







| 1.1 什么是机器学习?
机器学习(Machine Learning)简称ML,它是一个研究领域,它使计算机能够在没有明确编程的情况下进行学习。ML 是人们曾经遇到过的最令人兴奋的技术之一。顾名思义,它赋予了计算机更接近人类的能力:学习能力。机器学习今天正在被积极使用,也许在比人们预期的更多的地方。

| 2.1 机器学习问题的类型
有多种方法可以对机器学习问题进行分类。在这里,我们讨论最明显的那些。
1. 基于学习系统可用的学习“信号”或“反馈”的性质 :
-
监督学习:向计算机展示由“老师”给出的示例输入及其所需的输出,目标是学习将输入映射到输出的一般规则。训练过程继续进行,直到模型在训练数据上达到所需的准确度。一些现实生活中的例子是:
-
图像分类:您使用图像/标签进行训练。然后在将来你给出一个新图像,期望计算机能够识别新对象。
-
市场预测/回归:你用历史市场数据训练计算机,并要求计算机预测未来的新价格。
-
-
无监督学习:没有给学习算法标签,让它自己在输入中找到结构。它用于对不同组中的人口进行聚类。无监督学习本身就是一个目标(发现数据中的隐藏模式)。
-
集群:您要求计算机将相似的数据分成集群,这在研究和科学中是必不可少的。
-
高维可视化:使用计算机帮助我们可视化高维数据。
-
生成模型:模型捕获输入数据的概率分布后,将能够生成更多数据。这对于使您的分类器更加健壮非常有用。
-
一个清晰的有监督和无监督学习概念的简单图表如下所示:
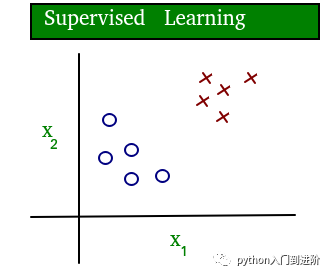
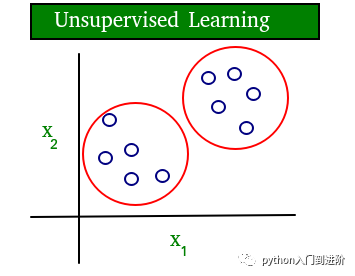
可以清楚地看到,监督学习中的数据是有标签的,而无监督学习中的数据是无标签的。
-
半监督学习:有大量输入数据并且只有部分数据被标记的问题,称为半监督学习问题。这些问题介于有监督学习和无监督学习之间。例如,一个照片档案,其中只有一些图像被标记(例如狗、猫、人),而大多数图像没有标记。
-
强化学习:计算机程序与必须执行特定目标(例如驾驶车辆或与对手玩游戏)的动态环境交互。该程序在导航其问题空间时会获得奖励和惩罚方面的反馈。
2. 基于机器学习系统所需的“输出”
-
分类:输入被分为两个或更多类,学习器必须生成一个模型,将看不见的输入分配给这些类中的一个或多个(多标签分类)。这通常以监督的方式解决。垃圾邮件过滤是分类的一个示例,其中输入是电子邮件(或其他)消息,类别是“垃圾邮件”和“非垃圾邮件”。
-
回归:这也是一个监督学习问题,但输出是连续的而不是离散的。例如,使用历史数据预测股票价格。
下面显示了两个不同数据集的分类和回归示例:
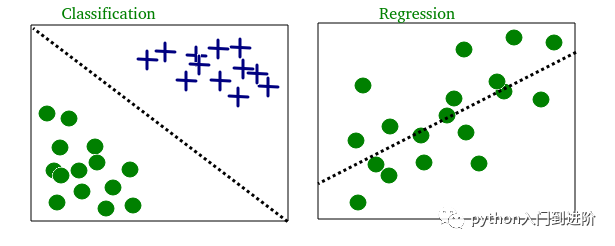
-
聚类:在这里,一组输入被分成组。与分类不同,这些组事先不知道,这通常是一项无监督的任务。
正如您在下面的示例中所见,给定的数据集点已被划分为可通过红色、绿色和蓝色识别的组。
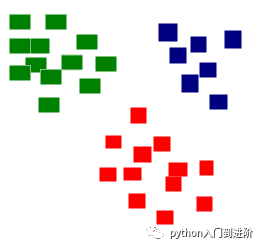
-
密度估计:任务是找到输入在某个空间中的分布。
-
降维:它通过将输入映射到低维空间来简化输入。主题建模是一个相关问题,其中给程序一个人类语言文档列表,并负责找出哪些文档涵盖了相似的主题。
在这些机器学习任务/问题的基础上,我们有许多算法用于完成这些任务。一些常用的机器学习算法有线性回归、逻辑回归、决策树、SVM(支持向量机)、朴素贝叶斯、KNN(K个最近邻)、K-Means、随机森林等。
Tips:所有这些算法都将在以后的文章中介绍。

| 2.2 机器学习术语(Terminologies of Machine Learning)
-
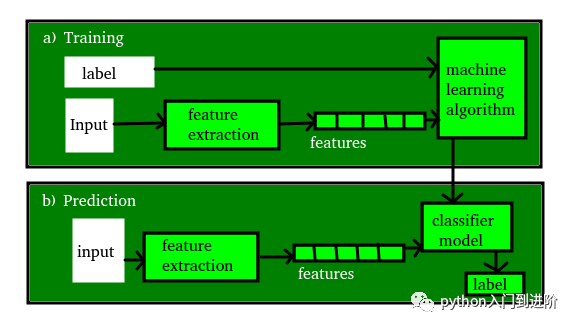
模型
模型是通过应用某种机器学习算法从数据中学习到的特定表示。模型也称为假设。 -
特征
特征是我们数据的一个单独的可测量属性。一组数字特征可以方便地用特征向量来描述。特征向量作为模型的输入。例如,为了预测一种水果,可能会有颜色、气味、味道等特征。
注意:选择信息丰富、有辨别力和独立的特征是有效算法的关键步骤。我们通常使用特征提取器从原始数据中提取相关特征。 -
目标(标签)
目标变量或标签是我们模型要预测的值。对于特征部分讨论的水果示例,每组输入的标签将是水果的名称,如苹果、橙子、香蕉等。 -
训练
这个想法是给出一组输入(特征)和它的预期输出(标签),所以在训练之后,我们将有一个模型(假设),然后将新数据映射到训练过的类别之一。 -
预测
一旦我们的模型准备好,它可以被提供一组输入,它将提供预测的输出(标签)。
Tips:下图清晰地阐述了了上述概念:
References:
-
https://en.wikipedia.org/wiki/Machine_learning
-
Andrew Ng. Machine Learning[EB/OL]. StanfordUniversity,2017.https://www.coursera.org/course/ml
| 3.1 写在最后
学习不是一蹴而就的,机器学习所涉及的内容非常宽泛,后面可能还会涉及一些数学公式。不过作为一种面向应用的方式方法,在不同的场景下同样有着不同的解决方式,希望这个系列能帮你了解算法,帮你打下坚实的基础。
勘误:
由于我自己也不是资深编程高手,在创作此内容时尽管已经力求精准,查阅了诸多资料,还是难保有所疏漏,如果各位发现有误可以公众号内留言,欢迎指正。
你要偷偷学Python,然后惊艳所有人。


-END-
感谢大家的关注
你关心的,都在这里















 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









