








Spark分区原理分析
介绍
分区是指如何把RDD分布在spark集群的各个节点的操作。以及一个RDD能够分多少个分区。
一个分区是大型分布式数据集的逻辑块。
那么思考一下:分区数如何映射到spark的任务数?如何验证?分区和任务如何对应到本地的数据?
Spark使用分区来管理数据,这些分区有助于并行化分布式数据处理,并以最少的网络流量在executors之间发送数据。
默认情况下,Spark尝试从靠近它的节点读取数据到RDD。由于Spark通常访问分布式分区数据,为了优化transformation(转换)操作,它创建分区来保存数据块。
存在在HDFS或Cassandra中的分区数据是一一对应的(由于相同的原因进行分区)。
默认情况下,每个HDFS的分区文件(默认分区文件块大小是64M)都会创建一个RDD分区。
默认情况下,不需要程序员干预,RDD会自动进行分区。但有时候你需要为你的应用程序,调整分区的大小,或者使用另一种分区方案。
你可以通过方法def getPartitions: Array[Partition]来获取RDD的分区数量。
在spark-shell中执行以下代码:
val v = sc.parallelize(1 to 100)
scala> v.getNumPartitions
res2: Int = 20 //RDD的分区数是20?why? 原因在后面讲解。
一般来说分区数和任务数是相等的。以上代码可以看到分区是20个,再从spark管理界面上看,有20个任务。
可以通过参数指定RDD的分区数:
val v = sc.parallelize(1 to 100, 2)
scala> v.getNumPartitions
res2: Int = 2 //RDD的分区数是2
可以看出,指定了分区数量以后,输出的是指定的分区数。通过界面上看,只有2个任务。
分区大小对Spark性能的影响
分区块越小,分区数量就会越多。分区数据就会分布在更多的worker节点上。但分区越多意味着处理分区的计算任务越多,太大的分区数量(任务数量)可能是导致Spark任务运行效率低下的原因之一。
所以,太大或太小的分区都有可能导致Spark任务执行效率低下。那么,应该如何设置RDD的分区?
Spark只能为RDD的每个分区运行1个并发任务,直到达到Spark集群的CPU数量。
所以,如果你有一个拥有50个CPU的Spark集群,那么你可以让RDD至少有50个分区(或者是CPU数量的2到3倍)。
一个比较好的分区数的值至少是executors的数量。可以通过参数设置RDD的默认分区数,也就是我们所说的并行度:
sc.defaultParallelism
上一节中,当没有设定分区时,在我的Spark集群中默认的分区数是20,是因为在Spark默认配置文件:conf/spark-defaults.conf中我设置了变量:
spark.default.parallelism 20
同样,RDD的action函数产生的输出文件数量,也是由分区的数量来决定的。
分区数量的上限,取决于executor的可用内存大小。
RDD执行的第一个transformation函数的分区数量,决定了在该RDD上执行的后续一系列处理过程的分区数量。例如从hdfs读取数据的函数:
sc.textFile(path, partition)
当使用函数 rdd = SparkContext().textFile("hdfs://…/file.txt")时,你得到的分区数量可能很少,这将会和HDFS的块的多少相等。但当你的文件中的行比较大时,得到的分区可能更少。
你也可以通过textFile函数的第2个参数指定读取的分区数量,但该分区数量:
sc.textFile("hdfs://host:port/path", 200)
这样读取path的文件后,会生成200个分区。
注意:第2个参数指定的分区数,必须大于等于2。
注意:以上描述只是对非压缩文件适用,对于压缩文件不能在textFile中指定分区数,而是要进行repartition:
rdd = sc.textFile('demo.gz')
rdd = rdd.repartition(100)
一些函数,例如:map,flatMap,filter不会保留分区。会把每个函数应用到每一个分区上。
RDD的Repartition
函数的定义定义如下:
/**
* Return a new RDD that has exactly numPartitions partitions.
* Can increase or decrease the level of parallelism in this RDD. Internally, this uses a shuffle to redistribute data.
* If you are decreasing the number of partitions in this RDD, consider using coalesce, which can avoid performing a shuffle.
*/
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
从代码上可以看到,repartition是shuffle和numPartitions分区的合并操作。
若分区策略不符合你的应用场景,你可以编写自己的Partitioner。
coalesce 转换
改函数的代码如下:
/**
* Return a new RDD that is reduced into numPartitions partitions.
*
* This results in a narrow dependency, e.g. if you go from 1000 partitions
* to 100 partitions, there will not be a shuffle, instead each of the 100
* new partitions will claim 10 of the current partitions.
*
* However, if you’re doing a drastic coalesce, e.g. to numPartitions = 1,
* this may result in your computation taking place on fewer nodes than
* you like (e.g. one node in the case of numPartitions = 1). To avoid this,
* you can pass shuffle = true. This will add a shuffle step, but means the
* current upstream partitions will be executed in parallel (per whatever
* the current partitioning is).
*
* Note: With shuffle = true, you can actually coalesce to a larger number
* of partitions. This is useful if you have a small number of partitions,
* say 100, potentially with a few partitions being abnormally large. Calling
* coalesce(1000, shuffle = true) will result in 1000 partitions with the
* data distributed using a hash partitioner.
*/
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {
… …
}
coalesce转换用于更改分区数。它可以根据shuffle标志触发RDD shuffle(默认情况下禁用shuffle,即为false)
从以上代码注释可以看出:该函数是一个合并分区的操作,一般该函数用来进行narrow转换。为了让该函数并行执行,通常把shuffle的值设置成true。
coalesce使用举例
scala> val rdd = sc.parallelize(0 to 10, 8)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at :24
scala> rdd.partitions.size
res0: Int = 8
scala> rdd.coalesce(numPartitions=8, shuffle=false) (1)
res1: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[1] at coalesce at :27
scala> res1.toDebugString
res2: String =
(8) CoalescedRDD[1] at coalesce at :27 []
| ParallelCollectionRDD[0] at parallelize at :24 []
scala> rdd.coalesce(numPartitions=8, shuffle=true)
res3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[5] at coalesce at :27
scala> res3.toDebugString
res4: String =
(8) MapPartitionsRDD[5] at coalesce at :27 []
| CoalescedRDD[4] at coalesce at :27 []
| ShuffledRDD[3] at coalesce at :27 []
+-(8) MapPartitionsRDD[2] at coalesce at :27 []
| ParallelCollectionRDD[0] at parallelize at :24 []
注意:
- 默认情况下coalesce是不会进行shuffle。
- 另外,分区数和源RDD的分区数保持一致。
分区相关参数
spark.default.parallelism
设置要用于HashPartitioner的分区数。它对应于调度程序后端的默认并行度。
它也和以下几个数量对应:
- LocalSchedulerBackend是spark本地执行的调度器,此时,该参数的数量是,本地JVM的线程数。
本地模式的默认并行度的设置源码如下:
case LOCAL_N_REGEX(threads) =>
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*] estimates the number of cores on the machine; local[N] uses exactly N threads.
val threadCount = if (threads == "*") localCpuCount else threads.toInt
- Spark on Mesos的CPU数量,默认是8.
- 总CPU数:totalCoreCount,在CoarseGrainedSchedulerBackend 是2。
如何查看RDD的分区
通过UI查看使用分区的任务执行
启动spark-shell执行以下命令:
scala> val someRDD = sc.parallelize(1 to 100, 4)
someRDD: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[6] at parallelize at :27
scala> someRDD.map(x => x).collect
17/06/20 07:37:54 INFO spark.SparkContext: Starting job: collect at console:30
… …
再通过spark管理界面查看任务执行情况:
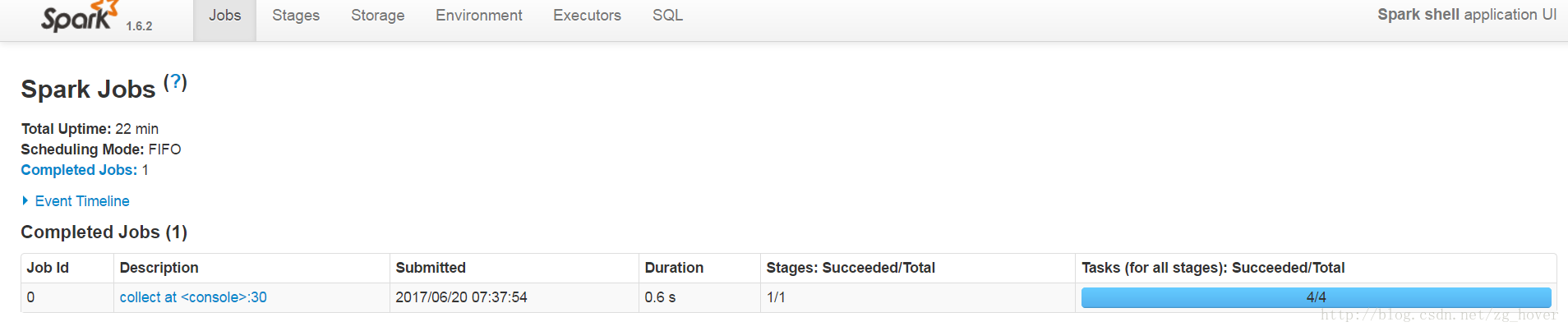
通过UI查看Partition Caching
在终端的spark-shell下执行以下命令:
scala> someRDD.setName("toy").cache
scala> someRDD.map(x => x).collect
再通过spark UI查看cache的情况:

通过函数调用获取分区数量
- RDD.getNumPartitions
- rdd.partitions.size















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









