



几个一致性的方向
- 状态一致性
- 一致性检查点(checkpoint)
- 端到端(end-to-end)状态一致性
- 端到端的精确一次(exactly-once)保证
- Flink+Kafka端到端状态一致性的保证
1 状态一致性
•所谓的状态一致性,其实就是我们所说的计算结果要保证准确。
•一条数据不应该丢失,也不应该重复计算
•在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完全正确的。
1 三种级别
at-most-once: 即数据最多计算一次或者不计算代表数据丢失
at-least-once: 数据计算一次,保证数据的完整,但是不能排除重复计算,导致结果不一致
exactly-once: 对数据的计算只是精确到计算一次
2一致性检查点(Checkpoints)
Flink 使用了一种轻量级快照机制 —— 检查点(checkpoint)来保证exactly-once 语义
有状态流应用的一致检查点,其实就是:
所有任务的状态,在某个时间点的一份拷贝(一份快照)。而这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候。
应用状态的一致检查点,是 Flink 故障恢复机制的核心
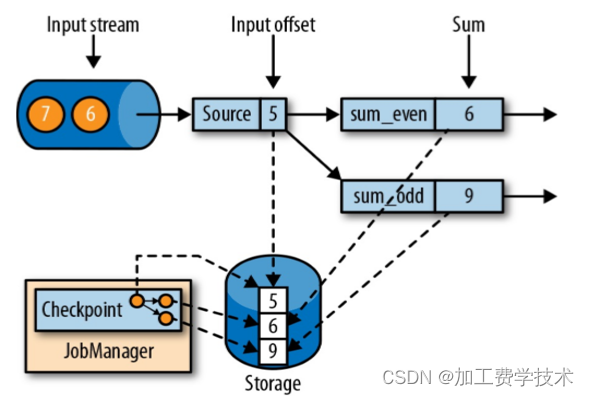
下图就是checkpoint一致性检查点
5,6,9这些都是一个输入数据全部完成,由jobManager落盘拷贝保存副本
3 端到端(end-to-end)状态一致性
- 内部保证 ——checkpoint
- source 端 —— 可重设数据的读取位置,kafkasource 数据的偏移量
- sink 端 —— 从故障恢复时,数据不会重复写入外部系统
3.1 幂等写入
所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了
3.2 事务写入
•事务(Transaction)
应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消
具有原子性:一个事务中的一系列的操作要么全部成功,要么一个都不做
•实现思想:构建的事务对应着 checkpoint,等到checkpoint 真正完成的时候,才把所有对应的结果写入 sink系统中
•实现方式
- 预写日志
- 两阶段提交
1 预写日志:
把结果数据先当成状态保存,然后在收到checkpoint 完成的通知时,一次性写入 sink系统(一次性写入有可能失败,导致多次写入)
一批写入,会增大延迟,一批次写入失败,数据会重新写入,导致多次写入
2 两阶段提交:
- 对于每个checkpoint,sink 任务会启动一个事务,并将接下来所有接收的数据添加到事务里
- 然后将这些数据写入外部 sink系统,但不提交它们 —— 这时只是“预提交”
- 当它收到checkpoint 完成的通知时,它才正式提交事务,实现结果的真正写入
Ø这种方式真正实现了 exactly-once,它需要一个提供事务支持的外部 sink 系统。Flink 提供了 TwoPhaseCommitSinkFunction 接口。
要求:
1Sink系统必须支持事务提交
2 两个checkpoint 之间必须能开启一个事务,让数据按照事务的方式写入
3 在checkpoint完成通知之前,事务必须是在等待的状态,否则超时会失败
4 Flink+Kafka 端到端状态一致性的保证
- 内部 —— 利用 checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
- source —— kafka consumer 作为source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
- sink —— kafka producer 作为sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
1 针对Sink的两阶段提交图解(exactly-once)
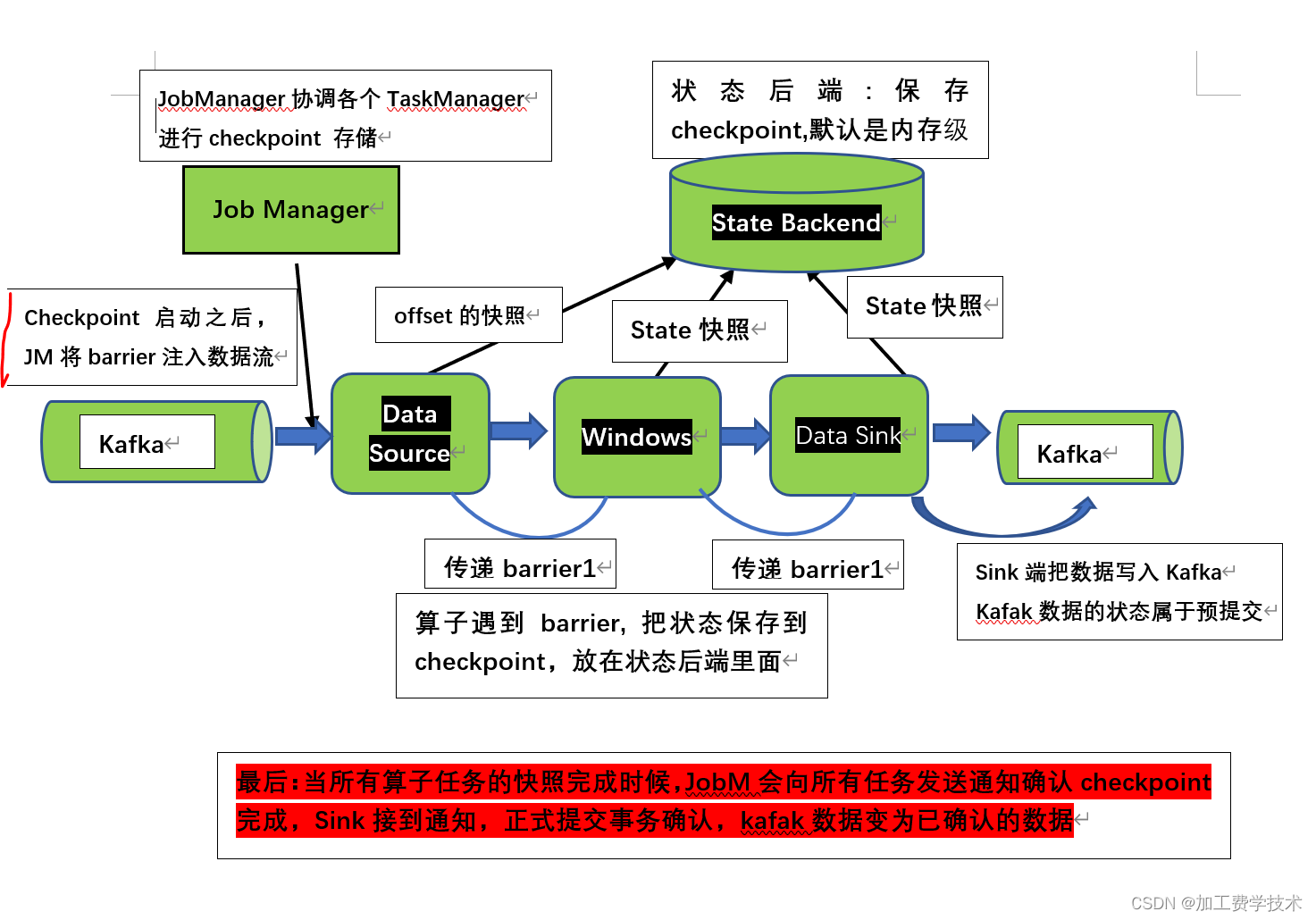
整个过程描述:
- 第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”
- jobmanager 触发checkpoint 操作,barrier从source 开始向下传递,遇到barrier 的算子将状态存入状态后端,并通知 jobmanager
- sink 连接器收到barrier,保存当前状态,存入checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
- jobmanager 收到所有任务的通知,发出确认信息,表示checkpoint 完成
- sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据,外部kafka关闭事务,提交的数据可以正常消费了。
补充
1 在代码中怎么体现ck呢? 通过env设置checkpoints的模式、状态后端保存的位置等等
// 1.4 状态后端及检查点相关配置
// 1.4.1 设置状态后端
env.setStateBackend(new HashMapStateBackend());
// 1.4.2 开启 checkpoint
env.enableCheckpointing(5000);
// 1.4.3 设置 checkpoint 模式: 精准一次
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 1.4.4 checkpoint 存储
env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/gmall2023/stream/" + ckAndGroupId);
// 1.4.5 checkpoint 并发数
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 1.4.6 checkpoint 之间的最小间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(5000);
// 1.4.7 checkpoint 的超时时间
env.getCheckpointConfig().setCheckpointTimeout(10000);
// 1.4.8 job 取消时 checkpoint 保留策略
env.getCheckpointConfig().setExternalizedCheckpointCleanup(RETAIN_ON_CANCELLATION);2 一次完整的checkpoints是内部barrier到末尾sink,想JOB提交ack完成一次checkpont,
所有算子,都接受到barrier并且完成快照想JB提交完成ack响应,才算是一次完整的checkpoint


















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









