







概况:
Flink 是 Apache 基金会旗下的一个开源大数据处理框架。目前,Flink 已经成为各大公司大数据实时处理的发力重点,特别是国内以阿里为代表的一众互联网大厂都在全力投入,为 Flink 社区贡献了大量源码。
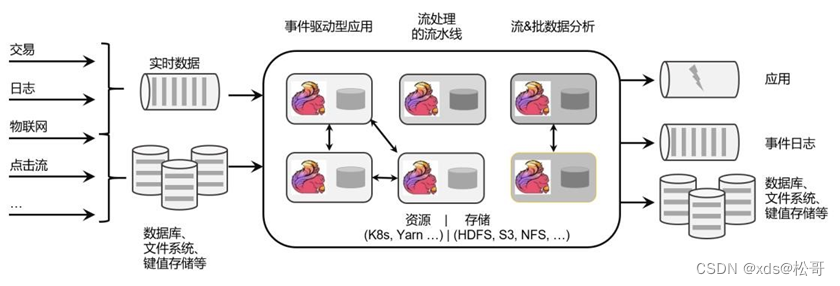
Apache Flink 是一个框架和分布式处理引擎,如下图所示,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
Flink它可以处理有界的数据集、也可以处理无界的数据集、它可以流式的处理数据、也可以批量的处理数据。其中:
- 无穷数据集:无穷的持续集成的数据集合
- 有界数据集:有限不会改变的数据集合
- 流式:只要数据一直在产生,计算就持续地进行
- 批处理:在预先定义的时间内运行计算,当完成时释放计算机资源
Flink的主要应用场景:
Flink是一个大数据流式处理引擎,处理的是流式数据,也就是“数据流”(Data Flow)。顾名思义,数据流的含义是,数据并不是收集好的,而是像水流一样,是一组有序的数据序列,逐个到来、逐个处理。由于数据来到之后就会被即刻处理,所以流处理的一大特点就是“快速”,也就是良好的实时性。Flink 适合的场景,其实也就是需要实时处理数据流的场景。
具体来看,一些行业中的典型应用有:
- 电商和市场营销:实时数据报表、广告投放、实时推荐
- 物联网(IOT):传感器实时数据采集和显示、实时报警,交通运输业
- 物流配送和服务业:订单状态实时更新、通知信息推送
- 银行和金融业:实时结算和通知推送,实时检测异常行为
Flink 的核心特性:
Flink区别于传统数据处理框架的特性如下:
- 高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
- 结果的准确性。Flink 提供了事件时间(event-time)和处理时间(processing-time)语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
- 精确一次(exactly-once)的状态一致性保证。
- 可以连接到最常用的存储系统,如 Apache Kafka、Apache Cassandra、Elasticsearch、JDBC、Kinesis 和(分布式)文件系统,如 HDFS 和 S3。
- 高可用。本身高可用的设置,加上与 K8s,YARN 和 Mesos 的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink 能做到以极少的停机时间 7×24 全天候运行。
- 能够更新应用程序代码并将作业(jobs)迁移到不同的 Flink 集群,而不会丢失应用程序的状态。
为何选择Flink:
Flink 是一个开源的分布式流式处理框架:
- 提供准确的结果,甚至在出现无序或者延迟加载的数据的情况下。
- 它是状态化的容错的,同时在维护一次完整的的应用状态时,能无缝修复错误。
- 大规模运行,在上千个节点运行时有很好的吞吐量和低延迟。
Flink的流式计算模型启用了很多功能特性,如状态管理,处理无序数据,灵活的视窗,这些功能对于得出无穷数据集的精确结果是很重要的。
- Flink保证状态化计算强一致性。”状态化“意味着应用可以维护随着时间推移已经产生的数据聚合或者,并且 Filnk 的检查点机制在一次失败的事件中一个应用状态的强一致性。
- Flink支持流式计算和带有事件时间语义的视窗。事件时间机制使得那些事件无序到达甚至延迟到达的数据流能够计算出精确的结果。
- 除了提供数据驱动的视窗外,Flink 还支持基于时间,计数,session 等的灵活视窗。视窗能够用灵活的触发条件定制化从而达到对复杂的流传输模式的支持。Flink 的视窗使得模拟真实的创建数据的环境成为可能。
- Flink 的容错能力是轻量级的,允许系统保持高并发,同时在相同时间内提供强一致性保证。Flink 以零数据丢失的方式从故障中恢复,但没有考虑可靠性和延迟之间的折衷。
- Flink 能满足高并发和低延迟(计算大量数据很快)。
- Flink保存点提供了一个状态化的版本机制,使得能以无丢失状态和最短停机时间的方式更新应用或者回退历史数据。
- Flink 被设计成能用上千个点在大规模集群上运行。除了支持独立集群部署外,Flink 还支持 YARN 和Mesos 方式部署。
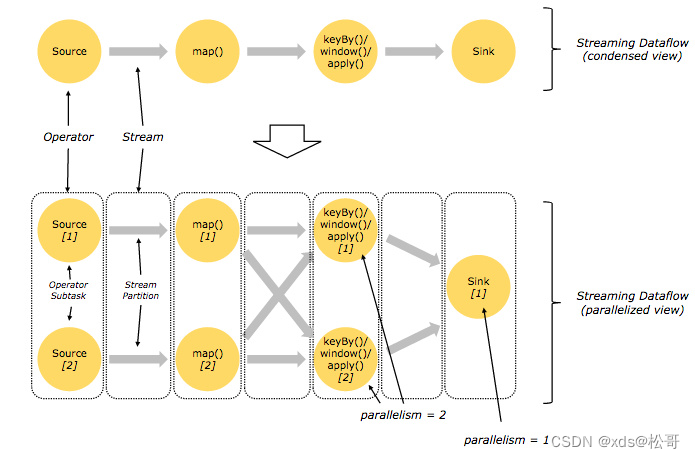
- Flink 的程序内在是并行和分布式的,数据流可以被分区成 stream partitions,operators 被划分为operator subtasks; 这些 subtasks 在不同的机器或容器中分不同的线程独立运行;operator subtasks 的数量在具体的 operator 就是并行计算数,程序不同的 operator 阶段可能有不同的并行数;如下图所示,source operator 的并行数为 2,但最后的 sink operator 为1;
- Flink 在 JVM 中提供了自己的内存管理,使其独立于 Java 的默认垃圾收集器。 它通过使用散列,索引,缓存和排序有效地进行内存管理。
- Flink 拥有丰富的库来进行机器学习,图形处理,关系数据处理等。 由于其架构,很容易执行复杂的事件处理和警报。
抽象级别(分层API):
Flink 提供了不同的抽象级别以开发流式或批处理应用。

- 最底层提供了有状态流。它将通过 过程函数(Process Function)嵌入到 DataStream API 中。它允许用户可以自由地处理来自一个或多个流数据的事件,并使用一致、容错的状态。除此之外,用户可以注册事件时间和处理事件回调,从而使程序可以实现复杂的计算。
- DataStream / DataSet API :是 Flink 提供的核心 API ,DataSet 处理有界的数据集,DataStream 处理有界或者无界的数据流。用户可以通过各种方法(map / flatmap / window / keyby / sum / max / min / avg / join 等)将数据进行转换 / 计算。
- Table API :是以 表 为中心的声明式 DSL,其中表可能会动态变化(在表达流数据时)。Table API 提供了例如 select、project、join、group-by、aggregate 等操作,使用起来却更加简洁(代码量更少)。你可以在表与 DataStream/DataSet 之间无缝切换,也允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
- Flink 提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以 SQL查询表达式的形式表现程序。SQL 抽象与 Table API 交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行。
Flink程序与数据流结构:

Flink 应用程序结构就是如上图所示:
Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。即:
- Map:这是最简单的转换之一,其中输入是一个数据流,输出的也是一个数据流。
- FlatMap:采用一条记录并输出零个,一个或多个记录。
- Filter:Filter函数根据条件判断出结果。
- KeyBy:在逻辑上是基于 key 对流进行分区;在内部,它使用 hash 函数对流进行分区;它返回 KeyedDataStream 数据流。
- Reduce:返回单个的结果值,并且 reduce 操作每处理一个元素总是创建一个新值;常用的方法有 average, sum, min, max, count,使用 reduce 方法都可实现。
- Fold:通过将最后一个文件夹流与当前记录组合来推出 KeyedStream,它会发回数据流。
- Aggregations:DataStream API 支持各种聚合,例如 min,max,sum 等。这些函数可以应用于 KeyedStream 以获得 Aggregations 聚合。
- Window:Window 函数允许按时间或其他条件对现有 KeyedStream 进行分组。要将流切片到窗口,我们可以使用 Flink 自带的窗口分配器。 我们有选项,如 tumbling windows, sliding windows, global 和 session windows。 Flink 还允许您通过扩展 WindowAssginer 类来编写自定义窗口分配器。
- WindowAll:windowAll 函数允许对常规数据流进行分组。 通常,这是非并行数据转换,因为它在非分区数据流上运行。与常规数据流功能类似,我们也有窗口数据流功能。 唯一的区别是它们处理窗口数据流。所以窗口缩小就像 Reduce 函数一样,Window fold 就像 Fold 函数一样,并且还有聚合。
- Union:Union 函数将两个或多个数据流结合在一起。 这样就可以并行地组合数据流。如果我们将一个流与自身组合,那么它会输出每个记录两次。
- Window join:我们可以通过一些 key 将同一个 window 的两个数据流 join 起来。
- Split:此功能根据条件将流拆分为两个或多个流。当您获得混合流并且您可能希望单独处理每个数据流时,可以使用此方法。
- Select:此功能允许您从拆分流中选择特定流。
- Project:Project 函数允许您从事件流中选择属性子集,并仅将所选元素发送到下一个处理流。
Sink:接收器,Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 sink。
分布式运行:
Flink 作业提交架构流程可见下图:
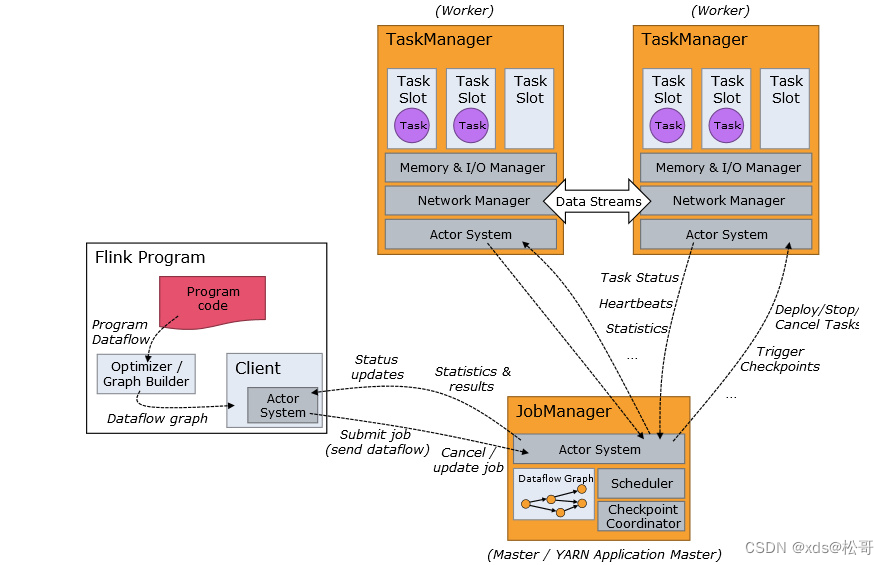
- Program Code:我们编写的 Flink 应用程序代码
- Job Client:Job Client 不是 Flink 程序执行的内部部分,但它是任务执行的起点。 Job Client 负责接受用户的程序代码,然后创建数据流,将数据流提交给 Job Manager 以便进一步执行。 执行完成后,Job Client 将结果返回给用户
- Job Manager:主进程(也称为作业管理器)协调和管理程序的执行。 它的主要职责包括安排任务,管理checkpoint ,故障恢复等。机器集群中至少要有一个 master,master 负责调度 task,协调 checkpoints 和容灾,高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是 standby; Job Manager 包含 Actor system、Scheduler、Check pointing 三个重要的组件
- Task Manager:从 Job Manager 处接收需要部署的 Task。Task Manager 是在 JVM 中的一个或多个线程中执行任务的工作节点。 任务执行的并行性由每个 Task Manager 上可用的任务槽决定。 每个任务代表分配给任务槽的一组资源。 例如,如果 Task Manager 有四个插槽,那么它将为每个插槽分配 25% 的内存。 可以在任务槽中运行一个或多个线程。 同一插槽中的线程共享相同的 JVM。 同一 JVM 中的任务共享 TCP 连接和心跳消息。Task Manager 的一个 Slot 代表一个可用线程,该线程具有固定的内存,注意 Slot 只对内存隔离,没有对 CPU 隔离。默认情况下,Flink 允许子任务共享 Slot,即使它们是不同 task 的 subtask,只要它们来自相同的 job。这种共享可以有更好的资源利用率。
Flink 配置文件:
安装好Flink后,看下安装路径下的配置文件:
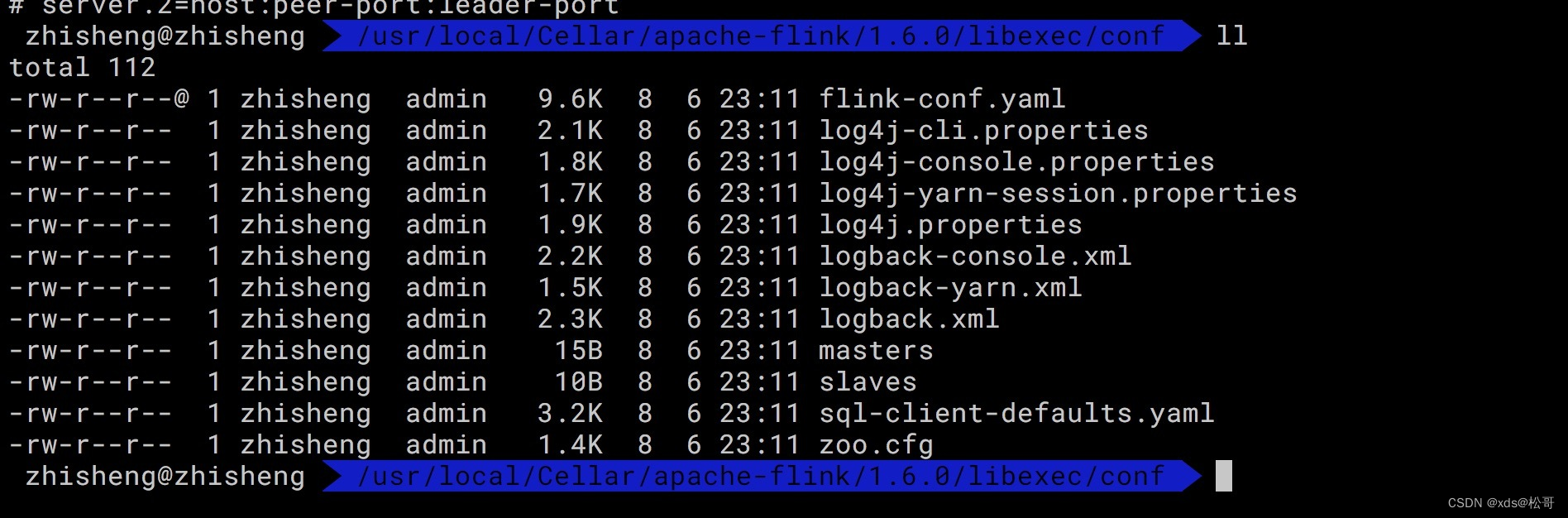
安装目录下主要有 flink-conf.yaml 配置、日志的配置文件、zk 配置、Flink SQL Client 配置。这里主要对flink-conf.yaml 配置进行说明:
基础配置:
# jobManager 的IP地址 jobmanager.rpc.address: localhost # JobManager 的端口号 jobmanager.rpc.port: 6123 # JobManager JVM heap 内存大小 jobmanager.heap.size: 1024m # TaskManager JVM heap 内存大小 taskmanager.heap.size: 1024m # 每个 TaskManager 提供的任务 slots 数量大小 taskmanager.numberOfTaskSlots: 1 # 程序默认并行计算的个数 parallelism.default: 1 # 文件系统来源 # fs.default-scheme
高可用性配置:
# 可以选择 'NONE' 或者 'zookeeper'. # high-availability: zookeeper # 文件系统路径,让 Flink 在高可用性设置中持久保存元数据 # high-availability.storageDir: hdfs:///flink/ha/ # zookeeper 集群中仲裁者的机器 ip 和 port 端口号 # high-availability.zookeeper.quorum: localhost:2181 # 默认是 open,如果 zookeeper security 启用了该值会更改成 creator # high-availability.zookeeper.client.acl: open
容错和检查点配置:
# 用于存储和检查点状态 # state.backend: filesystem # 存储检查点的数据文件和元数据的默认目录 # state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints # savepoints 的默认目标目录(可选) # state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints # 用于启用/禁用增量 checkpoints 的标志 # state.backend.incremental: false
web 前端配置:
# 基于 Web 的运行时监视器侦听的地址. #jobmanager.web.address: 0.0.0.0 # Web 的运行时监视器端口 rest.port: 8081 # 是否从基于 Web 的 jobmanager 启用作业提交 # jobmanager.web.submit.enable: false
高级配置:
# io.tmp.dirs: /tmp # 是否应在 TaskManager 启动时预先分配 TaskManager 管理的内存 # taskmanager.memory.preallocate: false # 类加载解析顺序,是先检查用户代码 jar(“child-first”)还是应用程序类路径(“parent-first”)。 默认设置指示首先从用户代码 jar 加载类 # classloader.resolve-order: child-first # 用于网络缓冲区的 JVM 内存的分数。 这决定了 TaskManager 可以同时拥有多少流数据交换通道以及通道缓冲的程度。 如果作业被拒绝或者您收到系统没有足够缓冲区的警告,请增加此值或下面的最小/最大值。 另请注意,“taskmanager.network.memory.min”和“taskmanager.network.memory.max”可能会覆盖此分数 # taskmanager.network.memory.fraction: 0.1 # taskmanager.network.memory.min: 67108864 # taskmanager.network.memory.max: 1073741824
Flink 集群安全配置:
# 指示是否从 Kerberos ticket 缓存中读取 # security.kerberos.login.use-ticket-cache: true # 包含用户凭据的 Kerberos 密钥表文件的绝对路径 # security.kerberos.login.keytab: /path/to/kerberos/keytab # 与 keytab 关联的 Kerberos 主体名称 # security.kerberos.login.principal: flink-user # 以逗号分隔的登录上下文列表,用于提供 Kerberos 凭据(例如,`Client,KafkaClient`使用凭证进行 ZooKeeper 身份验证和 Kafka 身份验证) # security.kerberos.login.contexts: Client,KafkaClient
Zookeeper 安全配置:
# 覆盖以下配置以提供自定义 ZK 服务名称 # zookeeper.sasl.service-name: zookeeper # 该配置必须匹配 "security.kerberos.login.contexts" 中的列表(含有一个) # zookeeper.sasl.login-context-name: Client
HistoryServer:
# 你可以通过 bin/historyserver.sh (start|stop) 命令启动和关闭 HistoryServer # 将已完成的作业上传到的目录 # jobmanager.archive.fs.dir: hdfs:///completed-jobs/ # 基于 Web 的 HistoryServer 的地址 # historyserver.web.address: 0.0.0.0 # 基于 Web 的 HistoryServer 的端口号 # historyserver.web.port: 8082 # 以逗号分隔的目录列表,用于监视已完成的作业 # historyserver.archive.fs.dir: hdfs:///completed-jobs/ # 刷新受监控目录的时间间隔(以毫秒为单位) # historyserver.archive.fs.refresh-interval: 10000
Data Source 介绍:
Data Sources 就字面意思其实就可以知道:数据来源。
Flink做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来,Flink 就能够一直计算下去,这个 Data Sources 就是数据的来源地。
Flink 中你可以使用 StreamExecutionEnvironment.addSource(sourceFunction) 来为你的程序添加数据来源。
Flink 已经提供了若干实现好了的 source functions,当然你也可以通过实现 SourceFunction 来自定义非并行的 source 或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 sourc。
StreamExecutionEnvironment 中可以使用以下几个已实现的 stream sources:
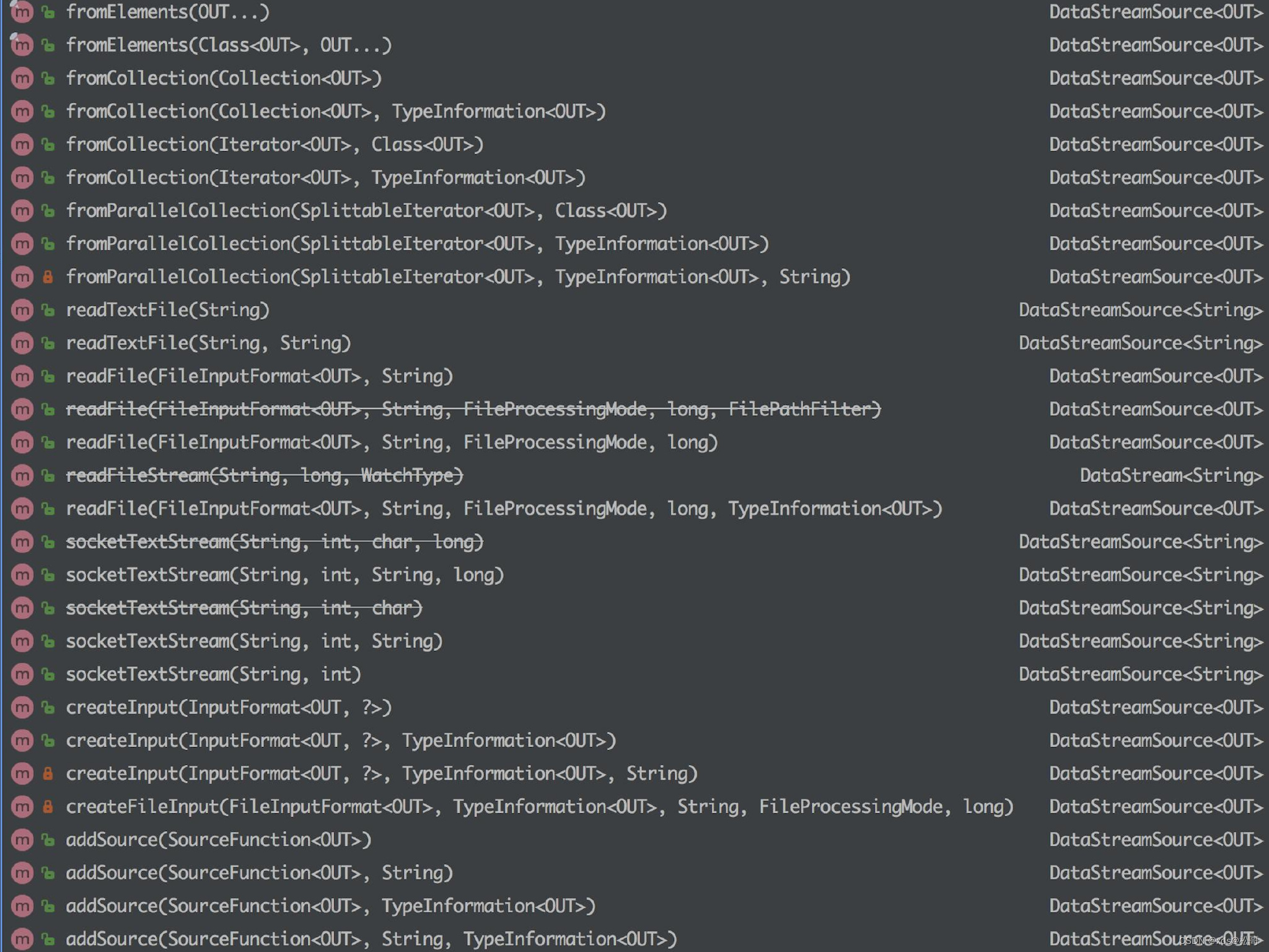
总的来说可以分为下面几大类:
- 基于集合:有界数据集,更偏向于本地测试用
- 基于文件:适合监听文件修改并读取其内容
- 基于 Socket:监听主机的 host port,从 Socket 中获取数据
- 自定义 addSource:大多数的场景数据都是无界的,会源源不断的过来。比如去消费 Kafka 某个 topic 上的数据,这时候就需要用到这个 addSource,可能因为用的比较多的原因吧,Flink 直接提供了 FlinkKafkaConsumer011 等类可供你直接使用。
基于集合:
- fromCollection(Collection):从 Java 的 Java.util.Collection 创建数据流。集合中的所有元素类型必须相同。
- fromCollection(Iterator, Class):从一个迭代器中创建数据流。Class 指定了该迭代器返回元素的类型。
- fromElements(T …):从给定的对象序列中创建数据流。所有对象类型必须相同。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Event> input = env.fromElements(
new Event(1, "barfoo", 1.0),
new Event(2, "start", 2.0),
new Event(3, "foobar", 3.0),
...
);- fromParallelCollection(SplittableIterator, Class):从一个迭代器中创建并行数据流。Class 指定了该迭代器返回元素的类型。
- generateSequence(from, to):创建一个生成指定区间范围内的数字序列的并行数据流。
基于文件:
- readTextFile(path):读取文本文件,即符合 TextInputFormat 规范的文件,并将其作为字符串返回。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.readTextFile("file:///path/to/file");- readFile(fileInputFormat, path):根据指定的文件输入格式读取文件(一次)。
- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo):这是上面两个方法内部调用的方法。它根据给定的 fileInputFormat 和读取路径读取文件。根据提供的 watchType,这个 source 可以定期(每隔 interval 毫秒)监测给定路径的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次路径对应文件的数据并退出(FileProcessingMode.PROCESS_ONCE)。你可以通过 pathFilter 进一步排除掉需要处理的文件。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<MyEvent> stream = env.readFile(
myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,
FilePathFilter.createDefaultFilter(), typeInfo);在具体实现上,Flink 把文件读取过程分为两个子任务,即目录监控和数据读取。每个子任务都由单独的实体实现。目录监控由单个非并行(并行度为1)的任务执行,而数据读取由并行运行的多个任务执行。后者的并行性等于作业的并行性。单个目录监控任务的作用是扫描目录(根据 watchType 定期扫描或仅扫描一次),查找要处理的文件并把文件分割成切分片(splits),然后将这些切分片分配给下游 reader。reader 负责读取数据。每个切分片只能由一个 reader 读取,但一个 reader 可以逐个读取多个切分片。
重要注意:
如果 watchType 设置为 FileProcessingMode.PROCESS_CONTINUOUSLY,则当文件被修改时,其内容将被重新处理。这会打破“exactly-once”语义,因为在文件末尾附加数据将导致其所有内容被重新处理。
如果 watchType 设置为 FileProcessingMode.PROCESS_ONCE,则 source 仅扫描路径一次然后退出,而不等待 reader 完成文件内容的读取。当然 reader 会继续阅读,直到读取所有的文件内容。关闭 source 后就不会再有检查点。这可能导致节点故障后的恢复速度较慢,因为该作业将从最后一个检查点恢复读取。
基于Socket:
socketTextStream(String hostname, int port):从 socket 读取。元素可以用分隔符切分。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999) // 监听 localhost 的 9999 端口过来的数据
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);自定义:
addSource:添加一个新的 source function。
例如,你可以 addSource(new FlinkKafkaConsumer011<>(…)) 以从 Apache Kafka 读取数据。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<KafkaEvent> input = env
.addSource(
new FlinkKafkaConsumer011<>(
parameterTool.getRequired("input-topic"), //从参数中获取传进来的 topic
new KafkaEventSchema(),
parameterTool.getProperties())
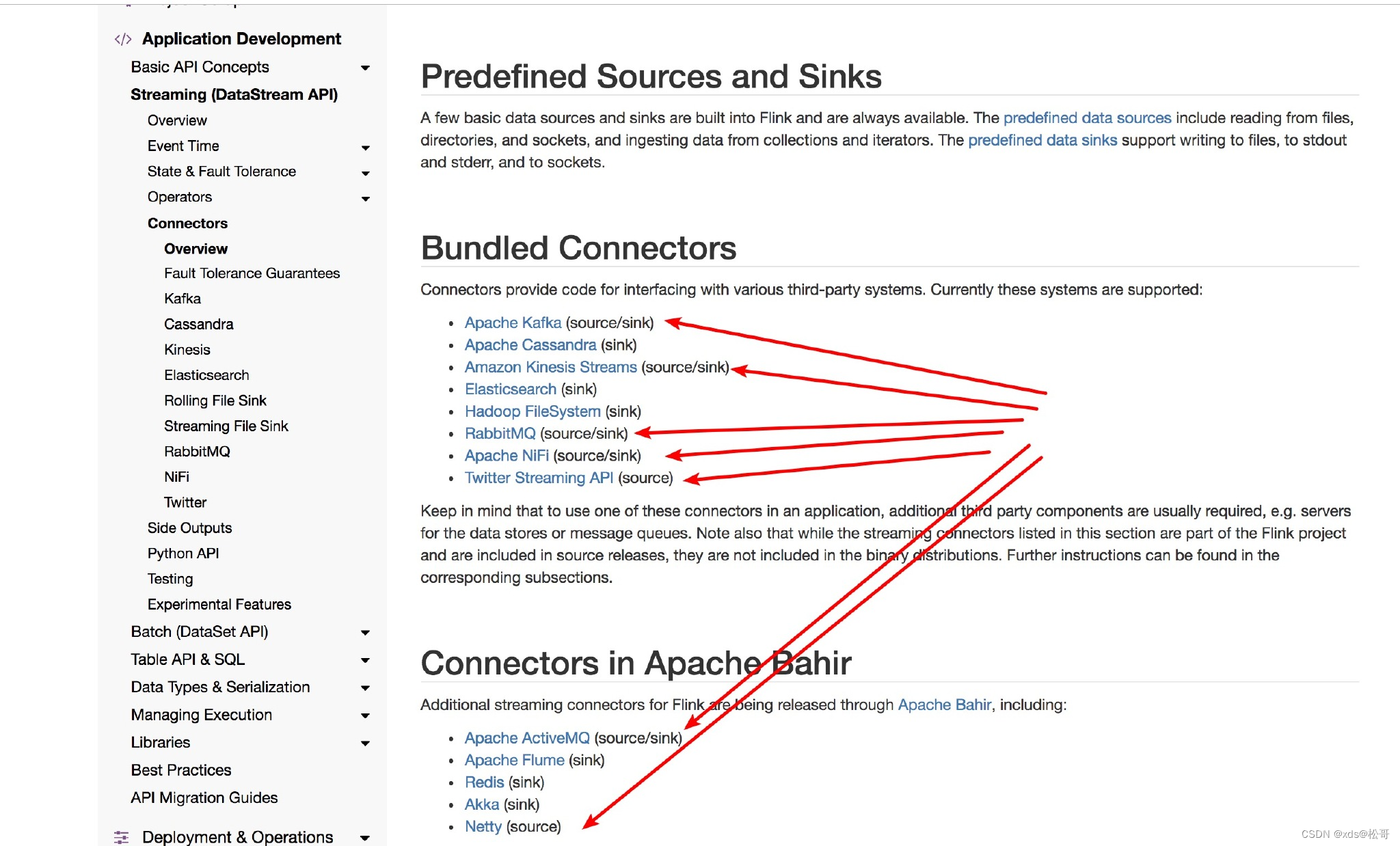
.assignTimestampsAndWatermarks(new CustomWatermarkExtractor()));Flink 目前支持如下图里面常见的 Source:
如果想自定义Source,需要去了解一下 SourceFunction 接口,它是所有 stream source 的根接口,它继承自一个标记接口(空接口)Function。
SourceFunction 定义了两个接口方法:
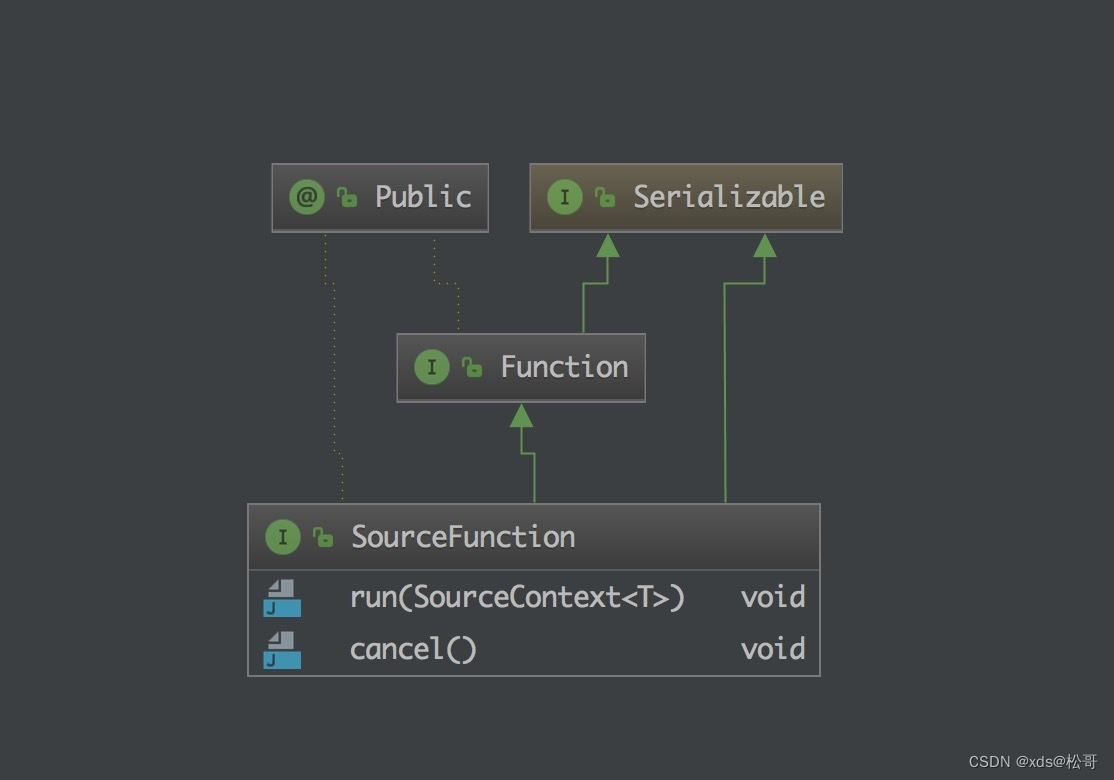
- run : 启动一个 source,即对接一个外部数据源然后 emit 元素形成 stream(大部分情况下会通过在该方法里运行一个 while 循环的形式来产生 stream)。
- cancel : 取消一个 source,也即将 run 中的循环 emit 元素的行为终止。
正常情况下,一个 SourceFunction 实现这两个接口方法就可以了。
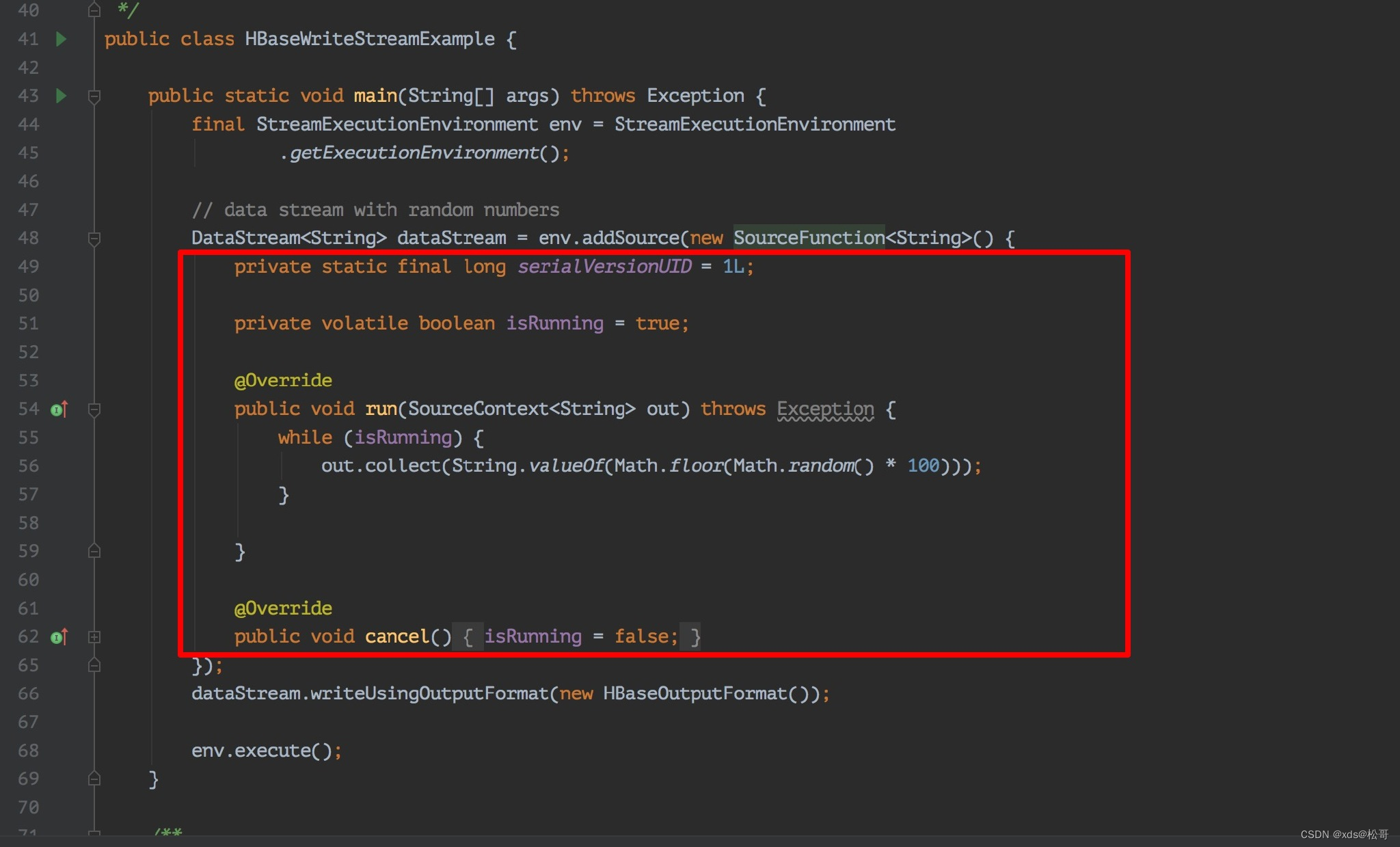
比如,实现一个 XXXSourceFunction,那么大致的模板是这样的:
Stream Windows:
通常来讲,Window就是用来对一个无限的流设置一个有限的集合,在有界的数据集上进行操作的一种机制。window 又可以分为基于时间(Time-based)的 window 以及基于数量(Count-based)的 window。
Flink DataStream API 提供了 Time 和 Count 的 window,同时增加了基于 Session 的 window。同时,由于某些特殊的需要,DataStream API 也提供了定制化的 window 操作,供用户自定义 window。
Time Windows:
正如命名那样,Time Windows 根据时间来聚合流数据。例如:一分钟的 tumbling time window 收集一分钟的元素,并在一分钟过后对窗口中的所有元素应用于一个函数。
在 Flink 中定义 tumbling time windows(翻滚时间窗口) 和 sliding time windows(滑动时间窗口) 非常简单:
- umbling time windows(翻滚时间窗口):输入一个时间参数
data.keyBy(1)
.timeWindow(Time.minutes(1)) //tumbling time window 每分钟统计一次数量和
.sum(1);- sliding time windows(滑动时间窗口):输入两个时间参数
data.keyBy(1)
.timeWindow(Time.minutes(1), Time.seconds(30)) //sliding time window 每隔 30s 统计过去一分钟的数量和
.sum(1);Count Windows:
Apache Flink 还提供计数窗口功能。如果计数窗口设置的为 100 ,那么将会在窗口中收集 100 个事件,并在添加第 100 个元素时计算窗口的值。
Flink 的窗口机制:
Flink 的内置 time window 和 count window 已经覆盖了大多数应用场景,但是有时候也需要定制窗口逻辑,此时 Flink 的内置的 window 无法解决这些问题。为了还支持自定义 window 实现不同的逻辑,DataStream API 为其窗口机制提供了接口。
到达窗口操作符的元素被传递给 WindowAssigner。WindowAssigner 将元素分配给一个或多个窗口,可能会创建新的窗口。
窗口本身只是元素列表的标识符,它可能提供一些可选的元信息,例如 TimeWindow 中的开始和结束时间。注意,元素可以被添加到多个窗口,这也意味着一个元素可以同时在多个窗口存在。
每个窗口都拥有一个 Trigger(触发器),该 Trigger(触发器) 决定何时计算和清除窗口。当先前注册的计时器超时时,将为插入窗口的每个元素调用触发器。在每个事件上,触发器都可以决定触发(即、清除(删除窗口并丢弃其内容),或者启动并清除窗口。一个窗口可以被求值多次,并且在被清除之前一直存在。注意,在清除窗口之前,窗口将一直消耗内存。
当 Trigger(触发器) 触发时,可以将窗口元素列表提供给可选的 Evictor,Evictor 可以遍历窗口元素列表,并可以决定从列表的开头删除首先进入窗口的一些元素。然后其余的元素被赋给一个计算函数,如果没有定义 Evictor,触发器直接将所有窗口元素交给计算函数。
计算函数接收 Evictor 过滤后的窗口元素,并计算窗口的一个或多个元素的结果。 DataStream API 接受不同类型的计算函数,包括预定义的聚合函数,如 sum(),min(),max(),以及 ReduceFunction,FoldFunction 或 WindowFunction。
如何自定义 Window?
1、Window Assigner:
负责将元素分配到不同的 window。Window API 提供了自定义的 WindowAssigner 接口,我们可以实现 WindowAssigner 的方法。同时,对于基于 Count 的 window 而言,默认采用了 GlobalWindow 的 window assigner,例如:keyBy.window(GlobalWindows.create())
2、Trigger:
Trigger 即触发器,定义何时或什么情况下移除 window。我们可以指定触发器来覆盖 WindowAssigner 提供的默认触发器。 请注意,指定的触发器不会添加其他触发条件,但会替换当前触发器。
3、Evictor(可选):
驱逐者,即保留上一 window 留下的某些元素。
4、通过 apply WindowFunction 来返回 DataStream 类型数据。
利用 Flink 的内部窗口机制和 DataStream API 可以实现自定义的窗口逻辑,例如 session window。
Flink中的Time:
Flink 在流程序中支持不同的 Time 概念,就比如有 Processing Time、Event Time 和 Ingestion Time。
Processing Time:
Processing Time 是指事件被处理时机器的系统时间。
当流程序在 Processing Time 上运行时,所有基于时间的操作(如时间窗口)将使用当时机器的系统时间。每小时 Processing Time 窗口将包括在系统时钟指示整个小时之间到达特定操作的所有事件。
例如,如果应用程序在上午 9:15 开始运行,则第一个每小时 Processing Time 窗口将包括在上午 9:15 到上午 10:00 之间处理的事件,下一个窗口将包括在上午 10:00 到 11:00 之间处理的事件。
Processing Time 是最简单的 “Time” 概念,不需要流和机器之间的协调,它提供了最好的性能和最低的延迟。但是,在分布式和异步的环境下,Processing Time 不能提供确定性,因为它容易受到事件到达系统的速度(例如从消息队列)、事件在系统内操作流动的速度以及中断的影响。
Event Time:
Event Time 是事件发生的时间,一般就是数据本身携带的时间。这个时间通常是在事件到达 Flink 之前就确定的,并且可以从每个事件中获取到事件时间戳。在 Event Time 中,时间取决于数据,而跟其他没什么关系。Event Time 程序必须指定如何生成 Event Time 水印,这是表示 Event Time 进度的机制。
完美的说,无论事件什么时候到达或者其怎么排序,最后处理 Event Time 将产生完全一致和确定的结果。但是,除非事件按照已知顺序(按照事件的时间)到达,否则处理 Event Time 时将会因为要等待一些无序事件而产生一些延迟。由于只能等待一段有限的时间,因此就难以保证处理 Event Time 将产生完全一致和确定的结果。
假设所有数据都已到达, Event Time 操作将按照预期运行,即使在处理无序事件、延迟事件、重新处理历史数据时也会产生正确且一致的结果。 例如,每小时事件时间窗口将包含带有落入该小时的事件时间戳的所有记录,无论它们到达的顺序如何。
请注意,有时当 Event Time 程序实时处理实时数据时,它们将使用一些 Processing Time 操作,以确保它们及时进行。
Ingestion Time:
Ingestion Time 是事件进入 Flink 的时间。 在源操作处,每个事件将源的当前时间作为时间戳,并且基于时间的操作(如时间窗口)会利用这个时间戳。
Ingestion Time 在概念上位于 Event Time 和 Processing Time 之间。 与 Processing Time 相比,它稍微贵一些,但结果更可预测。因为 Ingestion Time 使用稳定的时间戳(在源处分配一次),所以对事件的不同窗口操作将引用相同的时间戳,而在 Processing Time 中,每个窗口操作符可以将事件分配给不同的窗口(基于机器系统时间和到达延迟)。
与 Event Time 相比,Ingestion Time 程序无法处理任何无序事件或延迟数据,但程序不必指定如何生成水印。
在 Flink 中,,Ingestion Time 与 Event Time 非常相似,但 Ingestion Time 具有自动分配时间戳和自动生成水印功能。
Flink JobManager:
JobManager 协调每个 Flink 作业的部署。它负责调度和资源管理。
默认情况下,每个 Flink 集群都有一个 JobManager 实例。这会产生单点故障(SPOF):如果 JobManager 崩溃,则无法提交新作业且运行中的作业也会失败。
如果我们使用 JobManager 高可用模式,可以避免这个问题。您可以为 standalone 集群和 YARN 集群配置高可用模式。
standalone 集群:
standalone 集群的 JobManager 高可用性的概念是,任何时候都有一个主 JobManager 和 多个备 JobManagers,以便在主节点失败时有新的 JobNamager 接管集群。这样就保证了没有单点故障,一旦备 JobManager 接管集群,作业就可以依旧正常运行。主备 JobManager 实例之间没有明确的区别。每个 JobManager 都可以充当主备节点。
如何配置:
要启用 JobManager 高可用性功能,您必须将高可用性模式设置为 zookeeper,配置 ZooKeeper quorum,将所有 JobManagers 主机及其 Web UI 端口写入配置文件。
Flink 利用 ZooKeeper 在所有正在运行的 JobManager 实例之间进行分布式协调。ZooKeeper 是独立于 Flink 的服务,通过 leader 选举和轻量级一致性状态存储提供高可靠的分布式协调服务。Flink 包含用于Bootstrap ZooKeeper 安装的脚本。它在我们的 Flink 安装路径下面 /conf/zoo.cfg 。
Masters 文件:
要启动 HA 集群,请在以下位置配置 Masters 文件 conf/masters:
localhost:8081
xxx.xxx.xxx.xxx:8081
masters 文件包含启动 JobManagers 的所有主机以及 Web 用户界面绑定的端口,上面一行写一个。
默认情况下,job manager 选一个随机端口作为进程通信端口。您可以通过 high-availability.jobmanager.port 更改此设置。此配置接受单个端口(例如 50010),范围(50000-50025)或两者的组合(50010,50011,50020-50025,50050-50075)。
配置文件 (flink-conf.yaml):
要启动 HA 集群,请将以下配置键添加到 conf/flink-conf.yaml:
高可用性模式(必需):在 conf/flink-conf.yaml中,必须将高可用性模式设置为 zookeeper,以打开高可用模式。
high-availability: zookeeper
ZooKeeper quorum(必需):ZooKeeper quorum 是一组 ZooKeeper 服务器,它提供分布式协调服务。
high-availability.zookeeper.quorum: ip1:2181 [,...],ip2:2181
每个 ip:port 都是一个 ZooKeeper 服务器的 ip 及其端口,Flink 可以通过指定的地址和端口访问 zookeeper。
另外就是高可用存储目录,JobManager 元数据保存在文件系统 storageDir 中,在 ZooKeeper 中仅保存了指向此状态的指针, 推荐这个目录是 HDFS, S3, Ceph, nfs 等,该 storageDir 中保存了 JobManager 恢复状态需要的所有元数据。
high-availability.storageDir: hdfs:///flink/ha/
配置 master 文件和 ZooKeeper 配置后,您可以使用提供的集群启动脚本。他们将启动 HA 集群。请注意,启动 Flink HA 集群前,必须启动 Zookeeper 集群,并确保为要启动的每个 HA 集群配置单独的 ZooKeeper 根路径。
YARN 集群:
当运行高可用的 YARN 集群时,我们不会运行多个 JobManager 实例,而只会运行一个,该 JobManager 实例失败时,YARN 会将其重新启动。Yarn 的具体行为取决于您使用的 YARN 版本。
如何配置:
在 YARN 配置文件 yarn-site.xml 中,需要配置 application master 的最大重试次数:
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
除了上面可以配置最大重试次数外,你还可以在 flink-conf.yaml 配置如下:
yarn.application-attempts: 10
这意味着在如果程序启动失败,YARN 会再重试 9 次(9 次重试 + 1 次启动),如果启动 10 次作业还失败,yarn 才会将该任务的状态置为失败。如果因为节点硬件故障或重启,NodeManager 重新同步等操作,需要 YARN 继续尝试启动应用。这些重启尝试不计入 yarn.application-attempts 个数中。
容器关闭行为:
- YARN 2.3.0 < 版本 < 2.4.0. 如果 application master 进程失败,则所有的 container 都会重启。
- YARN 2.4.0 < 版本 < 2.6.0. TaskManager container 在 application master 故障期间,会继续工作。这具有以下优点:作业恢复时间更快,且缩短所有 task manager 启动时申请资源的时间。
- YARN 2.6.0 <= version: 将尝试失败有效性间隔设置为 Flink 的 Akka 超时值。尝试失败有效性间隔表示只有在系统在一个间隔期间看到最大应用程序尝试次数后才会终止应用程序。这避免了持久的工作会耗尽它的应用程序尝试。
Flink parallelism和Slot:
parallelism:
parallelism 是并行的意思,在 Flink 里面代表每个任务的并行度,适当的提高并行度可以大大提高 job 的执行效率,比如你的 job 消费 kafka 数据过慢,适当调大可能就消费正常了。
设置 parallelism:
cat flink-conf.yaml | grep parallelism
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1可以看到在flink配置文件中默认并行度是 1,如果在你的 flink job 里面不设置任何的 parallelism 的话,那么他也会有一个默认的 parallelism = 1。那也意味着你可以修改这个配置文件的默认并行度。
如果你是用命令行启动你的 Flink job,那么你也可以这样设置并行度(使用 -p 并行度):
./bin/flink run -p 10 ../word-count.jar
也可以通过这样来设置你整个程序的并行度:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(10);注意:这样设置的并行度是你整个程序的并行度,那么后面如果你的每个算子不单独设置并行度覆盖的话,那么后面每个算子的并行度就都是这里设置的并行度的值了。
如何给每个算子单独设置并行度呢?
data.keyBy(new xxxKey())
.flatMap(new XxxFlatMapFunction()).setParallelism(5)
.map(new XxxMapFunction).setParallelism(5)
.addSink(new XxxSink()).setParallelism(1)如上,就是在每个算子后面单独的设置并行度,这样的话,就算你前面设置了 env.setParallelism(10) 也是会被覆盖的。
这也说明优先级是:算子设置并行度 > env 设置并行度 > 配置文件默认并行度
slot:
Task Manager 是从 Job Manager 处接收需要部署的 Task,任务的并行性由每个 Task Manager 上可用的 slot 决定。每个任务代表分配给任务槽的一组资源,slot 在 Flink 里面可以认为是资源组,Flink 将每个任务分成子任务并且将这些子任务分配到 slot 来并行执行程序。
例如,如果 Task Manager 有四个 slot,那么它将为每个 slot 分配 25% 的内存。 可以在一个 slot 中运行一个或多个线程。 同一 slot 中的线程共享相同的 JVM。 同一 JVM 中的任务共享 TCP 连接和心跳消息。Task Manager 的一个 Slot 代表一个可用线程,该线程具有固定的内存,注意 Slot 只对内存隔离,没有对 CPU 隔离。默认情况下,Flink 允许子任务共享 Slot,即使它们是不同 task 的 subtask,只要它们来自相同的 job。这种共享可以有更好的资源利用率。
文字说的比较干,拿下面的图片来讲解:
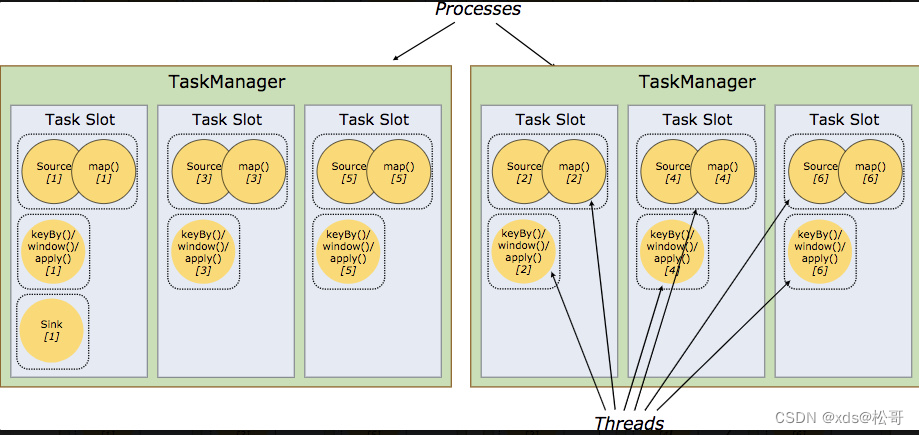
上面图片中有两个 Task Manager,每个 Task Manager 有三个 slot,这样我们的算子最大并行度那么就可以达到 6 个,在同一个 slot 里面可以执行 1 至多个子任务。
那么再看上面的图片,source/map/keyby/window/apply 最大可以有 6 个并行度,sink 只用了 1 个并行。
每个 Flink TaskManager 在集群中提供 slot。 slot 的数量通常与每个 TaskManager 的可用 CPU 内核数成比例。一般情况下你的 slot 数是你每个 TaskManager 的 cpu 的核数。
但是 flink 配置文件中设置的 task manager 默认的 slot 是 1。
















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









