







本文sql训练题,请参考此库:
链接:https://pan.baidu.com/s/1h8YknMHSvuBNUDX3EH26pQ
提取码:6666
1、SQL介绍
结构化查询语言
5.7 以后符合SQL92严格模式
通过sql_mode参数来控制
2、常用SQL分类
DDL:数据定义语言
DCL:数据控制语言
DML:数据操作语言
DQL:数据查询语言
SQL_MODE:
| ONLY_FULL_GROUP_BY | 对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么这个SQL是不合法的,因为列不在GROUP BY从句中 |
| NO_AUTO_VALUE_ON_ZERO | 该值影响自增长列的插入。默认设置下,插入0或NULL代表生成下一个自增长值。如果用户希望插入的值为0,而该列又是自增长的,那么这个选项就有用了 |
| STRICT_TRANS_TABLES | 在该模式下,如果一个值不能插入到一个事务中,则中断当前的操作,对非事务表不做限制 |
| NO_ZERO_IN_DATE | 在严格模式下,不允许日期和月份为零 |
| NO_ZERO_DATE | 设置该值,mysql数据库不允许插入零日期,插入零日期会抛出错误而不是警告 |
| ERROR_FOR_DIVISION_BY_ZERO | 在insert或update过程中,如果数据被零除,则产生错误而非警告。如果未给出该模式,那么数据被零除时Mysql返回NULL |
| NO_AUTO_CREATE_USER | 禁止GRANT创建密码为空的用户 |
| NO_ENGINE_SUBSTITUTION | 如果需要的存储引擎被禁用或未编译,那么抛出错误。不设置此值时,用默认的存储引擎替代,并抛出一个异常 |
| PIPES_AS_CONCAT | 将"||"视为字符串的连接操作符而非或运算符,这和Oracle数据库是一样是,也和字符串的拼接函数Concat想类似 |
| ANSI_QUOTES | 启用ANSI_QUOTES后,不能用双引号来引用字符串,因为它被解释为识别符 |
3、数据类型、表属性、字符集
3.1 数据类型
3.1.1 作用
保证数据的准确性和标准性。
3.1.2 种类
数值类型
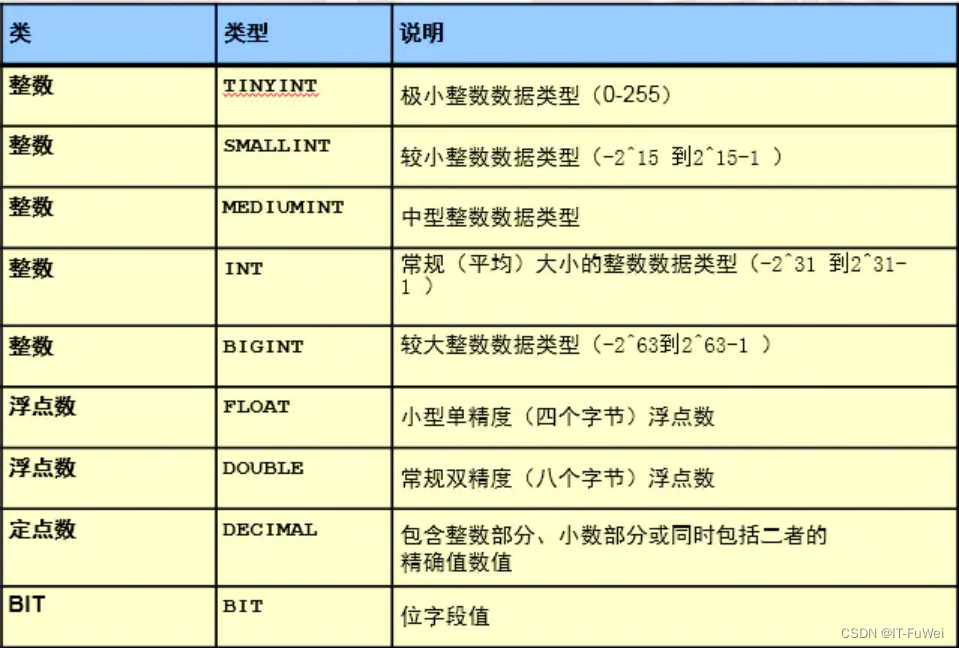
tinyint : -128~127
int :-2^31~2^31-1
说明:手机号是无法存储到int的。一般是使用char类型来存储收集号
字符类型

char(11) :
定长的字符串类型,在存储字符串时,最大字符长度11个,立即分配11个字符长度的存储空间,如果存不满,空格填充。
varchar(11):
变长的字符串类型看,最大字符长度11个。在存储字符串时,自动判断字符长度,按需分配存储空间。
补充:
1.varchar类型,在存储数据时,会先判断字符长度,然后合理分配存储空间,
而char类型不需要判断,一次性分配空间,效率会较高
2.varchar类型,除了会存储字符串之外,还会额外使用1-2个字节存储字符长度,
例如:abcdef –->6+1
aaaaaaaaaaaaaaaaaaa….254 - ->254+1
aaaaaaaaaaaaaaaaaa…1000 - ->1000+2
3.应用场景
字符创固定长度的使用char类型,不固定的话使用varchar;
4.括号中数字问题
括号中,设置的是字符的个数,无关字符类型;
但是,不同种类的字符,占用的存储空间是不一样的,
对于英文和数字,每个字节占1个字节长度
对于中文,占用空间太大,要考虑字符集
Utf8.utf8mb4,每个中文占3个字节长度,emoji字符,占4个字节长度;
enum('bj','tj','sh'):
枚举类型,比较适合于将来此列的值是固定范围内的特点,可以使用enum,可以很大程度的优化我们的索引结构。
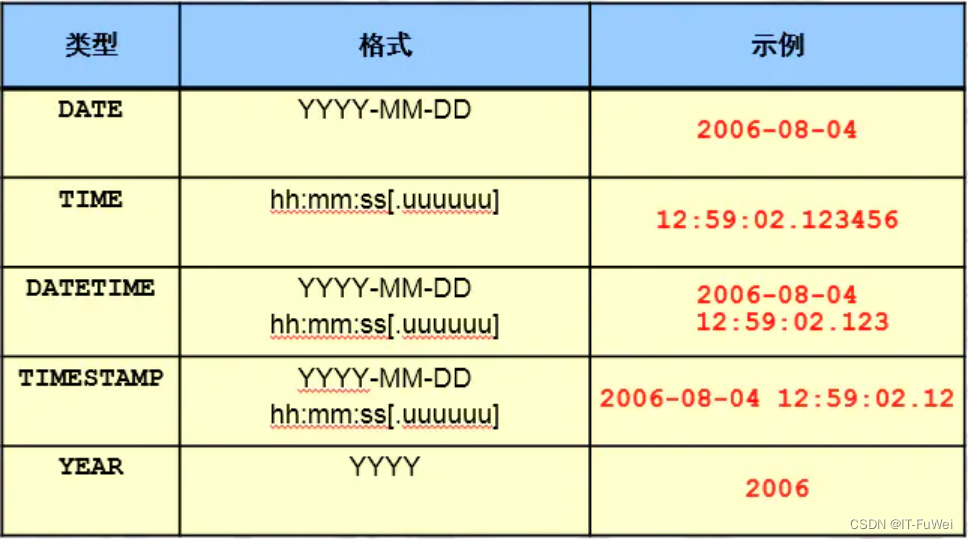
时间类型
列值不能为空,也是表设计的规范,尽可能将所有的列设置为非空。可以设置默认值为0
unique key :唯一键
列值不能重复
unsigned :无符号
针对数字列,非负数。
其他属性:
key :索引
可以在某列上建立索引,来优化查询
DATETIME
范围为从 1000-01-01 00:00:00.000000 至 9999-12-31 23:59:59.999999。
TIMESTAMP
1970-01-01 00:00:00.000000 至 2038-01-19 03:14:07.999999。
timestamp会受到时区的影响
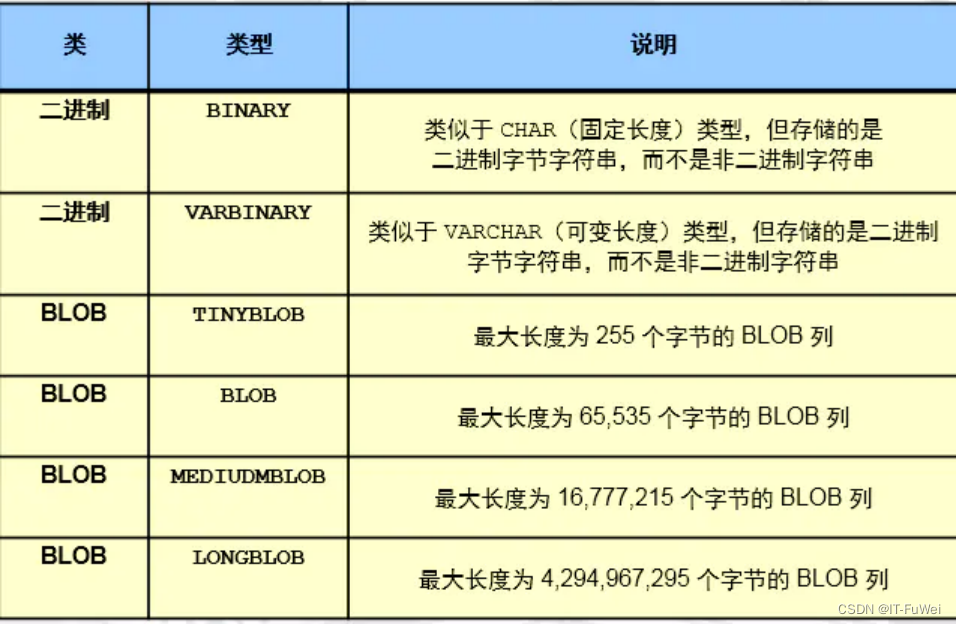
二进制类型
3.2 表属性
3.2.1 列属性
约束(一般建表时添加):
**primary key** :主键约束
设置为主键的列,此列的值必须非空且唯一,主键在一个表中只能有一个,但是可以有多个列一起构成。
**not null** :非空约束
列值不能为空,也是表设计的规范,尽可能将所有的列设置为非空。可以设置默认值为0
**unique key** :唯一键
列值不能重复
**unsigned** :无符号
针对数字列,非负数。
其他属性:
**key** :索引
可以在某列上建立索引,来优化查询,一般是根据需要后添加
**default** :默认值
列中,没有录入值时,会自动使用default的值填充
**auto_increment**:自增长
针对数字列,顺序的自动填充数据(默认是从1开始,将来可以设定起始点和偏移量)
**comment ** : 注释
3.2.2 表的属性
存储引擎:
InnoDB(默认的)
字符集和排序规则:
utf8
utf8mb4
3.3 字符集和校对规则
3.3.1 字符集
utf8
utf8mb4
区别:
utf8:最大存储长度,单个字符最多3个字节
utf8mb4:最大存储长度,单个字符最多4个字节
举例:
Emoji字符mb4支持,utf8不支持,emoji表情字符,1个字符占4个字节,utf8存不下;
3.3.2 校对规则(排序规则)
show collation; #查询校对规则
大小写是否敏感4、DDL应用
4.1 数据定义语言
4.2 库定义
4.2.1 创建
4.2.1 创建数据库
create database school;
create schema sch;
show charset;
show collation;
CREATE DATABASE test CHARSET utf8;
create database xyz charset utf8mb4 collate utf8mb4_bin;
建库规范:
1.库名不能有大写字母
2.建库要加字符集
3.库名不能有数字开头
4.库名要和业务相关建库标准语句
mysql> create database db charset utf8mb4;
mysql> show create database xuexiao;4.2.2 删除(生产中禁止使用)
mysql> drop database oldboy;4.2.3 修改
SHOW CREATE DATABASE school;
ALTER DATABASE school CHARSET utf8;
注意:修改字符集,修改后的字符集一定是原字符集的严格超集4.2.4 查询库相关信息(DQL)
show databases;
show create database oldboy;4.3 表定义
4.3.1 创建
create table stu(
列1 属性(数据类型、约束、其他属性) ,
列2 属性,
列3 属性
)4.3.2 建表
USE school;
CREATE TABLE stu(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(255) NOT NULL COMMENT '姓名',
sage TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '年龄',
sgender ENUM('m','f','n') NOT NULL DEFAULT 'n' COMMENT '性别' ,
sfz CHAR(18) NOT NULL UNIQUE COMMENT '身份证',
intime TIMESTAMP NOT NULL DEFAULT NOW() COMMENT '入学时间'
) ENGINE=INNODB CHARSET=utf8 COMMENT '学生表';建表规范:
1. 建表时,表名小写, 建议格式: wp_user,不要出现数字开头和大写字母
2. 显式的设置存储引擎\字符集\表的注释.
3. 列名要和业务有关
4. 列的数据类型,讲究:完整\简短\合适,精度不高浮点数,放大N倍.
5. 每个表必须要有主键,数字自增无关列.
6. 每个列尽量是非空的,而且设置默认值.
7. 每个列要有注释.
8. 变长列,一般选择varchar类型,定长列一般选择char.
9. 大字段,可以选择附件形式,可以选择ES.
10. 对于Online-DDL ,对于追加方式添加列,可以online,添加索引可以online(8.0),其他情况下,需要在数据库低谷时间点去做.如果很紧急,pt-osc或者gh-ost
4.3.2 删除(生产中禁用命令)
drop table t1;4.3.3 修改
1.在stu表中添加qq列
DESC stu;
ALTER TABLE stu ADD qq VARCHAR(20) NOT NULL UNIQUE COMMENT 'qq号';2.在sname后加微信列
ALTER TABLE stu ADD wechat VARCHAR(64) NOT NULL UNIQUE COMMENT '微信号' AFTER sname ;3.在id列前加一个新列num.
ALTER TABLE stu ADD num INT NOT NULL COMMENT '数字' FIRST;
DESC stu;4.把刚才添加的列都删掉(危险)
ALTER TABLE stu DROP num;
ALTER TABLE stu DROP qq;
ALTER TABLE stu DROP wechat;5.修改sname数据类型的属性
ALTER TABLE stu MODIFY sname VARCHAR(128) NOT NULL ;6.将sgender 改为 sg 数据类型改为 CHAR 类型
ALTER TABLE stu CHANGE sgender sg CHAR(1) NOT NULL DEFAULT 'n' ;
DESC stu;7.修改列的顺序(属性必须一样)
mysql> alter table student modify `sgender` enum('m','f','n') NOT NULL DEFAULT 'n' COMMENT '性别' first; #移动sgender列到首列
mysql> alter table student modify `sgender` enum('m','f','n') NOT NULL DEFAULT 'n' COMMENT '性别' after id; 移动sgender列到ID后面4.3.4 表属性查询(DQL)
use school
show tables;
desc stu;
show create table stu;
CREATE TABLE ceshi LIKE stu;5. DCL应用 ****
5.1 GRANT - 授权
将指定
操作对象的指定操作权限授予指定的用户; 发出该 GRANT语句的可以是数据库管理员,也可以是该数据库对象的创建者;
5.1.1 查询
查看用户自己权限
SHOW GRANTS;查看其他用户权限
SHOW GRANTS FOR 'user'@'host';Tips: host 可以使用通配符 %;如 'user'@'%', 'user'@'192.168.0.%';
5.1.2 授权
语法
GRANT 权限 ON 数据库对象 TO 用户 [WITH GRANT OPTION];例子
授予 super用户所有权限
GRANT ALL [PRIVILEGES] ON . TO 'user'@'%';授予用户 INSERT 权限
CREATE INSERT ON db_name.* TO 'user'@'%' IDENTIFIED BY 'newpasswd';授予用户 SELECT, UPDATE, DELETE 权限
GRANT SELECT, UPDATE, DELETE ON db_name.* TO 'user'@'localhost'5.1.3 刷新
FLUSH PRIVILEGES;Tips:
WITH GRANT OPTION: 表示是否能传播其权限;(授权命令是由数据库管理员使用的)- 指定
WITH GRANT OPTION,则获得该权限的用户可以把这种权限授予其他用户;但不允许循环传授,即被授权者不能把权限在授回给授权者或祖先; - 未指定,则获得某种权限的用户只能自己使用该权限,不能传播该权限;
- 指定
- 在
GRANT关键字之后指定一个或多个特权。如果要授予用户多个权限,则每个权限都将以逗号分隔(见下表中的特权列表); - 指定确定特权应用级别的privilege_level;
- MySQL支持全局(
*.*),数据库(database.*),表(database.table)和列级别; - 如果您使用列权限级别,则必须在每个权限之后使用
逗号分隔列的列表;
- MySQL支持全局(
- 如果授予权限的用户已经存在,则GRANT语句修改其特权; 如不存在,则GRANT语句将创建一个新用户; 可选的条件
IDENTIFIED BY允许为用户设置新密码;
5.2 REVOKE - 回收授权
语法
REVOKE 权限 ON 数据库对象 FROM 用户 [CASCADE | RESTRICT];例子
回收全部权限
REVOKE ALL [PRIVILEGES] ON . FROM 'user'@'%';回收 INSERT 权限
REVOKE INSERT ON db_name.* FROM 'user'@'%';Tips:
CASCADE | RESTRICT当检测到关联的特权时,RESTRICT(默认值) 导致REVOKE失败;CASCADE可以回收所有这些关联的特权;(如U1授权U2, U2授权U3,此时使用级联(CASCADE)收回了U2和U3的权限,否则系统将拒绝执行该命令)
5.3 GRANT允许的特权
下表说明了可用于GRANT和REVOKE语句的所有可用权限:
| 权限 | 含义 | 全局 | 数据库 | 表 | 列 | 过程 | 代理 |
|---|---|---|---|---|---|---|---|
ALL [PRIVILEGES] | 授予除了grant option之外的指定访问级别的所有权限 | ||||||
ALTER | 允许用户使用alter table语句 | X | X | X | |||
ALTER ROUTINE | 允许用户更改或删除存储程序, 可以使用{alter | drop} {procedure | unction} | X | X | X | |||
CREATE | 允许用户创建数据库和表 | X | X | X | |||
CREATE ROUTINE | 可以使用{create | alter | drop} {procedure | function} | X | |||||
CREATE TABLESPACE | 允许用户创建,更改或删除表空间和日志文件组 | X | |||||
CREATE TEMPORARY TABLES | 允许用户使用create temporary table创建临时表 | X | X | ||||
CREATE USER | 允许用户使用create user,drop user,rename user和revoke all privileges语句 | X | |||||
CREATE VIEW | 允许用户创建或修改视图 | X | X | X | |||
DELETE | 允许用户使用delete | X | X | X | |||
DROP | 允许用户删除数据库,表和视图 | X | X | X | |||
EVENT | 能够使用事件计划的事件 | X | X | ||||
EXECUTE | 允许用户执行存储过程/存储函数 | X | X | ||||
FILE | 允许用户读取数据库目录中的任何文件 | X | |||||
GRANT OPTION | 允许用户有权授予或撤销其他帐户的权限 | X | X | X | X | X | |
INDEX | 允许用户创建或删除索引 | X | X | X | |||
INSERT | 允许用户使用insert语句 | X | X | X | X | ||
LOCK TABLES | 允许用户在具有select权限的表上使用lock tables | X | X | ||||
PROCESS | 允许用户使用show processlist语句查看所有进程 | X | |||||
PROXY | 启用用户代理 | ||||||
REFERENCES | 允许用户创建外键 | X | X | X | X | ||
RELOAD | 允许用户使用flush操作 | X | |||||
REPLICATION CLIENT | 允许用户查询主服务器或从服务器的位置 | X | |||||
REPLICATION SLAVE | 允许用户使用复制从站从主机读取二进制日志事件 | X | |||||
SELECT | 允许用户使用select语句 | X | X | X | X | ||
SHOW DATABASES | 允许用户显示所有数据库 | X | |||||
SHOW VIEW | 允许用户使用show create view语句 | X | X | X | |||
SHUTDOWN | 允许用户使用mysqladmin shutdown命令 | X | |||||
SUPER | 允许用户使用其他管理操作,如change master to,kill,purge binary logs,set global和mysqladmin命令 | X | |||||
TRIGGER | 允许用户使用trigger操作 | X | X | X | |||
UPDATE | 允许用户使用update语句 | X | X | X | X | ||
USAGE | 连接(登陆)权限(默认授予且不能被回收) |
5.4 实例
5.4.1 用户操作
1.创建用户
CREATE USER 'user'@'%' IDENTIFIED BY 'newpasswd';2.重命名用户
CREATE USER 'old_user'@'%' TO 'new_user'@'%';3.删除用户
a.查询用户
SELECT user,host FROM mysql.user;b.删除用户
DROP USER 'user'@'host';5.4.2 查看和刷新权限
查看权限
SHOW GRANTS [FOR 'user'@'host'];刷新权限
FLUSH PRIVILEGES;5.4.3 授权与取消授权
1.用法
GRANT 权限 ON 数据库对象 TO 用户 [WITH GRANT OPTION]; -- 授权
REVOKE 权限 ON 数据库对象 FROM 用户 [CASCADE | RESTRICT]; -- 取消授权
Tips: REVOKE 跟 GRANT 的语法差不多,只需要把关键字 TO 换成 FROM 即可
2.例子
添加权限(和已有权限合并,不会覆盖已有权限)
-- 添加普通数据用户,查询、插入、更新、删除 数据库中所有表数据的权利
grant select, insert, update, delete on testdb.* to common_user@'%'
-- 添加数据库开发人员,创建表、索引、视图、存储过程、函数。。。等权限
grant create, alter, drop on testdb.* to developer@'192.168.0.%';
-- 添加操作 MySQL 外键权限
grant references on testdb.* to developer@'192.168.0.%';
-- 添加操作 MySQL 临时表权限
grant create temporary tables on testdb.* to developer@'192.168.0.%';
-- 添加操作 MySQL 索引权限
grant index on testdb.* to developer@'192.168.0.%';
-- 添加操作 MySQL 视图、查看视图源代码 权限
grant create, show view on testdb.* to developer@'192.168.0.%';
删除授权
-- 删除普通数据用户,查询、插入、更新、删除 数据库中所有表数据的权利
revoke select, insert, update, delete on testdb.* from common_user@'%'
-- 删除数据库开发人员,创建表、索引、视图、存储过程、函数。。。等权限
revoke create, alter, drop on testdb.* from developer@'192.168.0.%';
-- 删除操作 MySQL 外键权限
revoke references on testdb.* from developer@'192.168.0.%';
-- 删除操作 MySQL 临时表权限
revoke create temporary tables on testdb.* from developer@'192.168.0.%';
-- 删除操作 MySQL 索引权限
revoke index on testdb.* from developer@'192.168.0.%';
-- 删除操作 MySQL 视图、查看视图源代码 权限
revoke create, show view on testdb.* from developer@'192.168.0.%';
DBA 权限管理
-- 普通 DBA 管理某个 MySQL 数据库的权限
grant all [privileges] on testdb to dba@'localhost'
-- 高级 DBA 管理 MySQL 中所有数据库的权限。
grant all on *.* to dba@'localhost'
细密度授权
-- 作用在整个 MySQL 服务器上
grant select on *.* to dba@localhost; -- dba 可以查询 MySQL 中所有数据库中的表
grant all on *.* to dba@localhost; -- dba 可以管理 MySQL 中的所有数据库
-- 作用在单个数据库上
grant select on testdb.* to dba@localhost; -- dba 可以查询 testdb 中的表。
-- 作用在单个数据表上
grant select, insert, update, delete on testdb.t_orders to dba@localhost;
-- 作用在表中的列上
grant select(id, username, sex) on testdb.t_user to dba@localhost;
权限传播与收回
-- 授权 dba 查询权限,并且可以将这些权限 grant 给其他用户
grant select on testdb.* to dba@localhost with grant option;
-- 收回 dba 和其传播用户的权限
revoke select on testdb.* from dba@localhost cascade;
Tips: 权限发生改变后, 需要重新加载一下权限,将权限信息从内存中写入数据库;
6. DML应用
6.1 作用
对表中的数据行进行增、删、改
6.2 insert
--- 最标准的insert语句
INSERT INTO stu(id,sname,sage,sg,sfz,intime)
VALUES
(1,'zs',18,'m','123456',NOW());
SELECT * FROM stu;
--- 省事的写法
INSERT INTO stu
VALUES
(2,'ls',18,'m','1234567',NOW());
--- 针对性的录入数据
INSERT INTO stu(sname,sfz)
VALUES ('w5','34445788');
--- 同时录入多行数据
INSERT INTO stu(sname,sfz)
VALUES
('w55','3444578d8'),
('m6','1212313'),
('aa','123213123123');
SELECT * FROM stu;6.3 update
DESC stu;
SELECT * FROM stu;
UPDATE stu SET sname='zhao4' WHERE id=2;
注意:update语句必须要加where。
mysql> set global sql_safe_updates=1; #如果使用update不带where会报错6.4 delete
DELETE FROM stu WHERE id=3;全表删除:
DELETE FROM stu
truncate table stu;
区别:
drop : 表定义+数据全部删除,立即释放磁盘空间.
truncate : DDL操作,整表所有数据全部删除,清空数据页,立即释放磁盘空间.速度快。
delete : DML操作,逐行"删除"(只是打一个标记),表中每行数据,逻辑删除,不会立即释放磁盘.HWM(高水位线)没有降低,速度慢。问题:如果使用drop,truncate,delete删除数据,可以恢复吗?
可以,
常规方法:
都可以通过“备份+日志”的方式,恢复数据
灵活方法:
Delete可以通过翻转日志(Binlog)
三种删除数据情况也可以通过(延时从库)进行恢复伪删除:用update来替代delete,最终保证业务中查不到(select)即可
1.添加状态列
ALTER TABLE stu ADD state TINYINT NOT NULL DEFAULT 1 ;
SELECT * FROM stu;
2. UPDATE 替代 DELETE
UPDATE stu SET state=0 WHERE id=6;
3. 业务语句查询
SELECT * FROM stu WHERE state=1;7. DQL应用
7.1 单独使用
-- select @@xxx 查看系统参数
SELECT @@port;
SELECT @@basedir;
SELECT @@datadir;
SELECT @@socket;
SELECT @@server_id;-- select 函数();
SELECT NOW();
SELECT DATABASE();
SELECT USER();
SELECT CONCAT("hello world");
SELECT CONCAT(USER,"@",HOST) FROM mysql.user;
SELECT GROUP_CONCAT(USER,"@",HOST) FROM mysql.user;
https://dev.mysql.com/doc/refman/5.7/en/func-op-summary-ref.html?tdsourcetag=s_pcqq_aiomsg模糊查询
_:任意一个字符,
%:任意0或多个字符
7.2 单表子句-from
SELECT 列1,列2 FROM 表
SELECT * FROM 表例子:
-- 查询stu中所有的数据(不要对大表进行操作)
SELECT * FROM stu ;-- 查询stu表中,学生姓名和入学时间
SELECT sname , intime FROM stu;7.3 单表子句-where
SELECT col1,col2 FROM TABLE WHERE colN 条件;7.3.1 where配合等值查询
例子:
-- 查询中国(CHN)所有城市信息
SELECT * FROM city WHERE countrycode='CHN';-- 查询北京市的信息
SELECT * FROM city WHERE NAME='peking';-- 查询甘肃省所有城市信息
SELECT * FROM city WHERE district='gansu';7.3.2 where配合比较操作符(> < >= <= <>)
例子:
-- 查询世界上少于100人的城市
SELECT * FROM city WHERE population<100;7.3.3 where配合逻辑运算符(and or )
例子:
-- 查询世界上少于100人的城市
SELECT * FROM city WHERE population<100;7.3.3 where配合逻辑运算符(and or )
例子:
-- 中国人口数量大于500w
SELECT * FROM city WHERE countrycode='CHN' AND population>5000000;-- 中国或美国城市信息
SELECT * FROM city WHERE countrycode='CHN' OR countrycode='USA';7.3.4 where配合模糊查询
例子:
-- 查询省的名字前面带guang开头的
SELECT * FROM city WHERE district LIKE 'guang%';
注意:%不能放在前面,因为不走索引.7.3.5 where配合in语句
-- 中国或美国城市信息
SELECT * FROM city WHERE countrycode IN ('CHN' ,'USA');7.3.6 where配合between and
例子:
-- 查询世界上人口数量大于100w小于200w的城市信息
SELECT * FROM city WHERE population >1000000 AND population <2000000;
SELECT * FROM city WHERE population BETWEEN 1000000 AND 2000000;7.4 group by + 常用聚合函数
7.4.1 作用
根据 by后面的条件进行分组,方便统计,by后面跟一个列或多个列
7.4.2 常用聚合函数
**max()** :最大值
**min()** :最小值
**avg()** :平均值
**sum()** :总和
**count()** :个数
group_concat() : 列转行7.4.3 例子
例子1:统计世界上每个国家的总人口数
USE world
SELECT countrycode ,SUM(population) FROM city GROUP BY countrycode;例子2: 统计中国各个省的总人口数量(练习)
SELECT district,SUM(Population) FROM city WHERE countrycode='chn' GROUP BY district;例子3:统计世界上每个国家的城市数量(练习)
SELECT countrycode,COUNT(id) FROM city GROUP BY countrycode;注意:统计中国每个省的人数,个数和名字列表

错误原因:select中的列,要么是group by的条件,要么在聚合函数中出现。
原理:MySQL不支持,结果集是一对多的显示方式。
正确做法:select district,SUM(population),count(id),group_concat(name) from city where countrycode='chn' group by district;7.5 having
where|group|having,与where字句类似,having属于后过滤。例子4:统计中国每个省的总人口数,只打印总人口数小于100
SELECT district,SUM(Population)
FROM city
WHERE countrycode='chn'
GROUP BY district
HAVING SUM(Population) < 1000000 ;7.6 order by + limit
7.6.1 作用
实现先排序,by后添加条件列。 Limit:分页显示结果集。
7.6.2 应用案例
1.查看中国所有的城市,并按人口数进行排序(从大到小)
SELECT * FROM city WHERE countrycode='CHN' ORDER BY population DESC;2.统计中国各个省的总人口数量,按照总人口从大到小排序
SELECT district AS 省 ,SUM(Population) AS 总人口
FROM city
WHERE countrycode='chn'
GROUP BY district
ORDER BY 总人口 DESC 3.统计中国,每个省的总人口,找出总人口大于500w的,并按总人口从大到小排序,只显示前三名
SELECT district, SUM(population) FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 3 ;
LIMIT N ,M --->跳过N,显示一共M行
LIMIT 5,5
LIMIT X OFFSET Y--跳过Y行,显示X行
LIMIT 5 OFFSET 5
SELECT district, SUM(population) FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 5,5;
或者
SELECT district, SUM(population) FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 5 offset 5;7.7 distinct:去重复
SELECT countrycode FROM city ;
SELECT DISTINCT(countrycode) FROM city ;7.8 联合查询- union all
UNION用的比较多union all是直接连接,取到得是所有值,记录可能有重复 union 是取唯一值,记录没有重复
1、UNION 的语法如下:
[SQL 语句 1]
UNION
[SQL 语句 2]
2、UNION ALL 的语法如下:
[SQL 语句 1]
UNION ALL
[SQL 语句 2]
效率:
UNION和UNION ALL关键字都是将两个结果集合并为一个,但这两者从使用和效率上来说都有所不同。
1、对重复结果的处理:UNION在进行表链接后会筛选掉重复的记录,Union All不会去除重复记录。
2、对排序的处理:Union将会按照字段的顺序进行排序;UNION ALL只是简单的将两个结果合并后就返回。
从效率上说,UNION ALL 要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复数据且不需要排序时的话-- 中国或美国城市信息
SELECT * FROM city
WHERE countrycode IN ('CHN' ,'USA');
SELECT * FROM city WHERE countrycode='CHN'
UNION ALL
SELECT * FROM city WHERE countrycode='USA'
说明:一般情况下,我们会将 IN 或者 OR 语句 改写成 UNION ALL,来提高性能显示前三名和后三名
(SELECT district , SUM(population) FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 3)
UNION ALL
(SELECT district , SUM(population) FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population)
LIMIT 3)7.9 join 多表连接查询
7.9.0 案例准备
按需求创建一下表结构:
use school
student :学生表
sno: 学号
sname:学生姓名
sage: 学生年龄
ssex: 学生性别
teacher :教师表
tno: 教师编号
tname:教师名字
course :课程表
cno: 课程编号
cname:课程名字
tno: 教师编号
score :成绩表
sno: 学号
cno: 课程编号
score:成绩
============================================================
-- 项目构建
drop database school;
CREATE DATABASE school CHARSET utf8;
USE school
CREATE TABLE student(
sno INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(20) NOT NULL COMMENT '姓名',
sage TINYINT UNSIGNED NOT NULL COMMENT '年龄',
ssex ENUM('f','m') NOT NULL DEFAULT 'm' COMMENT '性别'
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE course(
cno INT NOT NULL PRIMARY KEY COMMENT '课程编号',
cname VARCHAR(20) NOT NULL COMMENT '课程名字',
tno INT NOT NULL COMMENT '教师编号'
)ENGINE=INNODB CHARSET utf8;
CREATE TABLE sc (
sno INT NOT NULL COMMENT '学号',
cno INT NOT NULL COMMENT '课程编号',
score INT NOT NULL DEFAULT 0 COMMENT '成绩'
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE teacher(
tno INT NOT NULL PRIMARY KEY COMMENT '教师编号',
tname VARCHAR(20) NOT NULL COMMENT '教师名字'
)ENGINE=INNODB CHARSET utf8;
==============================================================
INSERT INTO student(sno,sname,sage,ssex)
VALUES (1,'zhang3',18,'m');
INSERT INTO student(sno,sname,sage,ssex)
VALUES
(2,'zhang4',18,'m'),
(3,'li4',18,'m'),
(4,'wang5',19,'f');
INSERT INTO student
VALUES
(5,'zh4',18,'m'),
(6,'zhao4',18,'m'),
(7,'ma6',19,'f');
INSERT INTO student(sname,sage,ssex)
VALUES
('oldboy',20,'m'),
('oldgirl',20,'f'),
('oldp',25,'m');
INSERT INTO teacher(tno,tname) VALUES
(101,'oldboy'),
(102,'hesw'),
(103,'oldguo');
DESC course;
INSERT INTO course(cno,cname,tno)
VALUES
(1001,'linux',101),
(1002,'python',102),
(1003,'mysql',103);
DESC sc;
INSERT INTO sc(sno,cno,score)
VALUES
(1,1001,80),
(1,1002,59),
(2,1002,90),
(2,1003,100),
(3,1001,99),
(3,1003,40),
(4,1001,79),
(4,1002,61),
(4,1003,99),
(5,1003,40),
(6,1001,89),
(6,1003,77),
(7,1001,67),
(7,1003,82),
(8,1001,70),
(9,1003,80),
(10,1003,96);
SELECT * FROM student;
SELECT * FROM teacher;
SELECT * FROM course;
SELECT * FROM sc;7.9.1 语法
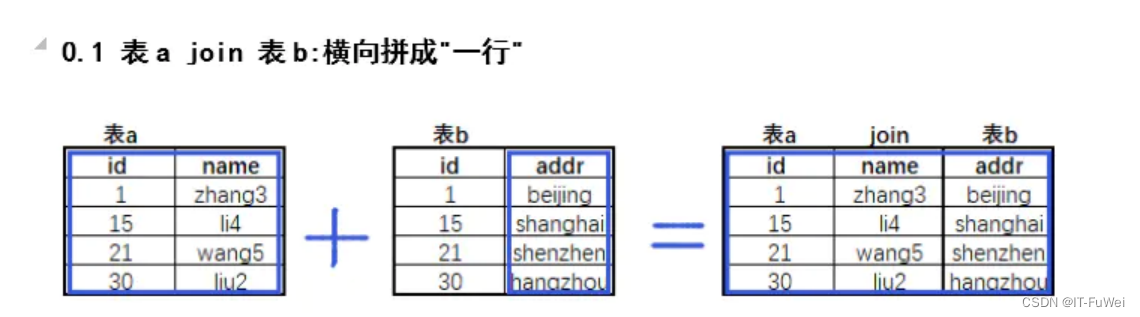
查询张三的家庭住址
SELECT A.name,B.address FROM
A JOIN B
ON A.id=B.id
WHERE A.name='zhangsan'7.9.2 例子
1.查询一下世界上人口数量小于100人的城市名和国家名
SELECT b.name ,a.name ,a.population
FROM city AS a
JOIN country AS b
ON b.code=a.countrycode
WHERE a.Population<1002.查询城市shenyang,城市人口,所在国家名(name)及国土面积(SurfaceArea)
SELECT a.name,a.population,b.name ,b.SurfaceArea
FROM city AS a JOIN country AS b
ON a.countrycode=b.code
WHERE a.name='shenyang';7.9.3 别名
为表取别名的基本语法格式为:
<表名> [AS] <别名>
其中各子句的含义如下:
<表名>:数据中存储的数据表的名称。 ·
<别名>:查询时指定的表的新名称。
AS:关键字为可选参数。
---------------------------------------------------------------------
例子1:
SELECT
a.Name AS an ,
b.name AS bn ,
b.SurfaceArea AS bs,
a.Population AS bp
FROM city AS a JOIN country AS b
ON a.CountryCode=b.Code
WHERE a.name ='shenyang';
例子2:
SELECT
student.sname AS '学生姓名',GROUP_CONCAT(course.cname) AS '课程',COUNT(*) AS '个数'
FROM student JOIN sc ON student.sno=sc.sno
JOIN course ON sc.cno=course.cno
GROUP BY student.sno;7.9.4 多表SQL练习题
1.统计zhang3,学习了几门课
SELECT st.sname , COUNT(sc.cno)
FROM student AS st
JOIN sc
ON st.sno=sc.sno
WHERE st.sname='zhang3'2.查询zhang3,学习的课程名称有哪些?
SELECT st.sname , GROUP_CONCAT(co.cname)
FROM student AS st
JOIN sc
ON st.sno=sc.sno
JOIN course AS co
ON sc.cno=co.cno
WHERE st.sname='zhang3'3.查询oldguo老师教的学生名.
SELECT te.tname ,GROUP_CONCAT(st.sname)
FROM student AS st
JOIN sc
ON st.sno=sc.sno
JOIN course AS co
ON sc.cno=co.cno
JOIN teacher AS te
ON co.tno=te.tno
WHERE te.tname='oldguo';4.查询oldguo所教课程的平均分数
SELECT te.tname,AVG(sc.score)
FROM teacher AS te
JOIN course AS co
ON te.tno=co.tno
JOIN sc
ON co.cno=sc.cno
WHERE te.tname='oldguo'5.每位老师所教课程的平均分,并按平均分排序
SELECT te.tname,AVG(sc.score)
FROM teacher AS te
JOIN course AS co
ON te.tno=co.tno
JOIN sc
ON co.cno=sc.cno
GROUP BY te.tname
ORDER BY AVG(sc.score) DESC ;6.查询oldguo所教的不及格的学生姓名
SELECT te.tname,st.sname,sc.score
FROM teacher AS te
JOIN course AS co
ON te.tno=co.tno
JOIN sc
ON co.cno=sc.cno
JOIN student AS st
ON sc.sno=st.sno
WHERE te.tname='oldguo' AND sc.score<60;7.查询所有老师所教学生不及格的信息
SELECT te.tname,st.sname,sc.score
FROM teacher AS te
JOIN course AS co
ON te.tno=co.tno
JOIN sc
ON co.cno=sc.cno
JOIN student AS st
ON sc.sno=st.sno
WHERE sc.score<60;7.9.5 综合练习
1.查询平均成绩大于60分的同学的学号和平均成绩;
SELECT student.sno,AVG(sc.score)
FROM student JOIN sc ON student.sno=sc.sno
GROUP BY student.sno
HAVING AVG(sc.score)>60;2.查询所有同学的学号、姓名、选课数、总成绩;
SELECT student.sno,student.sname,COUNT(*),SUM(sc.score)
FROM student JOIN sc ON student.sno=sc.sno
JOIN course ON sc.cno=course.cno
GROUP BY student.sno;3.查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分
SELECT course.cno,MAX(sc.score),MIN(sc.score)
FROM course JOIN sc ON course.cno=sc.cno
GROUP BY course.cno;4.统计各位老师,所教课程的及格率
SELECT teacher.tname,course.cname,COUNT(CASE WHEN IFNULL(sc.score,0)>=60 THEN 1 END)/COUNT(*)*10 AS '及格率'
FROM teacher JOIN course ON course.tno=teacher.tno
JOIN sc ON sc.cno=course.cno
GROUP BY teacher.tno;5.查询每门课程被选修的学生数
SELECT course.cname,COUNT(student.sno)
FROM course JOIN sc ON course.cno=sc.cno
JOIN student ON sc.sno=student.sno
GROUP BY course.cno;6.查询出只选修了一门课程的全部学生的学号和姓名
SELECT student.sno,student.sname,COUNT(course.cno)
FROM student JOIN sc ON student.sno=sc.sno
JOIN course ON sc.cno=course.cno
GROUP BY student.sno
HAVING COUNT(course.cno)=1;7.查询选修课程门数超过1门的学生信息
SELECT student.sno,student.sname,COUNT(course.cno)
FROM student JOIN sc ON student.sno=sc.sno
JOIN course ON sc.cno=course.cno
GROUP BY student.sno
HAVING COUNT(course.cno)>1;8.统计每门课程:优秀(85分以上),良好(70-85),一般(60-70),不及格(小于60)的学生列表
方法一:使用CASE WHEN
SELECT course.cname,GROUP_CONCAT(CASE WHEN sc.score>85 THEN student.sname END) AS '85分以上',
GROUP_CONCAT(CASE WHEN 70<sc.score<=85 THEN student.sname END) AS '70-85分',
GROUP_CONCAT(CASE WHEN 60<=sc.score<=70 THEN student.sname END) AS '60-70分',
GROUP_CONCAT(CASE WHEN sc.score<60 THEN student.sname END) AS '60分以下'
FROM course JOIN sc ON course.cno=sc.cno JOIN student ON sc.sno=student.sno
GROUP BY course.cno
方法二:使用IFNULL
SELECT course.cname, GROUP_CONCAT(CASE WHEN IFNULL(sc.score,0)>=85 THEN student.sname END) AS '优秀',
GROUP_CONCAT(CASE WHEN IFNULL(sc.score,0) BETWEEN 70 AND 85 THEN student.sname END ) AS '良好',
GROUP_CONCAT(CASE WHEN IFNULL(sc.score,0) BETWEEN 60 AND 70 THEN student.sname END) AS '一般',
GROUP_CONCAT(CASE WHEN IFNULL(sc.score,0)< 60 THEN student.sname END) AS '不及格'
FROM student JOIN sc ON sc.sno=student.sno
JOIN course ON course.cno=sc.cno
GROUP BY course.cno;
方法三:使用IF
SELECT course.cname,GROUP_CONCAT(IF(sc.score>85,student.sname,FALSE)) AS '85分以上',
GROUP_CONCAT(IF(70<sc.score<=85,student.sname,FALSE)) AS '70-85分',
GROUP_CONCAT(IF(60<=sc.score<=70,student.sname,FALSE)) AS '60-70分',
GROUP_CONCAT(IF(sc.score<60,student.sname,FALSE)) AS '60分以下'
FROM course JOIN sc ON course.cno=sc.cno
JOIN student ON sc.sno=student.sno
GROUP BY course.cno9.查询平均成绩大于85的所有学生的学号、姓名和平均成绩
SELECT student.sno,student.sname,AVG(sc.score)
FROM student JOIN sc ON student.sno=sc.sno
JOIN course ON sc.cno=course.cno
GROUP BY student.sno
HAVING AVG(sc.score)>85;8. information_schema.tables视图
DESC information_schema.TABLES
TABLE_SCHEMA ---->表所在的库名
TABLE_NAME ---->表名
ENGINE ---->表的引擎
TABLE_ROWS ---->表的数据行(不是特别实时)
AVG_ROW_LENGTH ---->表中行的平均长度(字节)
DATA_LENGTH ---->表使用的存储空间大小(不是特别实时)
INDEX_LENGTH ---->索引的占用空间大小(字节)
DATA_FREE ---->表中是否有碎片1.查询整个数据库中所有库和所对应的表信息
SELECT table_schema,GROUP_CONCAT(table_name)
FROM information_schema.tables
GROUP BY table_schema;2.统计所有库下的表个数
SELECT table_schema,COUNT(table_name)
FROM information_schema.TABLES
GROUP BY table_schema3.查询所有innodb引擎的表及所在的库
SELECT table_schema,table_name,ENGINE FROM information_schema.`TABLES`
WHERE ENGINE='innodb';4.统计world数据库下每张表的磁盘空间占用
SELECT table_name,CONCAT((TABLE_ROWS*AVG_ROW_LENGTH+INDEX_LENGTH)/1024," KB") AS size_KB
FROM information_schema.tables WHERE TABLE_SCHEMA='world';5.统计所有数据库的总的磁盘空间占用
SELECT
TABLE_SCHEMA,
CONCAT(SUM(TABLE_ROWS*AVG_ROW_LENGTH+INDEX_LENGTH)/1024," KB") AS Total_KB
FROM information_schema.tables
GROUP BY table_schema;
或者
mysql -uroot -p123 -e "SELECT TABLE_SCHEMA,CONCAT(SUM(TABLE_ROWS*AVG_ROW_LENGTH+INDEX_LENGTH)/1024,' KB') AS Total_KB FROM information_schema.tables GROUP BY table_schema;"6.生成整个数据库下的所有表的单独备份语句
模板语句:
mysqldump -uroot -p123 world city >/tmp/world_city.sql
SELECT CONCAT("mysqldump -uroot -p123 ",table_schema," ",table_name," >/tmp/",table_schema,"_",table_name,".sql" )
FROM information_schema.tables
WHERE table_schema NOT IN('information_schema','performance_schema','sys')
INTO OUTFILE '/tmp/back.sh' ;
CONCAT("mysqldump -uroot -p123 ",table_schema," ",table_name," >/tmp/",table_schema,"_",table_name,".sql" )7. 将数据库中所有业务数据库,非innodb的表改为innodb,使用拼接语句concat.
SELECT concat("alter table ",table_schema,".",table_name," engine=innodb;")
FROM information_schema.tables
WHERE table_schema NOT IN ('mysql','sys','information_schema','performance_schema','world')
AND ENGINE <>'innodb' into outfile '/tmp/alter.sql' ;9. show 命令
show databases; #查看所有数据库
show tables; #查看当前库的所有表
SHOW TABLES FROM mysql #查看某个指定库下的表
show create database world #查看建库语句
show create table world.city #查看建表语句
show grants for root@'localhost' #查看用户的权限信息
show charset; #查看字符集
show collation #查看校对规则
show processlist; #查看数据库连接情况
show index from t1 #表的索引情况
show status #数据库状态查看
SHOW STATUS LIKE '%lock%'; #模糊查询数据库某些状态
SHOW VARIABLES #查看所有配置信息
SHOW variables LIKE '%lock%'; #查看部分配置信息
show engines #查看支持的所有的存储引擎
show engine innodb status\G #查看InnoDB引擎相关的状态信息
show binary logs #列举所有的二进制日志
show master status #查看数据库的日志位置信息
show binlog evnets in #查看二进制日志事件
show slave status \G #查看从库状态
SHOW RELAYLOG EVENTS #查看从库relaylog事件信息
desc (show colums from city) #查看表的列定义信息
http://dev.mysql.com/doc/refman/5.7/en/show.html10. 条件判断函数
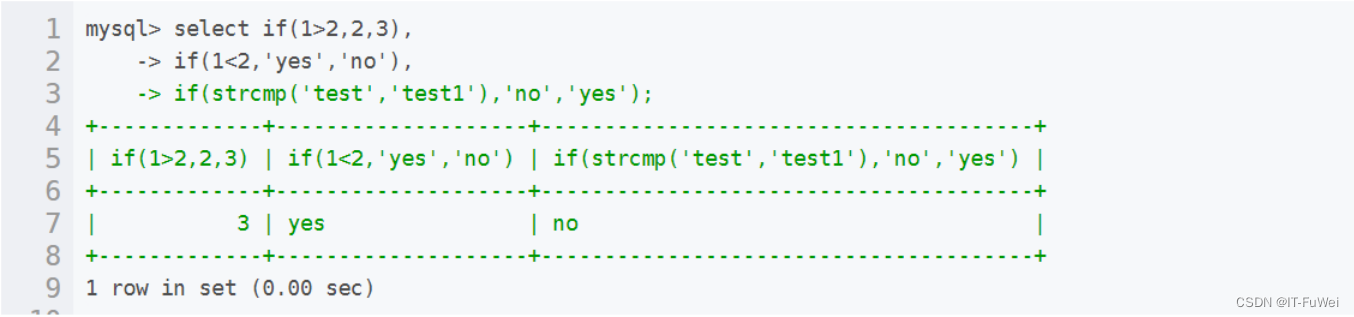
1.IF(expr, v1, v2)函数
如果expr成立,返回值为v1,否则返回v2
2.IFNULL(v1, v2)函数
IFNULL(v1,v2)假如v1不为NULL,则IFNULL()的返回值为v1;否则其返回值为v2。IFNULL()的返回值是数字或是字符串,具体情况取决于其所在的语境。

3.CASE函数
CASE expr WHEN v1 THEN r1 [WHEN v2 THEN r2] [ELSE rn] END
该函数表示,如果expr值等于某个vn,则返回对应位置THEN后面的结果。如果与所有值都不相等,则返回ELSE后面的rn。

















 766
766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











