









InnoDB的索引有两大类,一类是聚集索引(clustered index),另一类是普通索引(secondary index),也称二级索引。
聚集索引:叶子结点直接存储行记录,因此InnoDB必须有且仅有一个聚集索引。
1、如果表定义了pk,那么pk就是聚集索引。
2、如果表没有定义pk,那么第一个not null unique的列就是聚集索引。
3、否则InnoDB会另外创建一个隐藏的ROWID作为聚集索引。
聚集索引使得基于pk的查询速度非常快,直接定位行记录。
普通索引:普通索引的叶子结点存储主键值
什么是回表查询
假设先创建表t:
create table t(
id int primary key,
name varchar(16) not null,
set varchar(8),
flag int,
index (name)
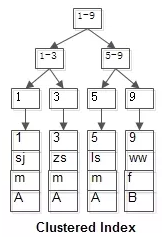
)engine = InnoDB;t表(id PK,name KEY,sex,flag),id为聚集索引,name为普通索引
| id | name | sex | flag |
|---|---|---|---|
| 1 | sj | m | A |
| 3 | zs | m | A |
| 5 | ls | m | A |
| 9 | ww | f | B |
聚集索引的B+树索引(id是PK,叶子结点存储行记录)
普通索引的B+树索引(name是KEY,叶子结点存储PK值,即id):
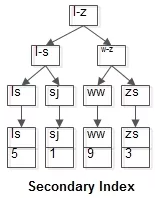
普通索引因为是定位行记录主键值id,查询过程通常是需要扫描两遍索引树。
select * from t where name='ls'这里的执行过程是这样的:
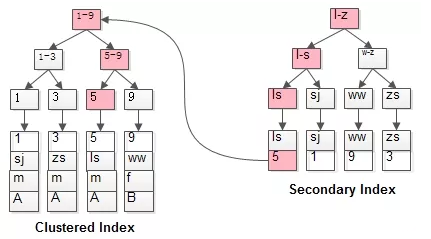
第一遍先通过普通索引定位到主键值id=5,第二遍再通过聚集索引定位到id=5的记录。
这种先根据普通索引定位主键,再根据主键定位行记录的称为回表查询。性能相对于只扫描聚集索引的查询较低。
索引覆盖:
索引覆盖是避免回表查询的优化策略,具体做法就是将要查询的数据作为索引列建立普通索引(可以是单列索引,也可以一个索引语句定义所有要查询的列,即联合索引)这样就直接返回索引中的数据,无需再次通过聚集索引去定位行记录。上表中做如下查询是没有回表的:
select name from t where name='ls'另外:并不是所有的类型的索引都可以成为覆盖索引的, 因为覆盖索引必须要存储索引的列值,而哈希索引、空间索引和全文索引等都不存储列值,所以mysql只能使用B-Tree作为覆盖索引。















 898
898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









