







 本文详细阐述了机器学习中标准化/归一化的概念、目的及其应用场景,对比了几种常用的归一化方法,并讨论了它们在不同算法中的应用效果。
本文详细阐述了机器学习中标准化/归一化的概念、目的及其应用场景,对比了几种常用的归一化方法,并讨论了它们在不同算法中的应用效果。
机器学习——标准化/归一化的目的、作用和场景
(一)归一化的作用
在机器学习领域中,不同评价指标(即特征向量中的不同特征就是所述的不同评价指标)往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。其中,最典型的就是数据的归一化处理。(可以参考学习:数据标准化/归一化)
简而言之,归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响。
1)在统计学中,归一化的具体作用是归纳统一样本的统计分布性。归一化在0~1之间是统计的概率分布,归一化在-1~+1之间是统计的坐标分布。
2)奇异样本数据是指相对于其他输入样本特别大或特别小的样本矢量(即特征向量),譬如,下面为具有两个特征的样本数据x1、x2、x3、x4、x5、x6(特征向量—>列向量),其中x6这个样本的两个特征相对其他样本而言相差比较大,因此,x6认为是奇异样本数据。
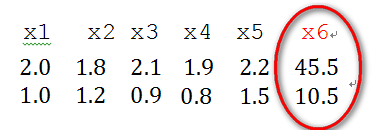
奇异样本数据的存在会引起训练时间增大,同时也可能导致无法收敛,因此,当存在奇异样本数据时,在进行训练之前需要对预处理数据进行归一化;反之,不存在奇异样本数据时,则可以不进行归一化。
解释范例:http://www.cnblogs.com/silence-tommy/p/7113498.html
--如果不进行归一化,那么由于特征向量中不同特征的取值相差较大,会导致目标函数变“扁”。这样在进行梯度下降的时候,梯度的方向就会偏离最小值的方向,走很多弯路,即训练时间过长。
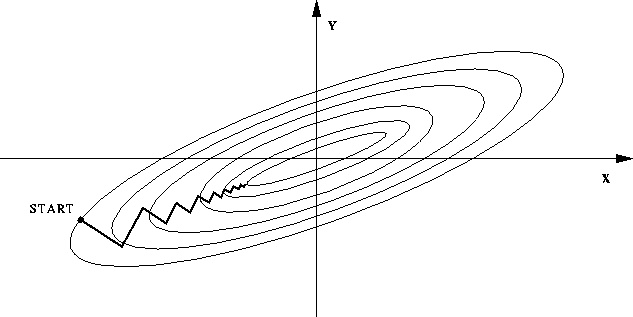
--如果进行归一化以后,目标函数会呈现比较“圆”,这样训练速度大大加快,少走很多弯路。
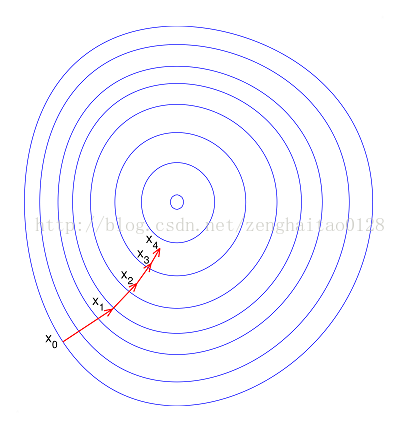
综上可知,归一化有如下好处,即
1)归一化后加快了梯度下降求最优解的速度;
2)归一化有可能提高精度(如KNN)
注:没有一种数据标准化的方法,放在每一个问题,放在每一个模型,都能提高算法精度和加速算法的收敛速度。
(二)归一化的方法
1)最大最小标准化(Min-Max Normalization)
a). 本归一化方法又称为离差标准化,使结果值映射到[0 ,1]之间,转换函数如下:
![]()
b). 本归一化方法比较适用在数值比较集中的情况;
c). 缺陷:如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量来替代max和min。
d). 应用场景:在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法(不包括Z-score方法)。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围
2)Z-score标准化方法
a). 数据处理后符合标准正态分布,即均值为0,标准差为1,其转化函数为:
![]()
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
b). 本方法要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕;
c). 应用场景:在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-score standardization表现更好。
3)非线性归一化
a). 本归一化方法经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。
b). 该方法包括 log,正切等,需要根据数据分布的情况,决定非线性函数的曲线:
---log对数函数转换方法
y = log10(x),即以10为底的对数转换函数,对应的归一化方法为:x' = log10(x) /log10(max),其中max表示样本数据的最大
值,并且所有样本数据均要大于等于1.
---atan反正切函数转换方法
利用反正切函数可以实现数据的归一化,即
x' = atan(x)*(2/pi)
使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上.
---L2范数归一化方法
L2范数归一化就是特征向量中每个元素均除以向量的L2范数:

(三)应用场景说明
1)概率模型不需要归一化,因为这种模型不关心变量的取值,而是关心变量的分布和变量之间的条件概率;
2)SVM、线性回归之类的最优化问题需要归一化,是否归一化主要在于是否关心变量取值;
3)神经网络需要标准化处理,一般变量的取值在-1到1之间,这样做是为了弱化某些变量的值较大而对模型产生影响。一般神经网络中的隐藏层采用tanh激活函数比sigmod激活函数要好些,因为tanh双曲正切函数的取值[-1,1]之间,均值为0.
4)在K近邻算法中,如果不对解释变量进行标准化,那么具有小数量级的解释变量的影响就会微乎其微。
(四)参考文献:
[1] http://blog.csdn.net/acdreamers/article/details/44664205
[2] http://www.cnblogs.com/silence-tommy/p/7113498.html
[3] http://blog.csdn.net/debug_snail/article/details/51781046
[4] http://www.open-open.com/lib/view/open1429697131932.html
[5] http://www.cnblogs.com/chaosimple/archive/2013/07/31/3227271.html
[6] http://blog.csdn.net/zbc1090549839/article/details/44103801
[7] http://blog.csdn.net/uestc_c2_403/article/details/75804617
[8] http://blog.csdn.net/u011650143/article/details/71515927

















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









