







1、概述
Redis缓存的使用,极大的提升了应用程序的性能和效率,特别是数据查询方面。但同时,它也带来了一
些问题。其中,最要害的问题,就是数据的一致性问题,从严格意义上讲,这个问题无解。如果对数据
的一致性要求很高,那么就不能使用缓存。
另外的一些典型问题就是,缓存穿透、缓存雪崩和缓存击穿。目前,业界也都有比较流行的解决方案。
2、缓存穿透(查不到)
1)概念
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中(秒杀!),于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
2)解决方案
a)布隆过滤器
1、简介
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力;
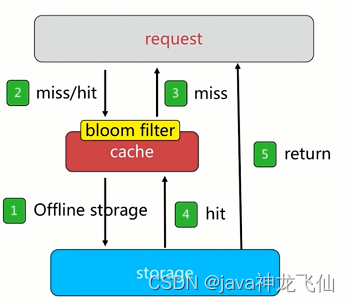
Bloom Filter是一种空间效率很高的概率型数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
那么它的诞生契机是什么呢?我们平常在检测集合中是否存在某元素时,都会采用比较的方法。
考虑以下情况:
如果集合用线性表存储,查找的时间复杂度为O(n)。
如果用平衡BST(如AVL树、红黑树)存储,时间复杂度为O(logn)。
如果用哈希表存储,并用链地址法与平衡BST解决哈希冲突(参考JDK8的HashMap实现方法),时间复杂度也要有O[log(n/m)],m为哈希分桶数。
总而言之,当集合中元素的数量极多(百/千万级甚至更多)时,不仅查找会变得很慢,而且占用的空间也会大到无法想象。而布隆(BF)过滤器就是解决这个矛盾的利器。
2、布隆过滤器原理
BF是由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组均初始化为0,所有哈希函数都可以分别把输入数据尽量均匀地散列。
当要插入一个元素时,将其数据分别输入k个哈希函数,产生k个哈希值。以哈希值作为位数组中的下标,将所有k个对应的比特置为1。
当要查询(即判断是否存在)一个元素时,同样将其数据输入哈希函数,然后检查对应的k个比特。如果有任意一个比特为0,表明该元素一定不在集合中。如果所有比特均为1,表明该集合有(较大的)可能性在集合中。为什么不是一定在集合中呢?因为一个比特被置为1有可能会受到其他元素的影响,这就是所谓“假阳性”(false positive)。相对地,“假阴性”(false negative)在BF中是绝不会出现的。
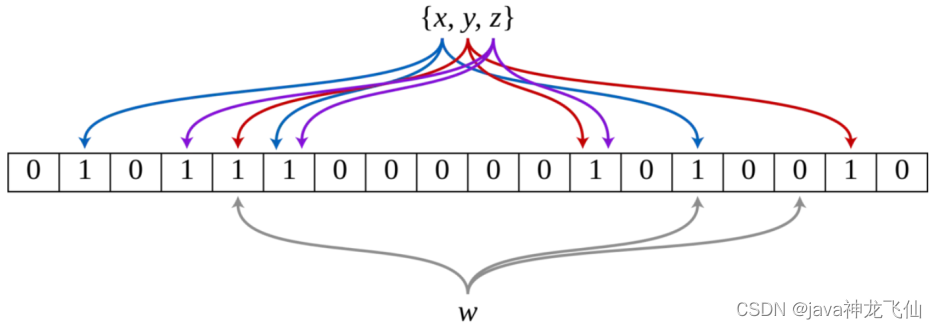
下图示出一个m=18, k=3的BF示例。集合中的x、y、z三个元素通过3个不同的哈希函数散列到位数组中。当查询元素w时,因为有一个比特为0,因此w不在该集合中
BF的优点是显而易见的:
不需要存储数据本身,只用比特表示,因此空间占用相对于传统方式有巨大的优势,并且能够保密数据;
时间效率也较高,插入和查询的时间复杂度均为O(k);
哈希函数之间相互独立,可以在硬件指令层面并行计算。
但是,它的缺点也同样明显:
存在假阳性的概率,不适用于任何要求100%准确率的情境;
只能插入和查询元素,不能删除元素,这与产生假阳性的原因是相同的。我们可以简单地想到通过计数(即将一个比特扩展为计数值)来记录元素数,但仍然无法保证删除的元素一定在集合中。
布隆过滤器有这么些特点:
哈希函数个数k越多,假阳性概率越低;
位数组长度m越大,假阳性概率越低;
已插入元素的个数n越大,假阳性概率越高。
3、实现
布隆过滤器(guava):
导入依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>
解决方式:
@Resource//不能使用@Autowired,如果非要使用,不注明泛型类型即可
private RedisTemplate<String, Object> redisTemplate;
public static final String REDIS_USER_KEY = "user:id:";
private static final double fpp = 0.03;
private static BloomFilter<Integer> bf;
@PostConstruct
public void init1() {
List<User> list = list();
if (list.size() < 1) {
return;
}
bf = BloomFilter.create(Funnels.integerFunnel(), list.size(), fpp);
// 初始化所有的用户id到过滤器中
for (int i = 0; i < list.size(); i++) {
bf.put(Integer.valueOf(list.get(i).getId()));
}
}
/**缓存穿透
* 解决方式:布隆过滤器(guava)
* @param id
* @return
*/
@GetMapping("/getById-2")
public User getById_2(@RequestParam("id") Integer id) {
//判断布隆过滤器是否存在
if (!bf.mightContain(id)) {
return null;
}
return getUser(REDIS_USER_KEY + id, String.valueOf(id));
}
/**
* 获取用户
* @param s
* @param value
* @return
*/
private User getUser(String s, String value) {
Object object = redisTemplate.opsForValue().get(REDIS_USER_KEY + s);
if (object != null) {
return (User) object;
} else {
log.info("查询数据库");
User user = userService.getById(value);
if (Objects.nonNull(user)) {
redisTemplate.opsForValue().set(REDIS_USER_KEY + s, user);
}
return user;
}
}
布隆过滤器(guava+redis):com.zengqingfa.springboot.mybatis.demo.core.RedisBloomFilter
package com.zengqingfa.springboot.mybatis.demo.core;
import com.google.common.base.Preconditions;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
/**
*
* @fileName: RedisBloomFilter
* @author: zengqf3
* @date: 2021-3-26 15:07
* @description:
*/
@Component
public class RedisBloomFilter {
@Autowired
private RedisTemplate redisTemplate;
/**
* 根据给定的布隆过滤器添加值
* @param bloomFilterHelper
* @param key
* @param value
* @param <T>
*/
public <T> void put(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
redisTemplate.opsForValue().setBit(key, i, true);
}
}
/**
* 根据给定的布隆过滤器判断值是否存在
* @param bloomFilterHelper
* @param key
* @param value
* @param <T>
* @return
*/
public <T> boolean contains(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
if (!redisTemplate.opsForValue().getBit(key, i)) {
return false;
}
}
return true;
}
}
com.zengqingfa.springboot.mybatis.demo.core.BloomFilterHelper
package com.zengqingfa.springboot.mybatis.demo.core;
import com.google.common.base.Preconditions;
import com.google.common.hash.Funnel;
import com.google.common.hash.Hashing;
/**
*
* @fileName: BloomFilterHelper
* @author: zengqf3
* @date: 2021-3-26 15:27
* @description:
*/
public class BloomFilterHelper<T> {
/**
* hash循环次数
*/
private int numHashFunctions;
/**
* bitsize长度
*/
private int bitSize;
private Funnel<T> funnel;
/**
* @param funnel
* @param expectedInsertions 期望插入长度
* @param fpp 误差率
*/
public BloomFilterHelper(Funnel<T> funnel, int expectedInsertions, double fpp) {
Preconditions.checkArgument(funnel != null, "funnel不能为空");
this.funnel = funnel;
bitSize = optimalNumOfBits(expectedInsertions, fpp);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public int[] murmurHashOffset(T value) {
int[] offset = new int[numHashFunctions];
long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
offset[i - 1] = nextHash % bitSize;
}
return offset;
}
/**
* 计算bit数组长度
*/
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/**
* 计算hash方法执行次数
*/
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
}
实现:
@Autowired
private RedisBloomFilter redisBloomFilter;
private static BloomFilterHelper<Integer> bfRedis;
@PostConstruct
public void init2() {
List<User> list = list();
if (list.size() < 1) {
return;
}
bfRedis = new BloomFilterHelper<>(Funnels.integerFunnel(), list.size(), fpp);
// 初始化所有的用户id到过滤器中
for (int i = 0; i < list.size(); i++) {
redisBloomFilter.put(bfRedis, list.get(i).getId(), Integer.valueOf(list.get(i).getId()));
}
}
/**缓存穿透
* 解决方式三:布隆过滤器(guava+redis)
* @param id
* @return
*/
@GetMapping("/getById-3")
public User getById_3(@RequestParam("id") String id) {
//判断布隆过滤器是否存在
if (!redisBloomFilter.contains(bfRedis, id, Integer.valueOf(id))) {
return null;
}
return getUser(REDIS_USER_KEY + id, id);
}
b)缓存空对象
1、简介
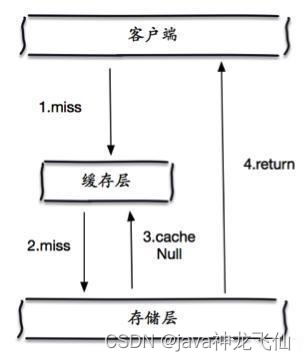
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;
但是这种方法会存在两个问题:
1、如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;
2、即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
2、实战
空对象:
@Data
public class NullEntity implements Serializable {
}
解决:
@Resource
private UserService userService;
@Resource//不能使用@Autowired,如果非要使用,不注明泛型类型即可
private RedisTemplate<String, Object> redisTemplate;
public static final String REDIS_USER_KEY = "user:id:";
/**缓存穿透
* 解决方式:缓存空对象
* 缓存空对象会带来比较大的问题,就是缓存中会存在很多空对象,
* 占用内存的空间,浪费资源,一个解决的办法就是设置空对象的较短的过期时间
* @param id
* @return
*/
@GetMapping("/getById-1")
public User getById_1(@RequestParam("id") String id) {
Object object = redisTemplate.opsForValue().get(REDIS_USER_KEY + id);
if (object != null) {
// 检验该对象是否为缓存空对象,是则直接返回null
if (object instanceof NullEntity) {
return null;
}
return (User) object;
} else {
log.info("查询数据库");
User user = userService.getById(id);
if (Objects.nonNull(user)) {
redisTemplate.opsForValue().set(REDIS_USER_KEY + id, user);
} else {
redisTemplate.opsForValue().set(REDIS_USER_KEY + id, new NullEntity(), 60, TimeUnit.SECONDS);
}
return user;
}
}
3、缓存击穿(量太大,缓存过期!)
1)概述
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
当某个key在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并且回写缓存,会导使数据库瞬间压力过大。
2)解决方案
a)设置热点数据永不过期
从缓存层面来看,没有设置过期时间,所以不会出现热点 key 过期后产生的问题。
b)加互斥锁
分布式锁:使用分布式锁,保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
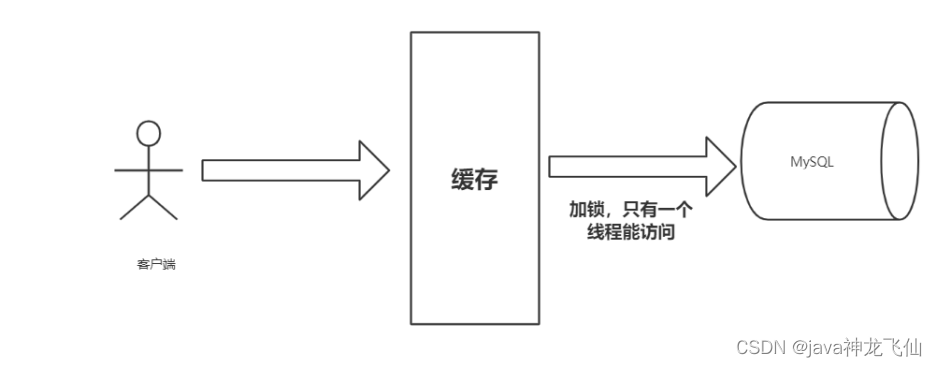
实战:使用redission加锁实现
依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.8.2</version>
</dependency>
配置:
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient getClient() {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
return redisson;
}
}
实现:
@Autowired
private RedissonClient redissonClient;
/**
* 缓存击穿方案:加锁
* @param id
* @return
*/
@GetMapping("/getById-4")
public User getById_4(@RequestParam("id") String id) {
Object object = redisTemplate.opsForValue().get(REDIS_USER_KEY + id);
if (object == null) {
User user = null;
RLock lock = redissonClient.getLock(REDIS_USER_LOCK_KEY + id);
try {
// 1. 最常见的使用方法
//lock.lock();
// 2. 支持过期解锁功能,10秒钟以后自动解锁, 无需调用unlock方法手动解锁
//lock.lock(10, TimeUnit.SECONDS);
// 3. 尝试加锁,最多等待3秒,上锁以后10秒自动解锁
boolean flag = lock.tryLock(3, 10, TimeUnit.SECONDS);
if (flag) {
log.info("查询数据库");
user = userService.getById(id);
if (Objects.nonNull(user)) {
redisTemplate.opsForValue().set(REDIS_USER_KEY + id, user);
}
return user;
}
} catch (Exception e) {
log.error("e={}", e.getMessage());
} finally {
lock.unlock();
}
return user;
}
return (User) object;
}
4、缓存雪崩
1)概念
缓存雪崩,是指在某一个时间段,缓存集中过期失效。Redis 宕机!
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
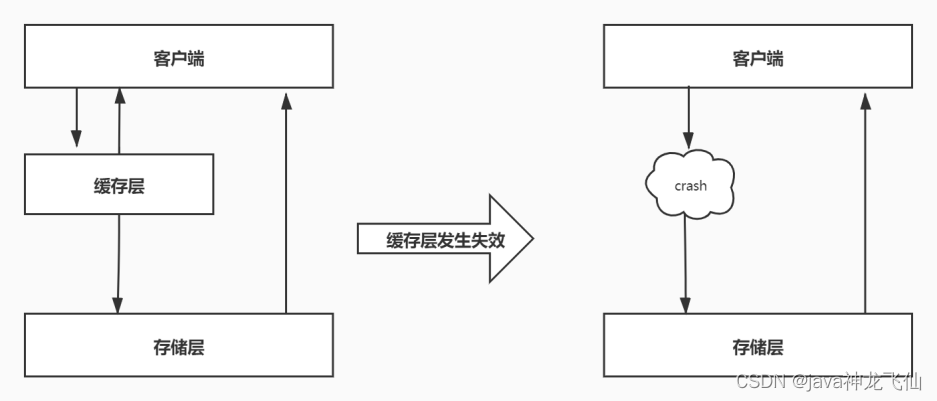
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
2)解决方案
a)redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。(异地多活!)
b)限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
c)数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
实战:设置随机的过期时间
private static final Long EXPIRE_TIME = 24 * 60 * 60L;
/**
* 缓存雪崩方案:设置随机的过期时间
* @param id
* @return
*/
@GetMapping("/getById-5")
public User getById_5(@RequestParam("id") String id) {
Object object = redisTemplate.opsForValue().get(REDIS_USER_KEY + id);
if (object == null) {
log.info("查询数据库");
User user = userService.getById(id);
if (Objects.nonNull(user)) {
redisTemplate.opsForValue()
.set(REDIS_USER_KEY + id,
user,
EXPIRE_TIME + RandomUtil.randomInt(60 * 5, 2 * 60 * 60),
TimeUnit.SECONDS);
}
return user;
}
return (User) object;
}















 6357
6357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









