print('\033[39m\033[49m')
1.3.2.训练模型并保存模型
这个模型是按照MNIST数据集上的一个例子来改的,这里每个字符图片的分辨率是12*20,输出有36种可能。
import tensorflow as tf
from datetime import datetime
import readData
import os
import random
#MNIST数据集相关的常数集
INPUT_NODE=240 #输入层的节点数 12*20=240
OUTPUT_NODE=36 #输出层的节点数 36
#配置神经网络的参数
LAYER1_NODE=500 #隐藏层节点数,这里用只有一个隐藏层的网络结构作为样例
BATCH_SIZE=100 #一个训练batch中的训练个数。数字越小时,训练过程越接近随机梯度下降;数字越大时,训练越接近梯度下降
LEARNING_RATE=0.01 #学习率
REGULARIZATION_RATE=0.0001 #描述模型复杂度的正则化项在损失函数中的系数
TRAINING_STEPS=30000 #训练轮数
def train(data,label):
x=tf.placeholder(tf.float32,[None,INPUT_NODE],name='x-input')
y_=tf.placeholder(tf.float32,[None,OUTPUT_NODE],name='y-input')
#生成隐藏层的参数
weights1=tf.Variable(tf.truncated_normal((INPUT_NODE,LAYER1_NODE),stddev=0.1)) #正态分布
biases1=tf.Variable(tf.constant(0.1,shape=[LAYER1_NODE]))
#生成输出层的参数
weights2=tf.Variable(tf.truncated_normal((LAYER1_NODE,OUTPUT_NODE),stddev=0.1))
biases2=tf.Variable(tf.constant(0.1,shape=[OUTPUT_NODE]))
#计算当前参数下的神经网络前向传播的结果
#y=inference(x,weights1,biases1,weights2,biases2)
#layer1=tf.add(tf.nn.relu(tf.matmul(x,weights1),biases1),name='add1') #计算隐藏层的前向传播结果
#y=tf.add(tf.matmul(layer1,weights2),biases2,name='add2') #计算输出层的前向传播结果
y=tf.add(tf.matmul(tf.nn.relu(tf.matmul(x,weights1)+biases1),weights2),biases2,name='predict')
#训练轮数
global_step=tf.Variable(0,trainable=False)
#计算交叉熵作为刻画预测值和真实值之间差距的损失函数。第一个参数是神经网络不包括softmax层的前向传播结果,第二个是训练数据的正确答案
cross_entropy=tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1))
#计算在当前batch中所有样例的交叉熵平均值
cross_entropy_mean=tf.reduce_mean(cross_entropy)
#计算L2正则化损失函数
regularizer=tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
#计算模型的正则化损失
regularization=regularizer(weights1)+regularizer(weights2)
#总损失等于交叉熵和正则化损失的和
loss=cross_entropy_mean+regularization
#设置指数衰减的学习率
#使用优化算法来优化损失函数
train_step=tf.train.AdamOptimizer(LEARNING_RATE).minimize(loss,global_step=global_step)
#检验了神经网络前向传播结果是否正确
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
#首先将一个布尔型的数值转换为实数型,然后计算平均值
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#saver=tf.train.Saver()#用于保存模型
#初始化会话并开始训练过程
with tf.Session() as sess:
tf.global_variables_initializer().run()
#准备验证数据
validate_feed={x:data[2000:3000],y_:label[2000:3000]}
#准备测试数据
test_feed={x:data[3000:],y_:label[3000:]}
start=datetime.now() #训练开始
print('start is %s'%start)
#迭代的训练神经网络
for i in range(TRAINING_STEPS):
#每1000轮输出一次在验证数据集上的测试结果
if i%1000 ==0:
validate_acc=sess.run(accuracy,feed_dict=validate_feed)
print('After %d training steps,validation accuracy is %g'%(i,validate_acc))
startId=random.randint(0,1900);
#产生这一轮使用的一个batch的训练数据,并运行训练过程
xs=data[startId:startId+100]
ys=label[startId:startId+100]
sess.run(train_step,feed_dict={x:xs,y_:ys})
#在训练结束之后,在测试数据上检测神经网络模型的最终正确率
test_acc=sess.run(accuracy,feed_dict=test_feed)
end=datetime.now() #训练结束
print('elapse time %s'%(end-start))
print('After %d training steps,test accuracy is %g'%(TRAINING_STEPS,test_acc))
# 保存模型
frozen_graph_def = tf.graph_util.convert_variables_to_constants(sess,sess.graph_def,output_node_names=["predict"])
with open('model.pb', 'wb') as f:
f.write(frozen_graph_def.SerializeToString())
#主程序入口
def main(argv=None):
#声明处理MNIST数据集的类
data=readData.readData(1000,'letter/')
label=readData.readLabel('data.txt')
train(data,label)
if __name__=='__main__':
tf.app.run()
训练完成之后,在目录下会生成model.pb,也就是训练好的模型。
2.调用模型
这里使用了Maven来简化jar包导入过程。
2.1.导入依赖
<!-- tensorflow所用jar包-->
<dependency>
<groupId>org.tensorflow</groupId>
<artifactId>tensorflow</artifactId>
<version>1.5.0</version>
</dependency>
2.2.完成图片处理工具类
根据之前的python工具来改写java版本的图片处理工具类
HandlePic.java:
package com.zekdot.lancai.login.tool;
import javax.imageio.ImageIO;
import javax.imageio.ImageWriter;
import javax.imageio.stream.ImageOutputStream;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.net.URLDecoder;
import java.util.Iterator;
/** 对图片进行处理
*
* @author zekdot
*/
public class HandlePic {
private static int BLACK=0x00000000;
private static int WHITE=0xffffffff;
/**
* 将一个像素点转为白色或者黑色。
*
* @param pixel
* @return 转换后的像素点(黑/白)
*/
private static int pixelConvert(int pixel) {
int result = 0;
//获取R/G/B
int r = (pixel >> 16) & 0xff;
int g = (pixel >> 8) & 0xff;
int b = (pixel) & 0xff;
//默认黑色
result = BLACK;
int tmp = r * r + g * g + b * b;
if (tmp > 3 * 128 * 128) {
//白色,全F
result = WHITE;
}
return result;
}
/** 过滤其中一个点的周边的噪音
*
* @param image 图片
* @param x 横坐标
* @param y 纵坐标
* @param f 方向
* @param w 栈深度
*/
private static boolean filterOneDot(BufferedImage image,int x,int y,int f,int w){
if(w==0) return false; //如果超过了最大栈,返回
if(x>0 && image.getRGB(x-1,y)==BLACK && f!=1){
if(!filterOneDot(image,x-1,y,3,w-1)) return false;
}
if(x<image.getWidth()-1 && image.getRGB(x+1,y)==BLACK && f!=3){
if(!filterOneDot(image,x+1,y,1,w-1)) return false;
}
if(y>0 && image.getRGB(x,y-1)==BLACK && f!=0){
if(!filterOneDot(image,x,y-1,2,w-1)) return false;
}
if(y<image.getHeight()-1 && image.getRGB(x,y+1)==BLACK && f!=2){
if(!filterOneDot(image,x,y+1,0,w-1)) return false;
}
image.setRGB(x,y,WHITE);
return true;
}
/**过滤噪音
*
* @param image
*/
private static void dotFilter(BufferedImage image){
for(int i=0;i<image.getHeight();i++){
for(int j=0;j<image.getWidth();j++){
//逐点过滤,这里需要调用一个递归的方式来进行真正的过滤操作
if(image.getRGB(j,i)==BLACK){
filterOneDot(image,j,i,-1,2);
}
}
}
}
/**黑白化处理
*
* @param image
*/
private static void whiteAndBlack(BufferedImage image){
for(int i=0;i<image.getHeight();i++){
for(int j=0;j<image.getWidth();j++){
image.setRGB(j,i,pixelConvert(image.getRGB(j,i)));
}
}
}
/**获得黑白化并且切割、去噪后的子图
*
* @param image
*/
private static BufferedImage[] getSubImages(BufferedImage image){
whiteAndBlack(image); //黑白化图片
dotFilter(image); //去噪
image=image.getSubimage(4,0,52,20);
BufferedImage[] images=new BufferedImage[4];
for(int i=0;i<4;i++){
images[i]=image.getSubimage(3+i*12,0,12,20);
}
return images;
}
/**根据图片得到一维数组
*
* @param image
* @return
*/
private static float[] getArrayByPic(BufferedImage image){
float res[]=new float[240];
for(int i=0;i<image.getHeight();i++){
for(int j=0;j<image.getWidth();j++){
res[i*12+j]=image.getRGB(j,i)==BLACK?0:1;
}
}
return res;
}
/** 根据图片得到对应的二维数组
*
* @param image
* @return
*/
public static float[][] getArraysByPic(BufferedImage image){
float res[][]=new float[4][120];
BufferedImage[] images=getSubImages(image); //分割数组
for(int i=0;i<4;i++){ //四次
res[i]=getArrayByPic(images[i]); //放入一个数组
}
return res;
}
/**打印图片数组
*
* @param image
*/
public static void printPicArray(BufferedImage image){
for(int i=0;i<image.getHeight();i++){
for(int j=0;j<image.getWidth();j++){
System.out.printf("%2d ",image.getRGB(j,i));
}
System.out.println();
}
}
/**
* 将图片写入磁盘文件
*
* @param imgFile 文件路径
* @param bi BufferedImage 对象
* @return 无
*/
public static void writeImageToFile(String imgFile, BufferedImage bi) {
// 写图片到磁盘上
Iterator<ImageWriter> writers = ImageIO.getImageWritersByFormatName(imgFile
.substring(imgFile.lastIndexOf('.') + 1));
ImageWriter writer = (ImageWriter) writers.next();
// 设置输出源
File f = new File(imgFile);
ImageOutputStream ios;
try {
ios = ImageIO.createImageOutputStream(f);
writer.setOutput(ios);
// 写入到磁盘
writer.write(bi);
ios.close();
} catch (Exception e) {
}
}
/**
* 从磁盘上获取图片
* @param path
* @return
*/
public static BufferedImage getImage(String path) {
BufferedImage image = null;
try {
image = ImageIO.read(new File(path));
} catch (IOException e) {
e.printStackTrace();
}
return image;
}
}
2.3.创建识别工具类
首先需要把之前训练好的model.pb文件放到指定的文件目录下,然后在代码中指明目录来读取模型文件。
VerifyCode.java:
package com.zekdot.lancai.login.tool;
import org.apache.commons.io.IOUtils;
import org.tensorflow.Graph;
import org.tensorflow.Session;
import org.tensorflow.Tensor;
import java.awt.image.BufferedImage;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URLDecoder;
import java.nio.FloatBuffer;
/**对验证码进行识别
*
* @author zekdot
*/
public class VerifyCode {
private static char RES_CHAR[]; //可能的结果
static{
RES_CHAR=new char[36];//有36中可能结果
for(int i=0;i<10;i++){
RES_CHAR[i]= (char) (48+i); //数字
}
for(int i=10;i<36;i++){
RES_CHAR[i]= (char) (i+87); //字母
}
}
/**根据输入获取输出
*
* @param input 图像数组
* @return 图像对应的字符
*/
public static char verifyOneCheckCode(float[] input){
try{
String path;//
path="/home/zekdot/xxxx/model/";//获取模型所在文件夹
Graph graph = new Graph(); //新建一个计算图
//导入图
byte[] graphBytes = IOUtils.toByteArray(new
FileInputStream(path+"model.pb"));
graph.importGraphDef(graphBytes);
FloatBuffer floatBuffer=FloatBuffer.allocate(240); //申请一个240个double的空间
long shape[]={1,240}; //新建维度数组
floatBuffer.put(input,0,240); //将数据放入数组
floatBuffer.position(0); //修改指针为开头
Tensor<Float> tensor=Tensor.create(shape,floatBuffer); //创建一个张量
//根据图建立Session
Session session = new Session(graph); //新建一个会话
Tensor<Float> result= (Tensor<Float>) session.runner().feed("x-input",tensor).fetch("predict").run().get(0); //传入测试张量算出结果
floatBuffer.position(0); //设置当前指针为开头
result.writeTo(floatBuffer); //写入到缓存区
floatBuffer.position(0); //设置指针为开头
float res[]=new float[36]; //申请一个结果数组
floatBuffer.get(res,0,36); //将张量数据写入结果数组
int index=0;//索引
float pos=res[0];//可能性
for(int i=1;i<res.length;i++){
if(res[i]>pos){ //如果发现了更大的可能性
pos=res[i];
index=i;
}
}
session.close(); //关闭会话
tensor.close();;//关闭张量
return RES_CHAR[index];//返回可能字符
}catch (Exception e){
e.printStackTrace();
}
return 0;
}
/** 根据图片识别内容
*
* @param image 图片
* @return 图片对应的四个字符的字符串
*/
public static String verifyCheckCode(BufferedImage image){
StringBuffer buffer=new StringBuffer();
float arrays[][]= HandlePic.getArraysByPic(image);
for(int i=0;i<4;i++){
buffer.append(verifyOneCheckCode(arrays[i]));
}
return buffer.toString();
}
}
2.4.测试识别效果
这里我从教务网的验证码上随便保存了一张,然后放在了项目下的resources文件夹中:
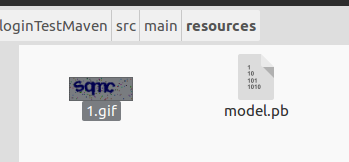
然后在VerifyCode.java中增加主方法:
public static void main(String[] args) throws IOException {
System.out.println(verifyCheckCode(HandlePic.getImage(URLDecoder.decode(HandlePic.class.getResource("/").getPath(),"UTF8")+"1.gif")));
}
读取1.gif并进行识别,然后可以得到识别结果:
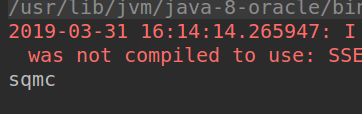
可见识别正确。
识别的组件完成之后就可以进一步跟登录的爬虫结合然后实现业务逻辑了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









