







Python与AI技术的结合为图像艺术创作开辟了全新维度,通过生成对抗网络(GANs)、扩散模型(如Stable Diffusion)和神经风格迁移等技术,创作者可以轻松生成具有高度创意和艺术性的图像作品。
这些技术不仅突破了传统艺术创作的局限性,还大幅降低了专业创作门槛,使艺术创作更加民主化。从2024到2025年,AI图像生成技术持续演进,特别是扩散模型在潜在空间优化和训练效率方面取得了显著突破,而神经风格迁移也通过Transformer架构实现了更精细的风格控制。

一、AI图像生成核心技术原理
生成对抗网络(GANs)作为图像生成领域的先驱,其核心由生成器和判别器两部分构成。
生成器通过接收随机噪声向量,尝试生成逼真的图像样本;判别器则对输入图像进行判断,区分真实图像和生成器的"赝品"。
这种对抗训练过程使生成器不断优化,最终能生成难以被区别的高质量图像。StyleGAN是GANs的改进版本,通过引入风格向量分层控制(如低层控制面部结构,高层控制细节纹理),显著提升了生成图像的多样性与质量。
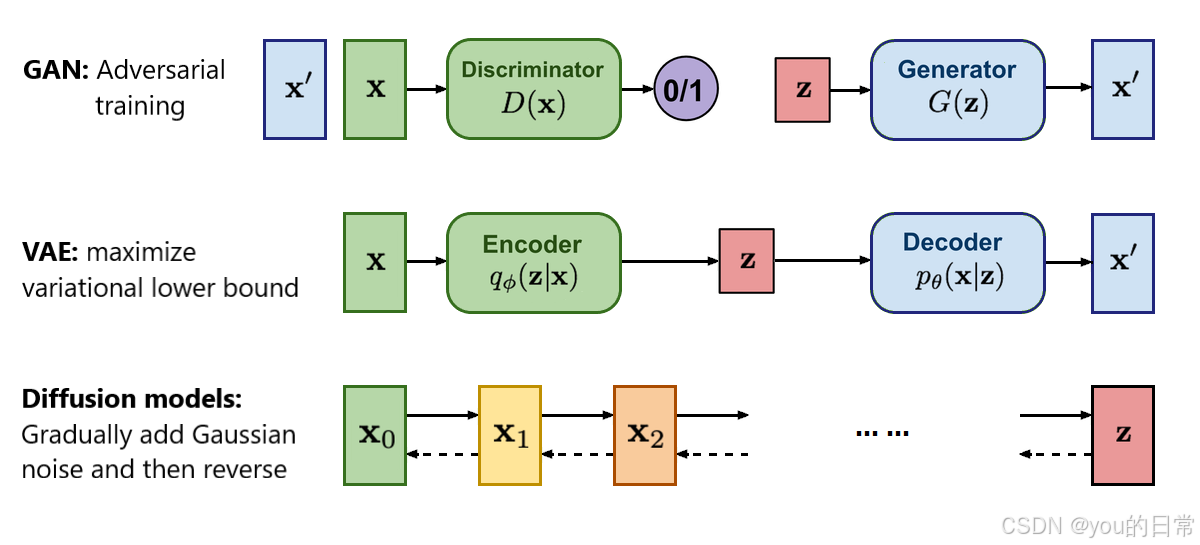
扩散模型(Diffusion Models)采用完全不同的生成策略,其核心是通过正向扩散过程逐步向图像添加高斯噪声,使其完全退化为随机噪声;然后通过反向扩散过程从噪声中逐步重建出原始图像。
这种渐进式去噪机制使扩散模型能够生成高质量图像,避免了GANs的"模式崩溃"问题。2025年最新研究中,VA-VAE方法通过将视觉词元分析器的潜在空间与预训练视觉基础模型对齐,解决了潜在扩散模型中的优化难题,使LightningDiT模型在ImageNet 256x256生成任务上取得了FID得分1.35的SOTA性能,训练效率比原始DiT提高21倍以上。
神经风格迁移(Neural Style Transfer)基于卷积神经网络(CNN)的特征提取能力,将内容图像的结构信息与风格图像的纹理、色彩信息分离并融合。 其核心是通过内容损失(均方误差)和风格损失(Gram矩阵差异)的联合优化实现风格转移。2025年,基于Transformer的StyTr²方法引入了内容感知位置编码(CAPE),能够捕捉图像块间的长距离依赖关系,解决了传统CNN在风格迁移中存在"内容泄漏"的问题,使风格迁移更加精准和自然。
| 技术类型 | 核心原理 | 优势 | 局限 |
|---|---|---|---|
| GANs | 生成器与判别器对抗训练 | 高质量图像生成,模式丰富 | 训练不稳定,模式崩溃风险 |
| 扩散模型 | 正向扩散与反向去噪双阶段 | 生成质量高,训练稳定 | 计算成本高,生成速度慢 |
| 神经风格迁移 | 内容与风格特征分离融合 | 精细风格控制,保留内容结构 | 风格与内容平衡困难 |
二、Python生态中的核心工具库
PyTorch 2.5和Diffusers库构成了当前AI图像生成的首选工具链,而OpenCV则提供了强大的图像预处理与后处理功能。
PyTorch 2.5对混合精度训练进行了优化,使大型生成模型的训练速度提升30%,并支持分布式训练,显著降低了硬件门槛。其Keras v3格式模型保存/重载功能进一步简化了模型部署流程。
Diffusers库作为Hugging Face官方推出的扩散模型工具箱,提供了完整的Stable Diffusion API,包括StableDiffusionPipeline、ControlNetPipeline等模块,支持从文本到图像、图像到图像等多种生成任务。
Stable Diffusion 3.0(SD3)是当前最先进的扩散模型之一,其参数量达860M(UNet)和123M(文本编码器),可在消费级GPU上运行,支持768x768分辨率图像生成,甚至通过潜在空间上采样生成2048x2048的超高分辨率图像。 SD3采用潜在空间扩散架构,将Autoencoder压缩的低维图像特征作为扩散过程的输入,大大降低了计算成本。在商业应用中,SD3 Medium版本被广泛采用,它通过去除47亿参数的T5-XXL文本编码器,以牺牲少量图像质量为代价,显著提升了推理速度。
OpenCV在图像风格迁移中扮演着重要角色,其dnn模块可加载预训练的风格迁移模型(如Torch的.t7文件),实现图像的快速风格化处理。 例如,通过加载"starry_night.t7"模型,OpenCV可在短短几秒内将普通图像转换为梵高《星夜》风格的艺术作品。在与深度学习结合的场景中,OpenCV常用于图像的预处理(如缩放、归一化)和后处理(如增强、修复),为AI生成图像提供额外的艺术修饰。
三、Stable Diffusion生成创意海报案例
Stable Diffusion生成创意海报的核心在于通过多ControlNet组件协同控制和参数优化,实现内容与风格的精准结合。
一个典型的海报生成工作流包括:环境配置、ControlNet组件加载、图像预处理、参数配置和图像生成。在2025年最新实践中,使用Stable Diffusion 3.0 Medium版本配合ControlNet插件已成为行业标准,其优势在于能够生成高保真图像,同时保持相对合理的推理速度。
以下是基于Diffusers库实现Stable Diffusion海报生成的完整代码示例:
import torch
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
from diffusers.utils import load_image
from transformers import pipeline
import numpy as np
import cv2
from PIL import Image
# 准备环境
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 加载ControlNet组件
controlnet_depth = ControlNetModel.from_pretrained(
"lllyasviel/control_v11f1p_sd15_depth",
torch_dtype=torch. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1646
1646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









