







目录
1. Ceph集群部署
1.1 系统基础环境设定
1.1.1 测试环境说明
测试使用的Ceph存储集群可由一个MON主机及两个以上的OSD机组成,这些主机可以是物理服务器,也可以运行于vmware、virtualbox或kvm等虚拟化平台上的虚拟机,甚至是公有云上的VPS主机。
本测试环境将由stor01、stor02、stor03和ceph-admin四个独立的主机组成,其中stor01、stor02和stor03是为Ceph存储集群节点,它们分别作为MON节点和OSD节点,各自拥有专用于存储数据的磁盘设备/dev/vdb和/dev/vdc,操作系统环境均为CentOS 7.5 1804。而ceph-admin主机是为管理节点,用于部署ceph-deploy。
| 主机地址 | 主机名称 | 主机角色 |
|---|---|---|
| 172.20.0.59 | ceph-admin. | admin |
| 172.20.0.55 | zhc-app-cephfs-dev-01 | mon, osd, mgr, mds |
| 172.20.0.56 | zhc-app-cephfs-dev-02 | mon, osd, mgr |
| 172.20.0.57 | zhc-app-cephfs-dev-03 | mon, osd, rgw |
此外,各主机需要预设的系统环境如下:
- 借助于NTP服务设定各节点时间精确同步;
- 通过DNS完成各节点的主机名称解析,测试环境主机数量较少时也可以使用hosts文件进行;
- 关闭各节点的iptables或firewalld服务,并确保它们被禁止随系统引导过程启动;
- 各节点禁用SELinux;
1.1.2 设定时钟同步
- 若节点可直接访问互联网,直接启动chronyd系统服务,并设定其随系统引导而启动。
~]# systemctl start chronyd.service
~]# systemctl enable chronyd.service 不过,建议用户配置使用本地的的时间服务器,在节点数量众多时尤其如此。存在可用的本地时间服务器时,修改节点的/etc/chrony.conf配置文件,并将时间服务器指向相应的主机即可,配置格式如下:
- server CHRONY-SERVER-NAME-OR-IP iburst
1.1.3 主机名称解析
- 出于简化配置步骤的目的,本测试环境使用hosts文件进行各节点名称解析,文件内容如下所示:
172.20.0.55 zhc-app-cephfs-dev-01 stor01 mon01 mds01
172.20.0.56 zhc-app-cephfs-dev-02 stor02 mon02 mgr01
172.20.0.57 zhc-app-cephfs-dev-03 stor03 mon03 mgr02
172.20.0.59 zhc-harbor-ceph-test-01 ceph-admin1.1.4 关闭iptables或firewalld服务
在CentOS7上,iptables或firewalld服务通常只会安装并启动一种,在不确认具体启动状态的前提下,这里通过同时关闭并禁用二者即可简单达到设定目标。
systemctl stop firewalld.service
systemctl stop iptables.service
systemctl disable firewalld.service
systemctl disable iptables.service1.1.5 关闭并禁用SELinux
若当前启用了SELinux,则需要编辑/etc/sysconfig/selinux文件,禁用SELinux,并临时设置其当前状态为permissive:
~]# sed -i 's@^\(SELINUX=\).*@\1disabled@' /etc/sysconfig/selinux
~]# setenforce 01.2 准备部署Ceph集群
1.2.1 准备yum仓库配置文件
Ceph官方的仓库路径为http://download.ceph.com/
目前主流版本相关的程序包都在提供,包括kraken、luminous和mimic等,它们分别位于rpm-mimic等一类的目录中。直接安装程序包即可生成相关的yum仓库相关的配置文件,程序包位于相关版本的noarch目录下,例如rpm-mimic/el7/noarch/ceph-release-1-1.el7.noarch.rpm是为负责生成适用于部署mimic版本Ceph的yum仓库配置文件,因此直接在线安装此程序包,也能直接生成yum仓库的相关配置。
- 在ceph-admin节点上,使用如下命令即可安装生成mimic版本相关的yum仓库配置。
~]# rpm -ivh https://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/ceph-release-1-1.el7.noarch.rpm1.2.2 创建部署Ceph的特定用户账号
部署工具ceph-deploy 必须以普通用户登录到Ceph集群的各目标节点,且此用户需要拥有无密码使用sudo命令的权限,以便在安装软件及生成配置文件的过程中无需中断配置过程。不过,较新版的ceph-deploy也支持用 ”–username“ 选项提供可无密码使用sudo命令的用户名(包括 root ,但不建议这样做)。
另外,使用”ceph-deploy –username {username} “命令时,指定的用户需要能够通过SSH协议自动认证并连接到各Ceph节点,以免ceph-deploy命令在配置中途需要用户输入密码。
1.2.3 在各Ceph各节点创建新用户
- 首先需要在各节点以管理员的身份创建一个专用于ceph-deploy的特定用户账号,例如cephadm(建议不要使用ceph),并为其设置认证密码(例如test):
~]# useradd cephadm
~]# echo "test" | passwd --stdin cephadm- 而后,确保这些节点上新创建的用户cephadm都有无密码运行sudo命令的权限。
~]# echo "cephadm ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephadm
~]# chmod 0440 /etc/sudoers.d/cephadm1.2.4 配置用户基于密钥的ssh认证
ceph-deploy命令不支持运行中途的密码输入,因此,必须在管理节点(zhc-harbor-ceph-test-01)上生成SSH密钥并将其公钥分发至Ceph集群的各节点上。下面直接以cephadm用户的身份生成SSH密钥对:
~]$ ssh-keygen -t rsa -P ""- 而后即可把公钥拷贝到各Ceph节点:
~]$ ssh-copy-id -i .ssh/id_rsa.pub cephadm@stor01
~]$ ssh-copy-id -i .ssh/id_rsa.pub cephadm@stor02
~]$ ssh-copy-id -i .ssh/id_rsa.pub cephadm@stor03另外,为了后续操作之便,建议修改管理节点上cephadm用户的 ~/.ssh/config 文件,设定其访问Ceph集群各节点时默认使用的用户名为,从而避免每次执行ceph-deploy命令时都要指定 使用”–username“选项设置使用的用户名。文件内容示例如下所示:
1.2.5 在管理节点安装ceph-deploy
Ceph存储集群的部署的过程可通过管理节点使用ceph-deploy全程进行,这里首先在管理节点安装ceph-deploy及其依赖到的程序包:
很多时候会有无法yum安装以下提供安装方式
阿里源
- 选择对应的版本设置好环境变量在控制端执行即可yum安装,ubantu方式相同,对应的版本+key即可
-
配置地址: https://mirrors.aliyun.com/ceph/?spm=a2c6h.13651104.0.0.356c7dd16zzbHB
#设置key检验的地址
export CEPH_DEPLOY_GPG_URL=https://mirrors.aliyun.com/ceph/keys/release.asc
#设置安装的版本
export CEPH_DEPLOY_REPO_URL=https://mirrors.aliyun.com/ceph/rpm-mimic/el7执行安装
[root@ceph-admin ~]# yum update
[root@ceph-admin ~]# yum install ceph-deploy python-setuptools python2-subprocess321.3 部署RADOS存储集群
1.3.1 初始化RADOS集群
- 首先在管理节点上以cephadm用户创建集群相关的配置文件目录:
~]$ mkdir ceph-cluster
~]$ cd ceph-cluster- 初始化第一个MON节点,准备创建集群:
初始化第一个MON节点的命令格式为”ceph-deploy new {initial-monitor-node(s)}“,本示例中,stor01即为第一个MON节点名称,其名称必须与节点当前实际使用的主机名称保存一致。运行如下命令即可生成初始配置:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy new stor01- 编辑生成ceph.conf配置文件,在[global]配置段中设置Ceph集群面向客户端通信时使用的IP地址所在的网络,即公网网络地址:
public network = 172.20.0.0/16- 安装Ceph集群
ceph-deploy命令能够以远程的方式连入Ceph集群各节点完成程序包安装等操作,命令格式如下:
ceph-deploy install {ceph-node} [{ceph-node} ...]- 因此,若要将stor01、stor02和stor03配置为Ceph集群节点,则执行如下命令即可:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy install stor01 stor02 stor03- 提示:若需要在集群各节点独立安装ceph程序包,其方法如下:
-
rpm包下载地址 : http://download.ceph.com/rpm-mimic/el7/x86_64/
~]# yum install -y https://download.ceph.com/rpm-mimic/el7/noarch/ceph-release-1-0.el7.noarch.rpm
~]# yum install ceph ceph-radosgw- 配置初始MON节点,并收集所有密钥:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mon create-initial报错解决
在各个节点上执行sudo pkill ceph,然后再在deploy节点执行ceph-deploy mon create-initial[cephadm@zhc-netmis-k8s-master-01 ceph-cluster]$ vim ceph.conf
[global]
fsid = 4c1783cb-b1d9-4204-8874-b4f5ae74ac2f
mon_initial_members = zhc-netmis-k8s-ceph-01
mon_host = 172.16.128.25
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
public network = 172.16.128.0/24 #指定public 网络检查网段是否正确
osd pool default size = 2 # 修改的副本数
cluster network = 1.1.1.0/24 # 指定cluster 网络(需要则加)
mon_allow_pool_delete = true # 允许删除pool, 需要重启monitor
#推送新的配置文件到各个节点
ceph-deploy --overwrite-conf config push ceph01 ceph02 ceph03- 把配置文件和admin密钥拷贝Ceph集群各节点,以免得每次执行”ceph“命令行时不得不明确指定MON节点地址和ceph.client.admin.keyring:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy admin stor01 stor02 stor03而后在Ceph集群中需要运行ceph命令的的节点上(或所有节点上)以root用户的身份设定用户cephadm能够读取/etc/ceph/ceph.client.admin.keyring文件:
~]$ setfacl -m u:cephadm:r /etc/ceph/ceph.client.admin.keyring- 配置Manager节点,启动ceph-mgr进程(仅Luminious+版本):
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mgr create stor01- 在Ceph集群内的节点上以cephadm用户的身份运行如下命令,测试集群的健康状态:
[cephadm@stor01 ~]$ ceph health
HEALTH_OK
[cephadm@stor01 ~]$ ceph -s
cluster:
id: fc5b806d-3b43-41f1-974a-c07468b9d9ff
health: HEALTH_OK
services:
mon: 1 daemons, quorum stor01
mgr: stor01(active)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs: 1.3.2 向RADOS集群添加OSD
1.3.2.1 列出并擦净磁盘
ceph-deploy disk 命令可以检查并列出OSD节点上所有可用的磁盘的相关信息:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy disk list stor01 stor02 stor03
而后,在管理节点上使用ceph-deploy命令擦除计划专用于OSD磁盘上的所有分区表和数据以便用于OSD,命令格式为”ceph-deploy disk zap {osd-server-name} {disk-name}“,需要注意的是此步会清除目标设备上的所有数据。下面分别擦净stor01、stor02和stor03上用于OSD的一个磁盘设备vdb:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy disk zap stor01 /dev/vdb
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy disk zap stor02 /dev/vdb
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy disk zap stor03 /dev/vdb- 提示:若设备上此前有数据,则可能需要在相应节点上以root用户使用“ceph-volume lvm zap –destroy {DEVICE}”命令进行;*
1.3.2.2 添加OSD
早期版本的ceph-deploy命令支持在将添加OSD的过程分为两个步骤:准备OSD和激活OSD,但新版本中,此种操作方式已经被废除,添加OSD的步骤只能由命令”ceph-deploy osd create {node} –data {data-disk}“一次完成,默认使用的存储引擎为bluestore。
- 如下命令即可分别把stor01、stor02和stor03上的设备vdb添加为OSD:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd create stor01 --data /dev/vdb
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd create stor02 --data /dev/vdb
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd create stor03 --data /dev/vdb- 而后可使用”ceph-deploy osd list”命令列出指定节点上的OSD:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd list stor01 stor02 stor03- 事实上,管理员也可以使用ceph命令查看OSD的相关信息:
~]$ ceph osd stat
3 osds: 3 up, 3 in; epoch: e15- 或者使用如下命令了解相关的信息:
~]$ ceph osd dump
~]$ ceph osd ls1.3.3 从RADOS集群中移除OSD的方法
Ceph集群中的一个OSD通常对应于一个设备,且运行于专用的守护进程。在某OSD设备出现故障,或管理员出于管理之需确实要移除特定的OSD设备时,需要先停止相关的守护进程,而后再进行移除操作。对于Luminous及其之后的版本来说,停止和移除命令的格式分别如下所示:
#正常优雅的删除osd方式
#1.需要把这个osd的权重设置为0然后设置成out
#2.关闭运行的osd
systemctl stop ceph-osd@{osdID}
#3.crush算法中删除你要踢出集群的osd
ceph osd crush remove {name}
#4.删除osd对应的用户
ceph auth list
ceph auth del user
#5.移除OSD的认证key
ceph auth del osd.{osd-num}
#6.从集群中移除osd
ceph osd rm {osd-num}- 停用设备:ceph osd out {osd-num}
-
停止进程:sudo systemctl stop ceph-osd@{osd-num}
-
移除设备:ceph osd purge {id} –yes-i-really-mean-it
-
若类似如下的OSD的配置信息存在于ceph.conf配置文件中,管理员在删除OSD之后手动将其删除。
[osd.1]
host = {hostname}
- 不过,对于Luminous之前的版本来说,管理员需要依次手动执行如下步骤删除OSD设备:
1.3.4 测试上传/下载数据对象
存取数据时,客户端必须首先连接至RADOS集群上某存储池,而后根据对象名称由相关的CRUSH规则完成数据对象寻址。于是,为了测试集群的数据存取功能,这里首先创建一个用于测试的存储池mypool,并设定其PG数量为16个。
~]$ ceph osd pool create mypool 16
pool 'mypool' created- 而后即可将测试文件上传至存储池中,例如下面的“rados put”命令将/etc/issue文件上传至mypool存储池,对象名称依然保留为文件名issue,而“rados ls”命令则可以列出指定存储池中的数据对象。
~]$ rados put issue /etc/issue --pool=mypool
~]$ rados ls --pool=mypool- 而[ceph osd map]命令可以获取到存储池中数据对象的具体位置信息:
~]$ ceph osd map mypool issue
osdmap e26 pool 'mypool' (1) object 'issue' -> pg 1.651f88da (1.a) -> up ([2,1,0], p2) acting ([2,1,0], p2)- 删除数据对象,“rados rm”命令是较为常用的一种方式:
~]$ rados rm issue --pool=mypool - 删除存储池命令存在数据丢失的风险,Ceph于是默认禁止此类操作。管理员需要在ceph.conf配置文件中启用支持删除存储池的操作后,方可使用类似如下命令删除存储池。
~]$ ceph osd pool rm mypool mypool --yes-i-really-really-mean-it1.4 扩展Ceph集群
1.4.1 扩展监视器节点
Ceph存储集群需要至少运行一个Ceph Monitor和一个Ceph Manager,生产环境中,为了实现高可用性,Ceph存储集群通常运行多个监视器,以免单监视器整个存储集群崩溃。Ceph使用Paxos算法,该算法需要半数以上的监视器(大于n/2,其中n为总监视器数量)才能形成法定人数。尽管此非必需,但奇数个监视器往往更好。
- ceph-deploy mon add {ceph-nodes}命令可以一次添加一个监视器节点到集群中。例如,下面的命令可以将集群中的stor02和stor03也运行为监视器节点:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mon add stor02
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mon add stor03
#查看monitor票数
ceph daemon mon.id quorum_status
#设置完成后,可以在ceph客户端上查看监视器及法定人数的相关状态:
~]$ ceph quorum_status --format json-pretty
{
"election_epoch": 12,
"quorum": [
0,
1,
2
],
"quorum_names": [
"stor01",
"stor02",
"stor03"
],
"quorum_leader_name": "stor01",
"monmap": {
"epoch": 3,
……
},
"mons": [
{
"rank": 0,
"name": "stor01",
"addr": "172.20.0.55:6789/0",
"public_addr": "172.20.0.55:6789/0"
},
{
"rank": 1,
"name": "stor02",
"addr": "172.20.0.56:6789/0",
"public_addr": "172.20.0.56:6789/0"
},
{
"rank": 2,
"name": "stor03",
"addr": "172.20.0.57:6789/0",
"public_addr": "172.20.0.57:6789/0"
}
]
}
}1.4.2 删除monitor节点
#停止monitor进程
systemctl stop ceph-mon@serverc
#删除monitor
ceph mon remove serverc
#删除monitor文件
rm /var/lib/ceph/mon/ceph-serverc1.4.3 扩展Manager节点
Ceph Manager守护进程以“Active/Standby”模式运行,部署其它ceph-mgr守护程序可确保在Active节点或其上的ceph-mgr守护进程故障时,其中的一个Standby实例可以在不中断服务的情况下接管其任务。
- ceph-deploy mgr create {new-manager-nodes}命令可以一次添加多个Manager节点。下面的命令可以将stor02节点作为备用的Manager运行:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mgr create stor02
添加完成后,“ceph -s”命令的services一段中会输出相关信息:
~]$ ceph -s
cluster:
id: fc5b806d-3b43-41f1-974a-c07468b9d9ff
health: HEALTH_OK
services:
mon: 3 daemons, quorum stor01,stor02,stor03
mgr: stor01(active), standbys: stor02
osd: 3 osds: 3 up, 3 in1.5 Ceph存储集群的访问接口
1.5.1 Ceph块设备接口(RBD)
Ceph块设备,也称为RADOS块设备(简称RBD),是一种基于RADOS存储系统支持超配(thin-provisioned)、可伸缩的条带化数据存储系统,它通过librbd库与OSD进行交互。RBD为KVM等虚拟化技术和云OS(如OpenStack和CloudStack)提供高性能和无限可扩展性的存储后端,这些系统依赖于libvirt和QEMU实用程序与RBD进行集成。
- 客户端基于librbd库即可将RADOS存储集群用作块设备,不过,用于rbd的存储池需要事先启用rbd功能并进行初始化。例如,下面的命令创建一个名为rbddata的存储池,在启用rbd功能后对其进行初始化:
~]$ ceph osd pool create rbddata 64
~]$ ceph osd pool application enable rbddata rbd
~]$ rbd pool init -p rbddata- 不过,rbd存储池并不能直接用于块设备,而是需要事先在其中按需创建映像(image),并把映像文件作为块设备使用。rbd命令可用于创建、查看及删除块设备相在的映像(image),以及克隆映像、创建快照、将映像回滚到快照和查看快照等管理操作。例如,下面的命令能够创建一个名为img1的映像:
~]$ rbd create image-01 --size 1024 --pool rbddata01- 映像的相关的信息则可以使用“rbd info”命令获取:
~]$ rbd --image image-01 --pool rbddata01 info
rbd image 'image-01':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
id: 14016b8b4567
block_name_prefix: rbd_data.14016b8b4567
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Wed Nov 6 11:30:03 2019
# 查看在该块设备上创建的镜像
~]$ rbd ls -p rbddata01
image-01- 在客户端主机上,用户通过内核级的rbd驱动识别相关的设备,即可对其进行分区、创建文件系统并挂载使用。
1.5.2 启用radosgw接口
RGW并非必须的接口,仅在需要用到与S3和Swift兼容的RESTful接口时才需要部署RGW实例,相关的命令为“ceph-deploy rgw create {gateway-node}”。例如,下面的命令用于把stor03部署为rgw主机:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy rgw create stor03
#添加完成后,“ceph -s”命令的services一段中会输出相关信息:
~]$ ceph -s
cluster:
id: fc5b806d-3b43-41f1-974a-c07468b9d9ff
health: HEALTH_OK
services:
mon: 3 daemons, quorum stor01,stor02,stor03
mgr: stor01(active), standbys: stor02
osd: 3 osds: 3 up, 3 in
**rgw: 1 daemon active**- 默认情况下,RGW实例监听于TCP协议的7480端口7480,需要算定时,可以通过在运行RGW的节点上编辑其主配置文件ceph.conf进行修改,相关参数如下所示:
[client]
rgw_frontends = "civetweb port=8080"- 而后需要重启相关的服务,命令格式为“systemctl restart ceph-radosgw@rgw.{node-name}”,例如重启stor03上的RGW,可以以root用户运行如下命令:
~]# systemctl status ceph-radosgw@rgw.stor03 - RGW会在rados集群上生成包括如下存储池的一系列存储池:
~]$ ceph osd pool ls
.rgw.root
default.rgw.control
default.rgw.meta
default.rgw.log- RGW提供的是REST接口,客户端通过http与其进行交互,完成数据的增删改查等管理操作。
1.5.3 启用文件系统(CephFS)接口
CephFS需要至少运行一个元数据服务器(MDS)守护进程(ceph-mds),此进程管理与CephFS上存储的文件相关的元数据,并协调对Ceph存储集群的访问。因此,若要使用CephFS接口,需要在存储集群中至少部署一个MDS实例。“ceph-deploy mds create {ceph-node}”命令可以完成此功能,例如,在stor01上启用MDS:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mds create stor01- 查看MDS的相关状态可以发现,刚添加的MDS处于Standby模式:
~]$ ceph mds stat
, 1 up:standby- 使用CephFS之前需要事先于集群中创建一个文件系统,并为其分别指定元数据和数据相关的存储池。下面创建一个名为cephfs的文件系统用于测试,它使用cephfs-metadata为元数据存储池,使用cephfs-data为数据存储池:
~]$ ceph osd pool create cephfs-metadata 64
~]$ ceph osd pool create cephfs-data 64
~]$ ceph fs new cephfs cephfs-metadata cephfs-data- 而后即可使用如下命令“ceph fs status ”查看文件系统的相关状态,例如:
~]$ ceph fs status cephfs- 此时,MDS的状态已经发生了改变:
~]$ ceph mds stat
cephfs-1/1/1 up {0=stor01=up:active}- 随后,客户端通过内核中的cephfs文件系统接口即可挂载使用cephfs文件系统,或者通过FUSE接口与文件系统进行交互。
-
进行相应的授权创建用户信息
#key和用户名需要单独的存放
cephadm@zhc-app-cephfs-dev-01:~$ ceph auth get-or-create client.fsclient mon 'allow r' mds 'allow rw' osd 'allow rwx pool=cephfs-data' -o ceph.client.fsclient.keyring
cephadm@zhc-app-cephfs-dev-01:~$ ceph auth get client.fsclient
exported keyring for client.fsclient
[client.fsclient]
key = AQA9hrpdM+sEHhAARBLjQMR+WYRkYugAur+CjA==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rwx pool=cephfs-data"
#查看key
方式一: ceph-authtool -p -n client.fsclient ceph.client.fsclient.keyring
方式二: ceph auth print-key client.fsclient
#获取到的key保存fsclient.key提供给客户端使用的
ceph auth print-key client.fsclient > fsclient.key客户端要使用要确保内核中用ceph的模块才能够使用
客户端内核挂载
指基于FUSE(FUSE全称是Filesystem in Userspace即用户空间文件系统,是指完全在用户态实现的文件系统,由Linux在内核模块进行支持。通常文件系统作为操作系统的重要组成部分在内核中实现,但缺点是内核态的代码难以调试,特别是一些新兴的网络文件系统更新换代较快的情况下。为了解决上述问题,Linux在2.6.14内核版本开始增加FUSE模块来实现文件系统在用户态的适配)的用户态接口,通过ceph-fuse命令将CephFS挂载到操作系统指定目录下。
- 相比NFS拥有rados底层有存储池拥有很高的冗余能力
- 很高的I/O扩展性远高于NFS
- L版本以后支持多活mds , 主-主/主-备模式
- 内核级别文件系统
#创建挂载节点
mkdir /data-harbor
#挂载指明用户密码/mon可以多个
mount -t ceph [mon:6789]:/ /data-harbor -o name=name,secretfile=/path
#查看下挂载信息
mount/df -h
#查看下文件系统类型
stat -f /data-harbor
#配置开机自动挂载/etc/fstab
#远端挂载点 #目的挂载点 #文件格式 #参数选项 #超时跳过
mon:6789,mon1:6789 /habor-data ceph name=fsclient,secretfile=/path,_netdev,noatime 0 0
mount -a 挂载中遇见的问题
Ceph Luminous CRUSH map 400000000000000 问题
- 方式一 : 检查内核版本是否满足条件不满足则升级
- 方式二 : 修改 CRUSH 中的 tunables 参数。
- 相关链接 一 : http://cephnotes.ksperis.com/blog/2014/01/21/feature-set-mismatch-error-on-ceph-kernel-client
- 相关链接二 : [http://tblog.pp4fun.com/2018/3/Ceph%20Cluster%20Storage%20%E5%88%9D%E9%9A%8E%E5%AD%B8%E7%BF%92.html](http://tblog.pp4fun.com/2018/3/Ceph Cluster Storage 初階學習.html)
客户端用户态挂载
- 如果系统没有ceph的内核模块则fuse程序包提供使用
- 和内核挂载相比性能肯定不如内核态
#安装程序包
yum/apt install -y fuse
#挂载ceph,mon可以一个可多个
ceph-fuse -n client.fsclient -m mon01:6789,mon02:6789 /path
#需要将在管理端的生产的秘钥发送到Client的/etc/ceph下,例如
ceph.client.fsclient.keyring
#开机自动挂载方式
none /path fuse.ceph ceph.id=fsclient,ceph.conf=/path,_netdev,defaults 0 0 1.5.4 MDS问题处理
问题一
描述cephfs的MDS写入报慢查询且无法正常执行解决办法
根据mgr位置查看MDS详细信息
ceph --admin-daemon /var/run/ceph/ceph-mds.ceph03.asok dump_ops_in_flight1.5.5 MDS的扩容
#新建mds很简单
ceph-deploy mds create nodename1.5.6 rank的管理
增加Active MDS的数量
- 仅当前存在某个备用的守护进程可以供新的级别使用时候,文件系统中的实际级别数才会增加
- 多活MDS的场景依然要求存在备用的冗余主机以实现服务HA,因此max_mds的值总是应该比实际可用的MDS的数量少1
#命令
ceph fs set <fsname> max_mds <number>
减少Active MDS的数量
- 减小max_mds的值仅仅会限制新的rank的创建,对于已经存在的Active MDS及持有rank的不造成影响,因此降低max_mds的值后,管理员需要手动关闭不再被需要的rank
ceph mds deactivate {System:rank|FSID:rank|rank}
查询变动后的mds值
ceph status <fsname>
ceph fs get <fsname>1.5.7 设置故障转移机制
出于冗余的目的,每一个CephFS上都应该配置一定数量的Standby状态的Ceph-mds守护进程等着接替故障的失效的Rank,CephFS提供了四个选项用于控制Standby状态的MDS守护进程如何工作
- mds_standby_replay – 布尔型 : true表示当前的MDS守护进程将会持续的取某个特定的Up状态的Rank的元数据日志,从而持有相关的rank的元数据缓存,并且在rank失效的时候加速故障切换
- 一个up状态的rank仅能拥有一个replay守护进程,多出的会被自动的降级为正常的非replay类型的MDS
- mds_standby_for_name : 设置当前的MDS进程仅备用于指定rank的命名名称
- mds_standby_for_rank : 设置当前的MDS进程仅备用于指定rank,它不会接替任何其他的失效的rank,不过在有着多个CephFS的场景中,可以联合使用下面的参数来指定为哪一个文件系统的rank进行相应的冗余
- mds_standby_fro_fscid : 联合mds_standby_for_rank参数的值协同生效
- 同时设置了mds_standby_fro_rank -> 备用于指定fscid的指定rank
- 未设置mdsmds_standby_fro_rank -> 备用于指定fscid的任意rank
#配置方式 -> /etc/ceph/ceph.conf
[mds.ceph01]
mds_standby_fro_fscid = ceph-harbor
mds_standby_fro_name = ceph03
mds_standby_replay = true1.5.8 开启控制面板
Ceph启⽤Dashboard V2
启⽤相关的模块
若使⽤https协议的Dashboard V2,需要以如下步骤⽣成证书及相关配置:
Dashboard要通过https协议提供服务。管理员可配置其使⽤⾃动⽣成的⾃签证书,也可以为其提供⾃定义的证书
⽂件,⼆者先其⼀即可。⽽后通过相关节点的地址和端⼝访问服务。
ceph mgr module enable dashboard
#若使⽤http协议的Dashboard V2,需要设定禁⽤SSL功能:
ceph config set mgr mgr/dashboard/ssl false
#若需要使⽤⾃签证书,运⾏如下命令⽣成⾃动⽣成证书即可
ceph dashboard create-self-signed-cert
#若需要⾃定义证书,则应该通过合适的⽅式获取到相关证书。例如,以如下⽅式运⾏命令⽣成⾃定义的证书:
openssl req -new -nodes -x509 -subj "/O=IT/CN=ceph-mgr-dashboard" \ -days 3650 -keyout dashboard.key -out dashboard.crt -extensions v3_ca
#⽽后配置dashboard加载证书:
ceph config-key set mgr mgr/dashboard/crt -i dashboard.crt ~]$ ceph config-key set mgr mgr/dashboard/key -i dashboard.key
#配置监听的地址和端⼝:
ceph config set mgr mgr/dashboard/server_addr 0.0.0.0 ~]$ ceph config set mgr mgr/dashboard/server_port 8443
#也可以分别为每个mgr实例配置监听的地址和端⼝,将下⾯命令格式中的$name替换为mgr实例的名称即可
ceph config set mgr mgr/dashboard/$name/server_addr $IP
ceph config set mgr mgr/dashboard/$name/server_port $PORT
#确认配置的结果:
ceph mgr services { "dashboard": "https://0.0.0.0:8443/" }
#重新启⽤Dashboard V2
ceph mgr module disable dashboard
ceph mgr module enable dashboard
#配置管理员认证信息,命令格式:
ceph dashboard set-login-credentials <username> <password>
#为admin设置密码:
ceph dashboard set-login-credentials admin [passwd]
#查看mgr节点主机
ceph status1.6 集群状态检查运维相关命令
- 命令:ceph-s
1.输出信息
2.集群ID
3.集群运行状况
4.监视器地图版本号和监视器仲裁的状态
5.OSD地图版本号和OSD的状态
6.归置组地图版本
7.归置组和存储池数量
8.所存储数据理论上的数量和所存储对象的数量
9.所存储数据的总量1.6.1 获取集群的即时状态
- ceph pg stat # 查看集群当前PG状态
192 pgs: 192 active+clean; 29 GiB data, 95 GiB used, 1.4 TiB / 1.5 TiB avail- ceph osd pool stats # 查看集群当前所有状态
pool cephfs-metadata id 1
nothing is going on
pool cephfs-data id 2
nothing is going on
pool rbddata01 id 3
nothing is going on- ceph df # 查看集群的存储情况
# 简介
输出两段内容:GLOBAL和POOLS
·GLOBAL:存储量概览
·POOLS:存储池列表和每个存储池的理论用量,但出不反映副本、克隆数据或快照
GLOBAL段
·SIZE:集群的整体存储容量
·AVAILL:集群中可以使用的可用空间容量
·RAWUSED:已用的原始存储量
·%RAWUSED:已用的原始存储百分比。将此数字与full ratio和near full ratio搭配使”,可确保您不会用完集群的容量。
#实际数值
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
1.5 TiB 1.4 TiB 95 GiB 6.34
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
cephfs-metadata 1 160 MiB 0.04 443 GiB 80
cephfs-data 2 29 GiB 6.06 443 GiB 19309
rbddata01 3 133 B 0 443 GiB 5 - ceph df detail
1.6.2 检查OSD和Mon状态
- ceph osd stat #简要的osd运行状态
-
ceph osd dump #输出完整的详细信息
-
ceph osd tree #还可以根据OSD在CRUSH地图中的位置查看OSD
-
Ceph将列显CRUSH树及主机、它的OSD、OSD是否已启动及其权重
集群中存在多个Mon主机时,应该在启动集群之后读取或写入数据之前检查Mon的仲裁状态;事实上,管理员也应该定期检查这种仲裁结果
- 显示监视器映射:ceph mon stat命令或者ceph mon dump
-
显示仲裁状态:ceph quorum_status
-
ceph osd tree #还可以根据OSD在CRUSH地图中的位置查看OSD
1.6.3 使用管理套接字
Ceph的管理套接字接口常用于查询守护进程
1.套接字默认保存于/var/run/ceph目录
2.此接口的使用不能以远程方式进程
ceph --admin-daemon/var/run/ceph/socker-name
#获取使用帮助:ceph--admin-daemon/var/run/ceph/socket-name help
#例子
ceph --admin-daemon /var/run/ceph/ceph-mgr.zhc-harbor-ceph-test-01.asok status
{
"metadata": {},
"dentry_count": 0,
"dentry_pinned_count": 0,
"id": 0,
"inst": {
"name": {
"type": "mgr",
"num": 4419
},
"addr": {
"nonce": 382839,
"addr": "10.200.10.145:0"
}
},
"inst_str": "mgr.4419 10.200.10.145:0/382839",
"addr_str": "10.200.10.145:0/382839",
"inode_count": 0,
"mds_epoch": 0,
"osd_epoch": 23,
"osd_epoch_barrier": 0,
"blacklisted": false
}1.6.4 停止或者启动Ceph集群
启动
- 1、以与停止过程相关的顺序启动节点
Ceph Monitor
Ceph Manager
Ceph OSD
元数据服务器
网关,例如NFS Ganesha或对象网关
存储客户端
- 2、删除noout标志
命令:ceph osd unset noout
停止
- 1、告知Ceph集群不要将OSD标记为out
命令:ceph osd set noout
- 2、按如下顺序停止守护进程和节点
- 存储客户端
- 网关,例如NFS Ganesha或对象网关
- 元数据服务器
- Ceph OSD
- Ceph Manager·Ceph Monitor
1.6.5 Ceph启动配置文件
Ceph配置文件结构叙述
配置文件可以在启动时配置Ceph存储群集中的所有Ceph守护程序或特定类型的所有Ceph守护程序。
- Ceph配置文件在启动时(覆盖默认值)配置Ceph守护进程。
-
Ceph配置文件使用ini样式语法。 Ceph配置默认以(# ;)来表示注释
-
可以为守护程序的特定实例指定设置。可以通过输入实例类型(以句点(。)和实例ID分隔)来指定实例。
-
Ceph OSD守护程序的实例ID始终为数字,但对于Ceph监视器,它可以为字母数字。
要配置一系列守护程序,必须将这些设置包括在将接收配置的过程中,如下所示:
- 1、[global]:影响Ceph存储集群中的所有守护进程
-
2、[osd]:影响Ceph存储集群中的所有ceph-osd守护进程,并覆盖[global]中的相同设置
-
3、[mon]:影响Ceph存储集群中的所有ceph-mon守护进程,并覆盖[global]中的相同设置
-
4、[client]:影响所有Ceph客户端(例如,已安装的Ceph块设备,Ceph对象网关等)
默认配置文件读取的位置
$CEPH CONF(SCEPH CONF环境变量后的路径)
-c路径/路径(-c命令行参数)
/etc/ceph/ceph.conf
〜/.ceph/配置
./ceph.conf(在当前工作目录中)
元变量
- 元变量极大地简化了Ceph存储集群的配置。
-
在配置值中设置了元变量时,Ceph会将其扩展为具体值。
-
在[globall,[osd],[mon]或Ceph配置文件的[client]部分。
-
但是,也可以将它们与管理套接字一起使用。Ceph元变量类似于Bash shell扩展。
常用的元参数
Scluster:当前Ceph集群的名称
Stype:当前服务的类型名称,可能会展开为osd或mon
Sid:进程的标识符,例如对osd.0来说,其标识符为0
Shost:守护进程所在主机的主机名
Sname:其值为$type.$id1.7 存储池/PG/CRUSH
RADOS存储集群提供的基础存储服务需要由<存储池(Pool)>,分割为逻辑存储区域,此类的逻辑区或者谁对象数据的名称空间
- admin可以为特定的应用程序存储不同的数据类型的需求分别创建专用的存储池,RBD存储池/RGW存储池,而已可以为某些特定的用户创建
- 存储池可以再进一步细分为一到多个名称空间(namespace)
- 客户端存储数据的时候,需要事先指定存储池的名称/用户名和秘钥完成认证,再将一直维持与指定的存储池连接,也可以把存储池看作是客户端的I/O接口
存储池的类型
- 副本池(Replicated) -> 把每一个对象在集群中的存储为多个副本,其中存储在OSD的为主福本,副本的数量由admin指定
- 纠删码池(erasure code) -> 把各对象存储为N=K+M个块设备,其中K为数据块的数量,M为编码块数量,因此存储池的尺寸为K+M (出现就是为解决ceph太浪费存储)
副本池I/O工作逻辑图
- 将一个数据对象存储为多个副本
- 写操作时候,Ceph客户端使用CRUSH算法来计算对象的PG ID和Primary OSD
- 主OSD根据设定好的副本数量,对象的名称,存储池名称和集群运行图(Cluster Map)计算出PG的各辅助OSD,然后将主OSD数据同步给这些辅助OSD
1.7.1 CRUSH
CRUSH(Controlled Replication Under Scalable Hashing) 它是一种数据分布式算法,类似于一致性哈希算法用于RADOS存储集群控制数据的分布
正常的情况下如果把一个对象直接映射到OSD之上会导致二者之间紧密的耦合性关系,在OSD设备变动时候不可避免的会对整个集群产生干扰,于是Ceph将一个对象映射进RADOS集群分成两步
- 首先是以一致性哈希算法将对象名称映射到PG中去
- 然后将PG的ID基于CRUSH算法映射到OSD中
- 此过程都是用<实时计算>方式完成,非传统的查表,有效的规避了任何组件被中心化的可能性,让集群规模扩展不受到限制
1.7.2 操作存储池
- 获取存储池的相关信息
#列出存储池
ceph osd pool ls (detail 加它更详细)
#查看指定的存储池的详细信息
ceph osd pool get pool_name all
#获取存储池的统计数据
ceph osd pool stats [pool-name]
#显示存储池的用量(好用查看现用量)
rados df
#重命名存储池
ceph osd pool rename old-name new-name - 删除存储池
意外的删除存储池会导致数据丢失,因此Ceph实施了两个机制来防止删除存储池,要删除存储池,必须先禁用两个机制
1.第一个机制NODELETE标志,该值需要设置为false,默认为false
2.第二个机制集群范围的配置参数mon allow pool delete,默认为false,表示不能删除存储池
#机制一解决,查看命令
ceph osd pool get pool-name nodelete
#修改命令
ceph osd pool set pool-name nodelete false
#机制二解决,临时解决(建议删除之前将这个值设置为true,删除后再改会false)
ceph tell mon.* injectargs --mon-allow-pool-delete={true/false}
#永久方式编辑ceph.conf文件加入一下内容
[mon]
mon_allow_pool_delete = true
#更新覆盖每个节点的配置文件
ceph-deploy --overwrite-conf config push mon01 mon02 mon03
#重启mon才能执行删除
systemctl restart ceph-mon.target- 删除命令 : ceph osd pool rm pool-name pool-name –yes-i-really-mean-it (两次的输入名称确认)
1.7.3 设置存储池配额
Ceph支持为存储池设置可以存储对象的最大数量(Max_objects)和可以占用的最大空间(Max_bytes)两个维度的配额
命令格式: ceph osd pool set-quota max_objects|max_bytes-
获取存储池相关配额信息: ceph osd pool get-quota
配置存储池参数
获取配置: ceph osd pool get-
设定配置: ceph osd pool set
| 常用参数 | 参数作用描述 |
|---|---|
| -size | 存储池中的对象副本数 |
| -min_size | I/O所需要的最小副本数 |
| -pg_num | 存储池的PG数量 |
| -pgpnum | 计算数据归置时要使用的PG的有效数量 |
| -crush ruleset | 用于在集群中映射对象归置的规则组 |
| -nodelete | 控制是否可删除存储池 |
| -nopgchange | 控制是否可更改存储池的pg_num和pgp_num |
| -nosizechange | 控制是否可更改存储池的大小 |
| -noscrub和nodeep-scrub | 控制是否可整理或深层整理存储池以解决临时高I/O负载的问题 |
| scrub_min_interval | 集群负载较低时整理存储池的最小时间间隔;默认值为0,表示其取值 来自于配置文件中的osd_scrub_min_interval参数 |
| scrub_max_interval | 整理存储池的最大时间间隔;默认值为0,表示其取值来自于配置文件 中的osd_scrub_max_interval参数 |
| deep_scrub_interval | 深层整理存储池的间隔;默认值为0,表示其取值来自于配置文件中的 osd_deep_scrub参数 |
1.7.4 存储池快照
- 存储池快照是指整个存储池的状态快照
- 通过存储池快照,可以保留存储池的状态历史
- 创建存储池快照可能需要大量的存储空间,具体取决于存储池的大小
创建存储池快照
- ceph osd pool mksnap
- rados -p mksnap
列出存储池快照
- rados -p lssnap
删除存储池快照
- ceph osd pool rmsnap
- rados -p rmsnap
回滚存储到指定的快照
- rados -p rollback
1.7.5 存储池名称空间
存储池的名称空间不常用,但是每一个存储池都是有自己的名称空间的
namespace是池中对象的逻辑组,可以限制用户对池的访问,使得用户只能存储或检索这个namespace内的对象,默认情况下每一个池包含一个具有空名称的namespace
- namespace的有优点是能够将用户的访问权限池的某个部分,namespace目前仅支持使用
librados的应用 -
如果要在命名空间内存储对象,客户端应用必须提供池和名称空间的名称
-
rados命令可以使用 -N name 或者 –namespace= 来选择存储池和检索池中指定的名称空间对象
#例如向对象存储的poolname池中的-N system上传一个名为srv的本地路径为path的对象(namespace不需要手动创建)
rados -p poolname -N system put srv path
#查看当前创建的namespace下的对象
rados -p poolname -N system ls
#查看当前存储池中的所有namespacce的对象
rados -p poolname --all ls
#使用python转换成json查看
rados -p poolname --all ls --format=json | python -jsob.tool
- fromat=json 返回json格式的结果1.7.6 数据的压缩
BlueStore存储引擎提供即时的数据压缩,来节省磁盘空间压缩的算法有none,zlib,lz4,zstd,snappy等
zstd有较好的压缩比,但比较消耗CPU
lz4和snappy对CPU占用比例较低
不建议使用zlib
- 启动压缩 : ceph osd pool set compression_algorithm snappy
- 默认为snappy
- 压缩模式 : ceph osd pol set compression_mode
- none 不压缩
- passive 若提示COMPRESSIBLE,则压缩
- aggressive:除非提示INCOMPRESSIBLE,否则就压缩
- force:始终压缩
其他使用参数
- compression required ratio:指定压缩比,取值格式为双精度浮点型,其值为SIZECOMPRESSED/STZEORIGINAL,即压缩后的大小与原始内容大小的比值,默认为.875
- compression max blob size:压缩对象的最大体积,无符号整数型数值,默认为0
- compression_min_blob_size:压缩对象的最小体积,无符号整数型数值,默认为0
全局压缩选项
可在ceph配置文件中设置压缩属性,它将对所有的存储池生效
bluestore_compression_algorithm
bluestore_compression_mode
bluestore_compression_required_ratio
bluestore_compression_min_blob_size
bluestore_compression_max_blob_size
bluestore_compression_min_blob_size_ssd
bluestore_compression_max_blob_size_ssd
bluestore_compression_min_blob_size_hdd
bluestore_compression_max_blob_size_hdd1.7.7 纠删码存储池
纠删码池使用的不是复制来保护对象的数据方式,相对于复制池,纠删码池会节约存储空间,但是需要更多的计算资源且纠删码池只支持对象存储,不支持快照。空间利用率高:K/N , K为数据块量,N为加上编码块量的总块数
纠删码的工作原理
纠删码的存储方式是将每一个object划分成更小的数据块,每一个数据块叫做
data chunk,再用编码快coding chunk对它们进行编码,最后将这些数据块和编码块存储到ceph集群的不同故障域中,从而保证数据的安全,纠删码概念的核心:n=k+m
- k -> 原始object被划分成的数据块的个数
- m -> 附加到所有原始数据块的额外编码块的个数
- n -> 执行纠删码处理后,所创建的块的总数- 创建纠删码池 : ceph osd pool create erasure [erasure-code-profile] [crush-rule-name] [expected-num-objects]
- 未指定要使用的纠删编码配置文件时,创建命令会为其自动创建一个,并在创建相关的CRUSH规 则集时使用到它
- 默认配置文件自动定义k=2和m=1,这意味着Ceph将通过三个OSD扩展对象数据,并且可以丢失 其中一个OSD而不会丢失数据,因此,在冗余效果上,它相当于一个大小为2的副本池 ,不过, 其存储空间有效利用率为2/3而非1/2
创建纠删码存储池
#示例
ceph osd erasure-code-profile set EC-profile cursh-failure-domain=osd k=3 m=2
#参数解析
k:一个对象拆成多少个数据块。默认值为 2
m:允许最大故障的OSD数目。默认值为1
directory:插件库的位置。默认值为 /usr/lib64/ceph/erasure-code
plugin:定义要使用的纠删代码插件。默认值为jerasure
crush-failure-domain:定义CRUSH故障域,它控制区块放置。默认情况下,为host,这可以确保对象的区块放置到不同主机的OSD上。如果设置为osd,则对象的区块可以放置到同一主机的OSD上。将故障域设置为osd时弹性欠佳,如果主机出现故障,则该主机上的所有OSD都会失败。设置为rack可以确保ceph不会将两个区块存储在同一个机架中。
crush-device-class:仅将某一类别设备支持的OSD用于池。典型的类别可能包括hdd、ssd 或nvme
crush-root:设置CRUSH规则集的根节点
key=value:自定义键值对
technique:每个插件提供一组不同的技术来实施不同的算法。对于Jerasure插件,默认的技术是reed_sol_van。还提供其他的技术:reed_sol_r6_op、cauchy_orig、cauchy_good、liberation、blaum_roth和liber8tion
# 例如,如果所需的体系结构必须承受两个OSD的丢失,并且存储开销为40%
ceph osd erasure-code-profile set myprofile k=4 m=2 crush-failure-domain=osd纠删码常用命令
#列出现有的配置
ceph osd erasure-code-profile ls
#删除现有的配置
ceph osd erasure-code-profile rm profile-name
#查看现有的配置
ceph osd erasure-code-profile get profile-name
#查看纠删码池状态(纠删码池的操作)
ceph osd dump |grep -i EC-pool
#添加数据到纠删码池(纠删码池的操作)
rados -p EC-pool ls
rados -p EC-pool put object1 hello.txt
#查看数据状态(纠删码池的操作)
ceph osd map EC-pool object1
#读取数据(纠删码池的操作)
rados -p EC-pool get object1 /tmp/object1纠删码插件
Ceph支持以插件方式加载使用的纠删编码插件,存储管理员可根据存储场景的需 要优化选择合用的插件。目前,Ceph支持的插件jerasure/lrc/isa
- jerasure:最为通用的和灵活的纠删编码插件,它也是纠删码池默认使用的插件;不过, 任何一个OSD成员的丢失,都需要余下的所有成员OSD参与恢复过程;另外,使用此类插 件时,管理员还可以通过technique选项指定要使用的编码技术
- reed_sol_van:最灵活的编码技术,管理员仅需提供k和m参数即可
- cauchy_good:更快的编码技术,但需要小心设置PACKETSIZE参数
- reed_sol_r6_op、liberation、blaum_roth或liber8tion (仅支持使用m=2的编码技术,功能特性 类同于RAID 6 )
- lrc:全称为Locally Repairable Erasure Code,即本地修复纠删码,除了默认的m个编码 块之外,它会额外在本地创建指定数量(l)的奇偶校验块,从而在一个OSD丢失时,可 以仅通过l个奇偶校验块完成恢复
- isa:仅支持运行在intel CPU之上的纠删编码插件,它支持reed_sol_van和cauchy两种技术
1.7.8 纠删码池I/O
例如,把包含数据”ABCDEFGHI”的对象NYAN保存到存储池中时,假设纠删码算法会将内容分割为三个数据块:第一个包含”ABC”,第二个为”DEF”,最后一个为”GHI”,并为这三个数据块额外创建两个编码块:第四个”YXY”和第五个”GQC”在有着两个编码块配置的存储池中,它容许至多两个OSD不可用而不影响数据的可用性。假设,在某个时刻OSD1和OSD3因故无法正常响应客户端请求,这意味着客户端仅能读取到”ABC”、”DEF”和”OGC”,此时纠删编码算法会通过计算重那家出”GHI”和”YXY”
通过将K块的数据转换成N块,假设N=K+M,其中的M代表纠删码算法添加的额外冗余或冗余块的数量以提供冗余机制(既编码块),而N则表示在纠删码后要创建的块的总数,其可以故障的总块数量为M(N-K个).类似RAID 5
- 纠删码是一种前向纠错(FEC)代码
-
纠删码池减少了确保数据持久性所需的磁盘空间量,但计算量上却比副本存储池要更贵一此
-
RGW可以使用纠删码存储池,但RBD不支持
1.7.9 查看pg在osd上的分布
#将osd的map信息输出到osdmap文件中
ceph osd getmap -o osdmap
#将crushmap信息输出
ceph osd getcrushmap -o crushmap
#使用工具找到指定的池上的pg具体在osd上的分布信息
osdmaptool osdmap --import-cursh crushmap --test-map-pgs --pool 161.8 归置组
归置组(Placement Group)是用于跨OSD将数据存储在某个存储池中的内部数据结构.在OSD守护进程和Ceph客户端之间生成了一个中间层,CRUSH算法负责将每个对象动态映射到一个归置组,然后再将每个归置组动态映射到一个或多个OSD守护进程,从而能够支持在新的OSD设备上线时动态进行数据重新平衡
- 相对于存储池来说,PG是一个虚拟组件,它是对象映射到存储池时使用的虚拟层
-
出于规模伸缩及性能方面的考虑,Ceph将存储池细分为归置组,把每个单独的对象映射到归置组,并将归置组分配给一个主OSD
-
存储池由一系列的归置组组成,而CRUSH算法则根据集群运行图和集群状态,将各PG均匀、伪随机地分布到集群中的OSD之上
-
若某OSD失败或需要对集群进行重新平衡,Ceph则移动或复制整个归置组而无需单独寻址每个对象
生产情况下归置组的使用
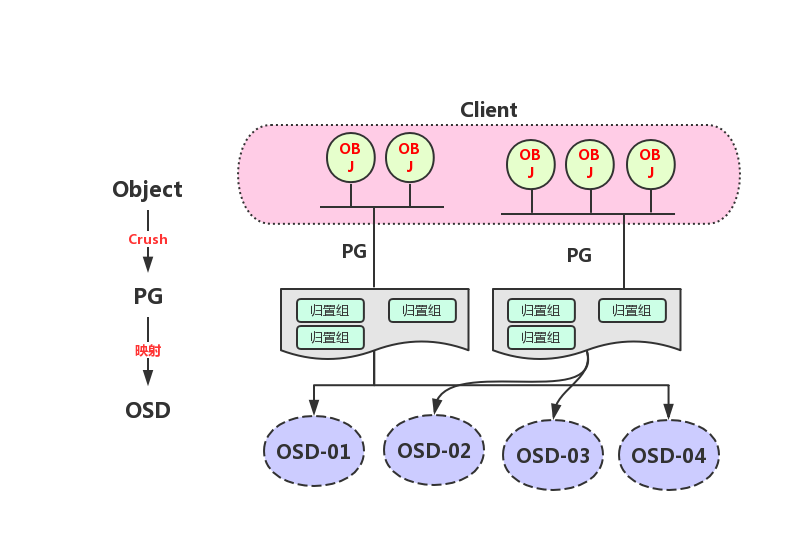
- 每个池有多个安置组。
-
CRUSH将pg动态映射到OSDs。
-
当Ceph客户端存储对象时,CRUSH会将每个对象映射到一个放置组。
1.8.1 归置组数量设定
归置组的数量由管理员在创建存储池的时候指定,然后由CRUSH负责创建和使用,通常PG的数量应该是数据的合理粒度的子集,例如: 一个包含256个PG的储存池意味着每个PG包含大约1/256的存储池数据.当需要将PG从一个OSD移动到另外一个OSD时候,PG的数量会对性能产生影响.PG的数量在集群分发和数据平衡中扮演重要作用
PG对集群的影响
- PG数量少,Ceph将会不得不同时移动相当数量的数据,产生网络负载对集群的正常性能输出也有负面影响
- 如果过多的PG数量场景中移动极少量的数据时候,Ceph将会占用过多的CPU和MEM,从而对集群的计算资源产生不利影响
PG数量的建议
- 在所有OSD之前进行数据持久化存储及完成数据分布会需要很多的归置组,但是PG的数量应该减少到最大性能需要的最小数量,节省资源
- 正常情况下对于有超过50个OSD的RADOS集群,建议每个OSD大约有50-100个PG用来平衡资源,可以获得更好的数据持久性和数据分布,如果更大的规模则OSD数量100-200个PG
- 具体需要使用多少个PG可以通过公式计算,把值类似四舍五入到最近的2的N次幂
- (共计OSD * 最大OSD能拥有的PG数量)/Replication factor => 共计PG
- 一个RADOS集群上可能会存在多个存储池,因此管理员还需要考虑所有存储池上的PG分布后每个OSD需要的映射的PG数量
1.8.2 归置组的状态
依据PG当前的工作特性或工作进程所处的阶段,它总是处于某个或某些个状态中,常见的状态为Actice+clean
- Active
- 主OSD和各辅助OSD均处于就绪状态,可以正常服务于客户端的IO请求
- 一般情况,Peering操作过程完成后即会转入Active状态
- Clear
- 主OSD和各辅助OSD均处于就绪状态,所有对象的副本数量均符合期望,并且PG的活动集和上行集是为同一组的OSD
- 活动集(Acting Set) : 由PG当前的主OSD和所有的处于活动状态的辅助OSD组成,这组OSD负责执行PG上数据对象的存取操作I/O
- 上行集(Up Set) : 根据CRUSH的工作方式,集群拓扑架构的变动可能导致PG相应的OSD变动或扩展至其他的OSD之上,这个新的OSD集也被称为PG的上行集,它映射到的新的OSD集可能部分地与原有的OSD集重合,也可能会完全的不相干,上行集OSD需要从当前的活动集OSD上复制数据的对象,在所有对象的同步完成之后,上行集成为新的活动集,而PG也将会转为活动(Active)状态
- Peering
- 一个PG中的所有OSD必须就它们所持有的数据对象状态达成一致,而对等(Peering)即为让其OSD从不一致转为一致的过程
- Degraded
- 在OSD标记为时候,所有映射到此OSD的PG转入降级的状态(degraded)
- 当这个OSD重启后并且完成Peering操作,PG将会重新转换Clean
- 一旦OSD标记为down的时间超过了5分钟,它将会被标记出集群,Ceph将对降级状态的PG启动恢复操作,直到所有的因此降级的PG重回Clean状态
- 当内部的OSD上某个对象不可用或者突然崩溃时候,PG也会被标记为降级状态,直到对象从某个权威副本上正确的恢复
- Stale
- 每一个OSD都要周期性的想Rados集群中的监视器报告作为主OSD所持有的PG的最新统计数据,因此任何原因导致的主OSD无法正常工作向监视器报告情况,或者由其他的OSD报个某个OSD已经down,则所有以这个主OSD为主的PG立即被标记为STALE状态
- Undersized
- PG中的副本数少于存储池定义的个数会导致转入undersized状态,恢复和回填操作在随后的启动修复副本数的为期望值
- Scrubbing
- 各OSD还需要周期性的检查其所持有的数据对象的完整性,以确保所有对等的OSD上的数据一致,对于此类的检查过程中的PG会被标记为scrubbing状态,这也通常被称为light scrubs,shallow scrubs
- 另外,PG有时候还需要进行深度的Scrubs检查来确保同一对象相关的OSD上能够按位匹配,此时PG将会处于Scrubbing+deep状态
- Recovering
- 添加一个新的OSD到存储中集群中或当一个OSD宕机,PG可能被CRUSH重新映射而将持有与此不同的OSD集,这些处于内部数据同步过程中的PG会被标记为Recovering状态
- Backfilling
- 新的OSD加入存储集群后,Ceph会进入数据重新均匀的状态,即一些数据对象会正在进程后台重新OSD移动到新的OSD之上
1.9 客户端工作流程
客户端IO简要流程
Ceph客户端使用以下步骤来计算PG ID
- 客户端输入存储池名称以及对象名称,pool=pool1 以及object-id=obj1
- 获取对象名称并通过一致性哈希算法对其进行哈希运算,即Hash[obj1],obj1为对象名称
- 将计算出对象的标识符哈希码与PG位图掩码进行与运算获得目标的PG标识符 -> PG-ID
- 公式 : PG-ID=func(hash(obj)&m,r) -> 其中obj为对象标识,m是当前存储池中PG的位图掩码,变量r是指复制因子(指副本数),用于确定目标PG中的OSD数量
- CRUSH根据集群运行图计算出与目标PG对应的有序的OSD集合,并且确定出其主OSD
- Client获取到存储池名称对应的数据标识符,例如pool -> 11
- Client将存储池的ID加入到PG-ID, 例如 -> 11.1217
- Client通过直接与PG映射到主OSD通信来执行写入/读取/删除类似的对象操作
1.10 Ceph配置文件说明
默认情况下,无论是ceph的服务端还是客户端,配置文件都存储在/etc/ceph/ceph.conf文件中
如果修改了配置参数,必须使用/etc/ceph/ceph.conf文件在所有节点(包括客户端)上保持一致。
- ceph.conf 采用基于 INI 的文件格式,包含具有 Ceph 守护进程和客户端相关配置的多个部分。每个部分具有一个使用 [name] 标头定义的名称,以及键值对的一个或多个参数
-
配置文件使用#和;来注释
-
参数名称可以使用空格、下划线、中横线来作为分隔符。如osd journal size 、 osd_jounrnal_size 、 osd-journal-size是有效且等同的参数名称
#通过中括号将特定守护进程的设置分组在一起
[global] 部分,存储所有守护进程之间通用配置。它应用到读取配置文件的所有进程,包括客户端。可以在更为具体的部分中覆盖此处设置的参数
[mon] 部分,监视器 (MON) 相关的配置
[osd] 部分,OSD 守护进程相关的配置
[mgr] 部分,管理器 (MGR) 相关的配置
[mds] 部分,元数据服务器 (MDS) 相关的配置
[client] 部分,所有客户端的配置1.10.1 元变量
所谓元变量是即ceph内置的变量。可以用它来简化ceph.conf文件的配置:
-
scluster:Ceph存储集群的名称。默认为ceph,在/etc/sysconfig/ceph文件中定义。例如,1ogfi1le参数的默认值是/var/log/ceph/scluster-sname.1og。在扩展之后,它变为/var/log/seph/ceph-mon.ceph-node1.1og -
stype:守护进程类型。监控器使用mon;osd使用osd,元数据服务器使用mds,管理器使用mgr,客户端应用使用client。
如在tglobal1部分中将pid file参数设定义为/vax/run/scluster/stype.sid.pid
它会扩展为/var/run/ceph/osd.o.pid,表示ID为0的osD。
对于在ceph-node1上运行的MoN守护进程,它扩展为/vax/run/ceph/mon.ceph-node1.pid
-
sid:守护进程实例rD。对于ceph-nodei上的MON,设置为ceph-node1。对于osd.1,它设置为1。如果是客户端应用,这是用户名 -
sname:守护进程名称和实例ID。这是stype.sid的快捷方式 -
shost:其上运行了守护进程的主机的名称
1.10.2 查看运行时的配置信息
#列出所有参数及其当前值
语法:ceph daemon type.id config show
示例:ceph daemon osd.0 config show
#获取具体参数的值
语法:ceph daemon type.id config get parameter
示例:ceph daemon mds.servera config get mds_data1.10.3 Ceph守护进程启停操作
| 管理ceph的系统守护进程 | 具体命令 |
|---|---|
| Stop a specific daemon | systemct1 stop ceph-Stype@sid |
| Stop all OSD daemons | systemct1 stop ceph-osd.target |
| Stop all daemons | systemct1 stop ceph.target |
| Start a specific daemon | systemct1 start ceph-Stype@sid |
| Start all OSD daemons | systemct1 start ceph-osd.target |
| Start all daemons | systemct1 start ceph.target |
| Restart a specific daemon | systemct1 restart ceph-stype@sid |
| Restart all OSD daemons | systemctl restart ceph-osd.target |
| Restart all daemons | systemct1 restart ceph.target |
















 5260
5260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











