










在我的上一篇博文中:http://blog.csdn.net/zfszhangyuan/article/details/52538108 讲如何应用scala编程完成用户的在线时长和登录次数在spark上的求解方式。
讲到这里有同学可能对编程完后如何将程序放到线上spark集群上运行以及如何理解spark框架在大数据架构体系中的位置及其基本原理有所疑问。
今天就主要来聊聊这两个方面:
1、我们首先要将上一篇博文中的程序打成一个jar包,我们就命名为sparkApp.jar,然后将这个jar包传到集群机器的测试目录下(要保证机器能访问到此文件),最后我们用spark-submit 命令完成此jar包的运行,下面给出详细代码(其中我们设置了运行类和on-yarn模式以及运行的内存和executors数,运行的输入路径和输出路径等)
spark-submit --class com.besttone.UserOnlineAnalysis --master yarn-client --executor-memory 2g --num-executors 3 file:///home/hadoop/test/sparkApp.jar test/apponoff.bz2 test/out22
Apache Spark is an open source cluster computing system that aims to make date analytics fast ----both fast to run and fast to write.
基本意思就是一个开源的云计算系统,宗旨就是为了提高数据分析的速度无论是计算速度还是数据写的速度。
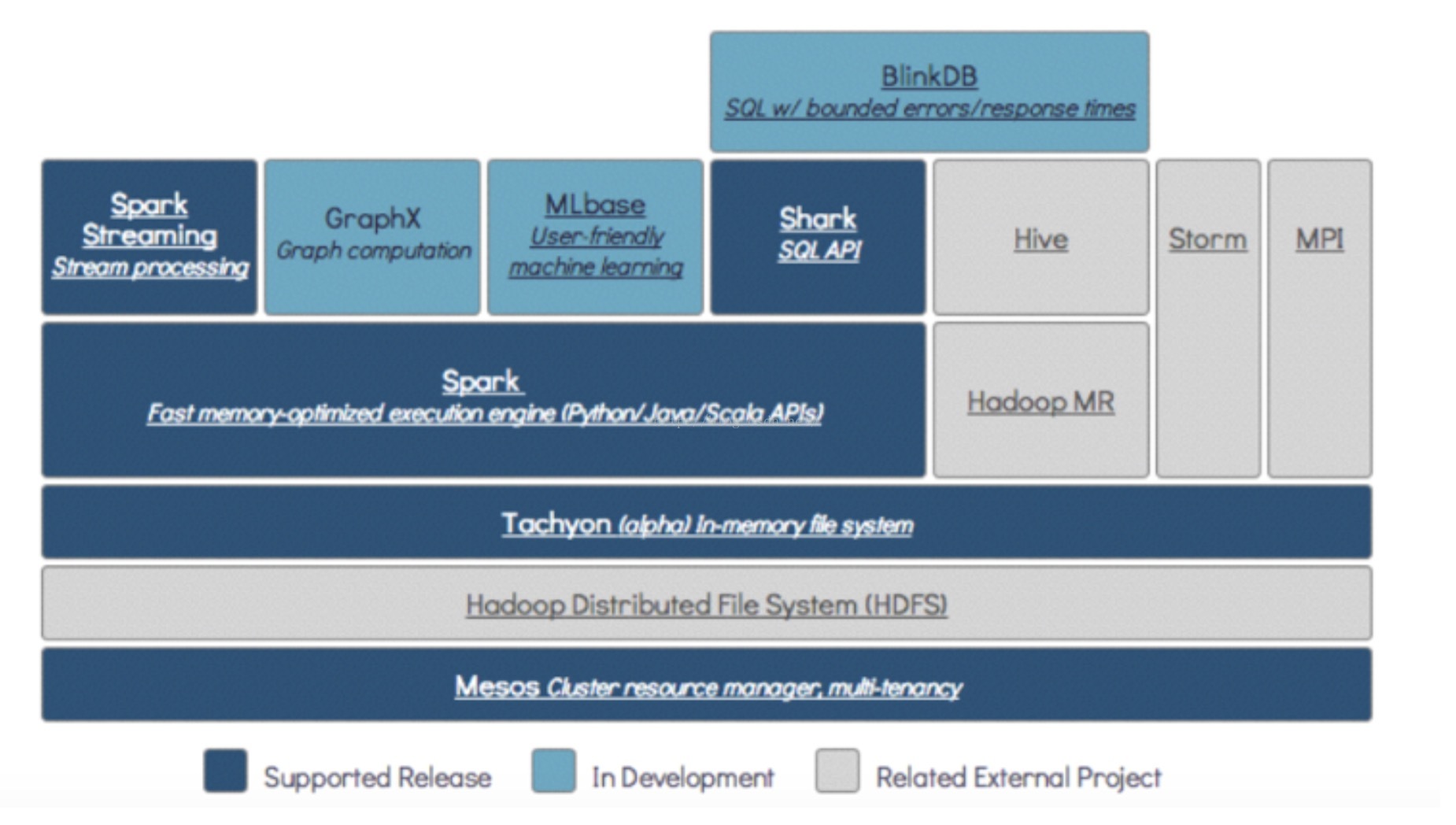
上面是spark云计算系统在大数据架构中的位置,可以看出基本上可以用另辟蹊径来形容,和hadoop MR,hive以及storm走的是完全不一样的计算架构。
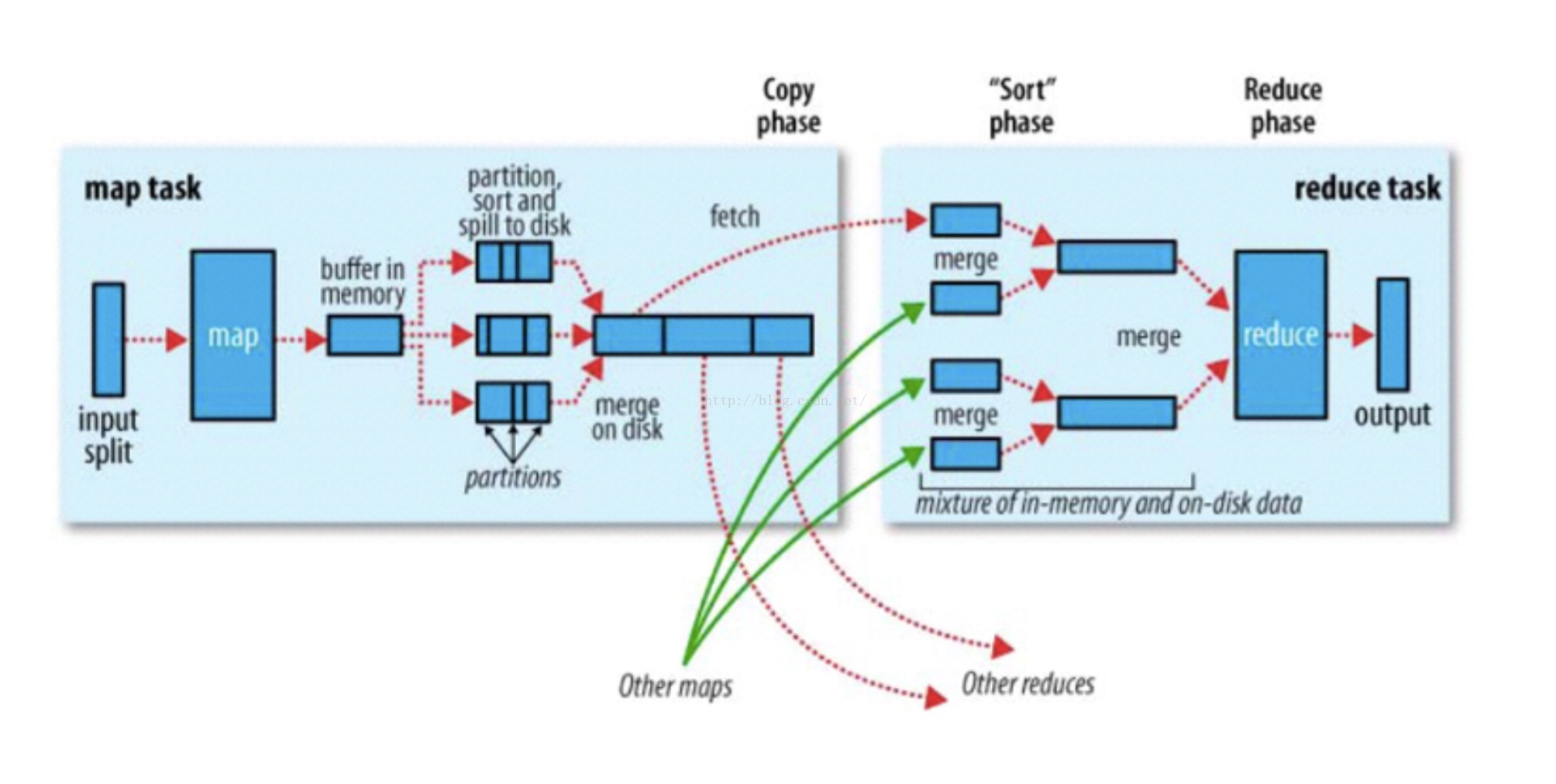
这个是MR的数据处理流程图,我们可以看到数据的处理过程中几进几出磁盘,并且被不断的被迁移多次,这就导致MR处理数据非常的慢(额外的复制,序列化和磁盘IO开销)。
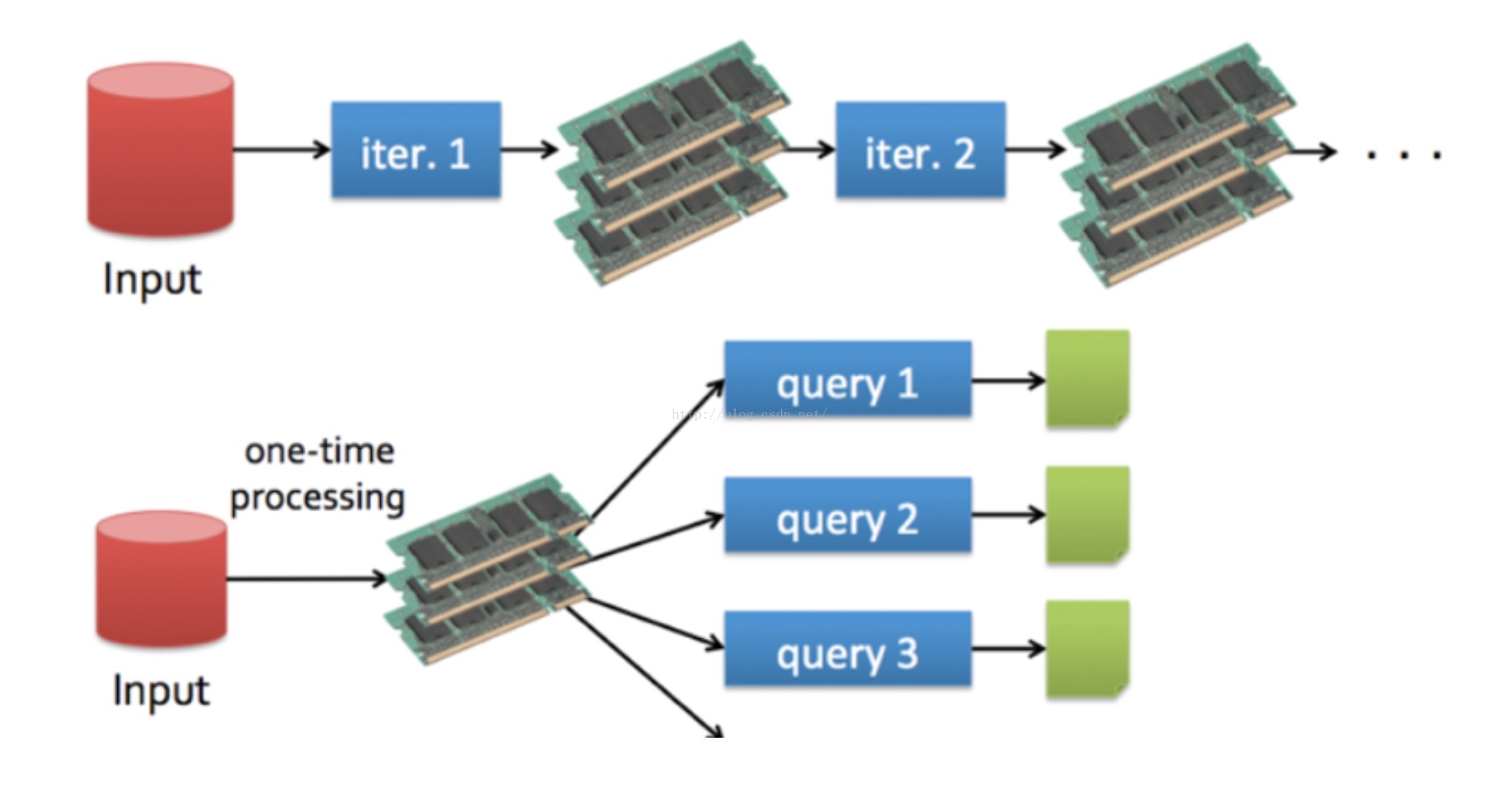
在来看看spark运行过程数据的走向图,可以看到数据基本全部都是在内存中进行,无需落地。spark快并非仅仅是因为内存计算还有重要的一点是其DAG的优化,什么呢,就是其在做一个数据计算的过程中,会将整个计算过程每一步RDD的形成做一个优化形成一个有向无环图的scheduler。按照优化过的DAG图运行会避免很多重复计算和数据迁移等。
好了,到这里大家对spark基本上有了一个宏观上的理解了。
下面谈谈spark运行的核心数据单元RDD
RDD定义:分布式弹性数据集。
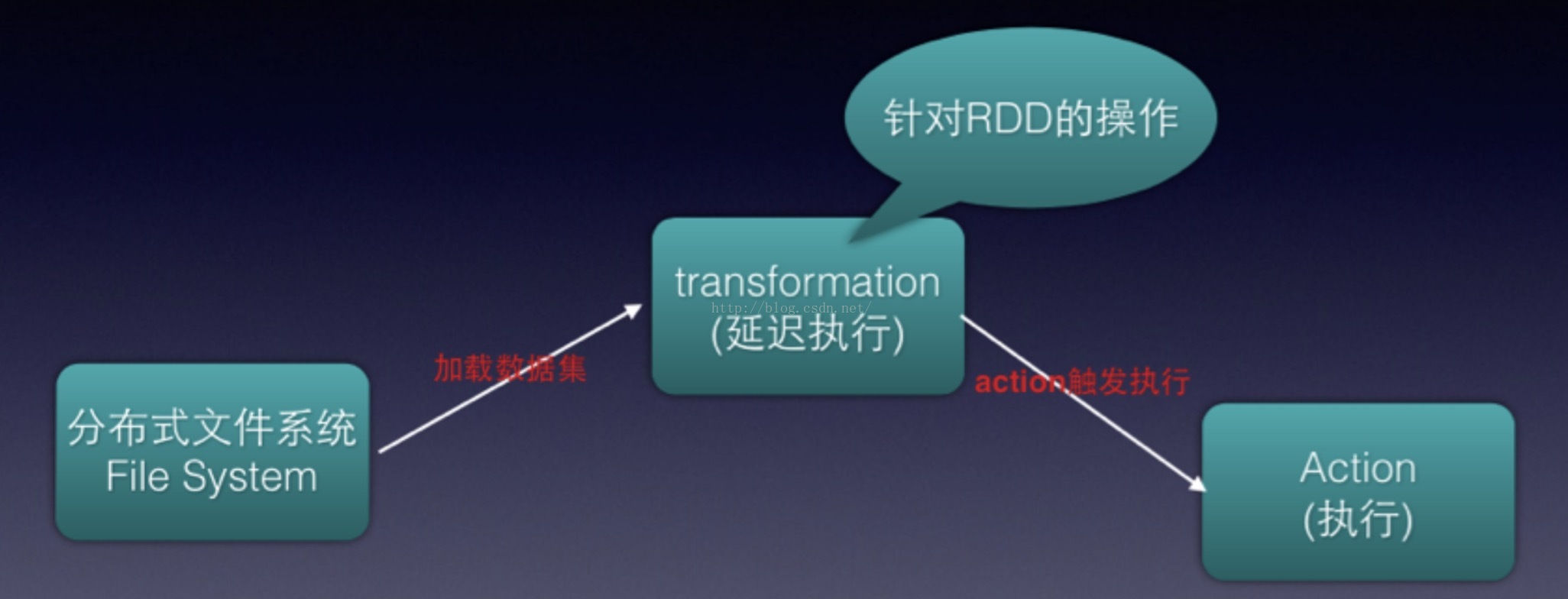
spark运行基本就包含上面两个步骤第一个是transformation,另外一个是Action。

以上是已经封装好的函数或者说是接口。
下面就具体说说这些函数的运用和编程:(以下代码是借鉴过来讲解一下,注意下面的代码都是在安装了spark的集群上运行的,输入spark-shell后操作的)
1、加载文件
scala> val inFile = sc.textFile("/home/scipio/spam.data") //这一步相当于将数据加载到内存变成RDD输出
14/06/28 12:15:34 INFO MemoryStore: ensureFreeSpace(32880) called with curMem=65736, maxMem=31138775014/06/28 12:15:34 INFO MemoryStore: Block broadcast_2 stored as values to memory (estimated size 32.1 KB, free 296.9 MB)
inFile: org.apache.spark.rdd.RDD[String] = MappedRDD[7] at textFile at <console>:122、显示一行
scala> inFile.first()输出
14/06/28 12:15:39 INFO FileInputFormat: Total input paths to process : 114/06/28 12:15:39 INFO SparkContext: Starting job: first at <console>:1514/06/28 12:15:39 INFO DAGScheduler: Got job 0 (first at <console>:15) with 1 output partitions (allowLocal=true)
14/06/28 12:15:39 INFO DAGScheduler: Final stage: Stage 0(first at <console>:15)
14/06/28 12:15:39 INFO DAGScheduler: Parents of final stage: List()
14/06/28 12:15:39 INFO DAGScheduler: Missing parents: List()
14/06/28 12:15:39 INFO DAGScheduler: Computing the requested partition locally
14/06/28 12:15:39 INFO HadoopRDD: Input split: file:/home/scipio/spam.data:0+34917014/06/28 12:15:39 INFO SparkContext: Job finished: first at <console>:15, took 0.532360118 s
res2: String = 0 0.64 0.64 0 0.32 0 0 0 0 0 0 0.64 0 0 0 0.32 0 1.29 1.93 0 0.96 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.778 0 0 3.756 61 278 13、函数运用
(1)map:其实就可以理解为映射,但是这种映射逻辑我们可以自己定义,比如下面的映射逻辑就是先将RDD中的数据按照空格进行分割,然后对每个元素再进行映射转化成Double型。(可以看出结果由原来的string变成一个Arraylist包含double型的数据)
scala> val nums = inFile.map(x=>x.split(' ').map(_.toDouble))
nums: org.apache.spark.rdd.RDD[Array[Double]] = MappedRDD[8] at map at <console>:14
scala> nums.first()
14/06/28 12:19:07 INFO SparkContext: Starting job: first at <console>:1714/06/28 12:19:07 INFO DAGScheduler: Got job 1 (first at <console>:17) with 1 output partitions (allowLocal=true)
14/06/28 12:19:07 INFO DAGScheduler: Final stage: Stage 1(first at <console>:17)
14/06/28 12:19:07 INFO DAGScheduler: Parents of final stage: List()
14/06/28 12:19:07 INFO DAGScheduler: Missing parents: List()
14/06/28 12:19:07 INFO DAGScheduler: Computing the requested partition locally
14/06/28 12:19:07 INFO HadoopRDD: Input split: file:/home/scipio/spam.data:0+34917014/06/28 12:19:07 INFO SparkContext: Job finished: first at <console>:17, took 0.011412903 s
res3: Array[Double] = Array(0.0, 0.64, 0.64, 0.0, 0.32, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.64, 0.0, 0.0, 0.0, 0.32, 0.0, 1.29, 1.93, 0.0, 0.96, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.778, 0.0, 0.0, 3.756, 61.0, 278.0, 1.0)(2)collect 属于action函数,可以理解其是将起码RDD的处理结果收集放到一个Array中。
scala> val rdd = sc.parallelize(List(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at <console>:12
scala> val mapRdd = rdd.map(2*_)
mapRdd: org.apache.spark.rdd.RDD[Int] = MappedRDD[10] at map at <console>:14
scala> mapRdd.collect
14/06/28 12:24:45 INFO SparkContext: Job finished: collect at <console>:17, took 1.789249751 s
res4: Array[Int] = Array(2, 4, 6, 8, 10)(3)filter 过滤函数,你可以自己定义自己的过滤规则,比如包含什么 _.contain() ,不包含什么 !_.contain() 等等,下面是过滤掉<=5的数据。
scala> val filterRdd = sc.parallelize(List(1,2,3,4,5)).map(_*2).filter(_>5)
filterRdd: org.apache.spark.rdd.RDD[Int] = FilteredRDD[13] at filter at <console>:12
scala> filterRdd.collect
14/06/28 12:27:45 INFO SparkContext: Job finished: collect at <console>:15, took 0.056086178 s
res5: Array[Int] = Array(6, 8, 10)(4)flatMap这是做一次扁平化处理,其操作通俗来讲就是将一个含有大量嵌套array变成一个大array,每个子array元素都变成独立的元素,方便后续处理。(Array[Array[String]]---->Array[String]) flatMap之后的collect的结果是Array[String],其实是先map后flat的过程。先map产生了Array[Array[String]],然后又经过flat合并成了Array[String]。在文件中保存的结果是每一个分割后的单词。
scala> val rdd = sc.textFile("/home/scipio/README.md")
14/06/28 12:31:55 INFO MemoryStore: ensureFreeSpace(32880) called with curMem=98616, maxMem=31138775014/06/28 12:31:55 INFO MemoryStore: Block broadcast_3 stored as values to memory (estimated size 32.1 KB, free 296.8 MB)
rdd: org.apache.spark.rdd.RDD[String] = MappedRDD[15] at textFile at <console>:12
scala> rdd.count
14/06/28 12:32:50 INFO SparkContext: Job finished: count at <console>:15, took 0.341167662 s
res6: Long = 127
scala> rdd.cache
res7: rdd.type = MappedRDD[15] at textFile at <console>:12
scala> rdd.count
14/06/28 12:33:00 INFO SparkContext: Job finished: count at <console>:15, took 0.32015745 s
res8: Long = 127
scala> val wordCount = rdd.flatMap(_.split(' ')).map(x=>(x,1)).reduceByKey(_+_)
wordCount: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[20] at reduceByKey at <console>:14
scala> wordCount.collect
res9: Array[(String, Int)] = Array((means,1), (under,2), (this,4), (Because,1), (Python,2), (agree,1), (cluster.,1), (its,1), (YARN,,3), (have,2), (pre-built,1), (MRv1,,1), (locally.,1), (locally,2), (changed,1), (several,1), (only,1), (sc.parallelize(1,1), (This,2), (basic,1), (first,1), (requests,1), (documentation,1), (Configuration,1), (MapReduce,2), (without,1), (setting,1), ("yarn-client",1), ([params]`.,1), (any,2), (application,1), (prefer,1), (SparkPi,2), (<http://spark.apache.org/>,1), (version,3), (file,1), (documentation,,1), (test,1), (MASTER,1), (entry,1), (example,3), (are,2), (systems.,1), (params,1), (scala>,1), (<artifactId>hadoop-client</artifactId>,1), (refer,1), (configure,1), (Interactive,2), (artifact,1), (can,7), (file's,1), (build,3), (when,2), (2.0.X,,1), (Apac...
scala> wordCount.saveAsTextFile("/home/scipio/wordCountResult.txt")(5)union求两个数据集的并集
scala> val rdd = sc.parallelize(List(('a',1),('a',2)))
rdd: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[10] at parallelize at <console>:12
scala> val rdd2 = sc.parallelize(List(('b',1),('b',2)))
rdd2: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[11] at parallelize at <console>:12
scala> rdd union rdd2
res3: org.apache.spark.rdd.RDD[(Char, Int)] = UnionRDD[12] at union at <console>:17
scala> res3.collect
res4: Array[(Char, Int)] = Array((a,1), (a,2), (b,1), (b,2))(6) join:按照每个单元素的key做join映射
scala> val rdd1 = sc.parallelize(List(('a',1),('a',2),('b',3),('b',4)))
rdd1: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[10] at parallelize at <console>:12
scala> val rdd2 = sc.parallelize(List(('a',5),('a',6),('b',7),('b',8)))
rdd2: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[11] at parallelize at <console>:12
scala> rdd1 join rdd2
res1: org.apache.spark.rdd.RDD[(Char, (Int, Int))] = FlatMappedValuesRDD[14] at join at <console>:17
res1.collect
res2: Array[(Char, (Int, Int))] = Array((b,(3,7)), (b,(3,8)), (b,(4,7)), (b,(4,8)), (a,(1,5)), (a,(1,6)), (a,(2,5)), (a,(2,6)))(7)lookup 按照key进行查找,输出value的集合
val rdd1 = sc.parallelize(List(('a',1),('a',2),('b',3),('b',4)))
rdd1.lookup('a')
res3: Seq[Int] = WrappedArray(1, 2)(8)groupByKey 按照key做聚合,其和reducebykey不同的是,key相同的,其对于的value都放到一个arraybuffer中不会做sum操作,而reducebykey就会对key相关的value做sum操作得出一个value值。(大家可以试试)
val wc = sc.textFile("/home/scipio/README.md").flatMap(_.split(' ')).map((_,1)).groupByKey
wc.collect
14/06/28 12:56:14 INFO SparkContext: Job finished: collect at <console>:15, took 2.933392093 s
res0: Array[(String, Iterable[Int])] = Array((means,ArrayBuffer(1)), (under,ArrayBuffer(1, 1)), (this,ArrayBuffer(1, 1, 1, 1)), (Because,ArrayBuffer(1)), (Python,ArrayBuffer(1, 1)), (agree,ArrayBuffer(1)), (cluster.,ArrayBuffer(1)), (its,ArrayBuffer(1)), (YARN,,ArrayBuffer(1, 1, 1)), (have,ArrayBuffer(1, 1)), (pre-built,ArrayBuffer(1)), (MRv1,,ArrayBuffer(1)), (locally.,ArrayBuffer(1)), (locally,ArrayBuffer(1, 1)), (changed,ArrayBuffer(1)), (sc.parallelize(1,ArrayBuffer(1)), (only,ArrayBuffer(1)), (several,ArrayBuffer(1)), (This,ArrayBuffer(1, 1)), (basic,ArrayBuffer(1)), (first,ArrayBuffer(1)), (documentation,ArrayBuffer(1)), (Configuration,ArrayBuffer(1)), (MapReduce,ArrayBuffer(1, 1)), (requests,ArrayBuffer(1)), (without,ArrayBuffer(1)), ("yarn-client",ArrayBuffer(1)), ([params]`.,Ar...(9)sortByKey:此实例中做了reducebykey操作目的就是为了统计单词的数量,因为我们为每个单词value赋值为1了,然后按key排序 倒序 由多到少排序。
val rdd = sc.textFile("/home/scipio/README.md")
val wordcount = rdd.flatMap(_.split(' ')).map((_,1)).reduceByKey(_+_)
val wcsort = wordcount.map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1))
wcsort.saveAsTextFile("/home/scipio/sort.txt")升序的话,sortByKey(true)















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









