







sklearn的metrics包中有写好的函数可以直接调用
混淆函数
参考网址:https://www.cnblogs.com/klchang/p/9608412.html
Tensorflow tf.confusion_matrix 中的 num_classes 参数的含义, 与 scikit-learn sklearn.metrics.confusion_matrix 中的 labels 参数相近, 是与标记有关的参数, 表示类的总个数, 但没有列出具体的标记值. 在 Tensorflow 中一般是以整数作为标记, 如果标记为字符串等非整数类型, 则需先转为整数表示. 如果 num_classes 参数为 None, 则把 labels 和 predictions 中的最大值 + 1, 作为 num_classes 参数值.
tf.confusion_matrix 的 weights 参数和 sklearn.metrics.confusion_matrix 的 sample_weight 参数的含义相同, 都是对预测值进行加权, 在此基础上, 计算混淆矩阵单元的值.
import tensorflow as tf
import sklearn.metrics
y_true = [1, 2, 4]
y_pred = [2, 2, 4]
# Build graph with tf.confusion_matrix operation
sess = tf.InteractiveSession()
op = tf.confusion_matrix(y_true, y_pred)
op2 = tf.confusion_matrix(y_true, y_pred, num_classes=6, dtype=tf.float32, weights=tf.constant([0.3, 0.4, 0.3]))
# Execute the graph
print ("confusion matrix in tensorflow: ")
print ("1. default: \n", op.eval())
print ("2. customed: \n", sess.run(op2))
sess.close()
# Use sklearn.metrics.confusion_matrix function
print ("\nconfusion matrix in scikit-learn: ")
print ("1. default: \n", sklearn.metrics.confusion_matrix(y_true, y_pred))
print ("2. customed: \n", sklearn.metrics.confusion_matrix(y_true, y_pred, labels=range(6), sample_weight=[0.3, 0.4, 0.3]))
confusion matrix in tensorflow:
1. default:
[[0 0 0 0 0]
[0 0 1 0 0]
[0 0 1 0 0]
[0 0 0 0 0]
[0 0 0 0 1]]
2. customed:
[[ 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0.30000001 0. 0. 0. ]
[ 0. 0. 0.40000001 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0.30000001 0. ]
[ 0. 0. 0. 0. 0. 0. ]]
confusion matrix in scikit-learn:
1. default:
[[0 1 0]
[0 1 0]
[0 0 1]]
2. customed:
[[ 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0.3 0. 0. 0. ]
[ 0. 0. 0.4 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0.3 0. ]
[ 0. 0. 0. 0. 0. 0. ]]
准确率,精确率,召回率,F1,混淆矩阵
参考网址:https://www.sohu.com/a/135668355_556897
注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。所以,在两者都要求高的情况下,可以用F1来衡量。
混淆矩阵(confusion matrix)是可视化工具。混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目,每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。
如下图,第一行第一列中的43表示有43个实际归属第一类的实例被预测为第一类,同理,第二行第一列的2表示有2个实际归属为第二类的实例被错误预测为第一类。
如有150个样本数据,这些数据分成3类,每类50个。分类结束后得到的混淆矩阵为:
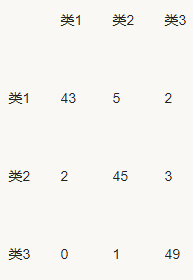
每一行之和为50,表示50个样本,
第一行说明类1的50个样本有43个分类正确,5个错分为类2,2个错分为类3。
from sklearn import metrics
y_true = [1, 2, 4, 5, 5]
y_pred = [2, 2, 4, 5, 5]
print("accuracy:",metrics.accuracy_score(y_true, y_pred)) # 准确率
print("Precision", metrics.precision_score(y_true, y_pred,average="weighted")) # 精确率,精度
print( "Recall", metrics.recall_score(y_true, y_pred,average="weighted")) # 召回率
print( "f1_score", metrics.f1_score(y_true, y_pred,average="weighted")) # F1
print( "confusion_matrix")
print( metrics.confusion_matrix(y_true, y_pred)) # 混淆矩阵
accuracy: 0.8
Precision 0.7
Recall 0.8
f1_score 0.733333333333
confusion_matrix
[[0 1 0 0]
[0 1 0 0]
[0 0 1 0]
[0 0 0 2]]
参考网址:https://blog.csdn.net/weixin_34613450/article/details/81507832
我么也可将这些精确率,召回率,应用多分类问题,把每个类别单独视为”正“,所有其它类型视为”负“。
考虑如下的混淆矩阵:
M = [
[14371, 6500, 9, 0, 0, 2, 316],
[5700, 22205, 454, 20, 0, 11, 23],
[0, 445, 3115, 71, 0, 11, 0],
[0, 0, 160, 112, 0, 0, 0],
[0, 888, 39, 2, 0, 0, 0],
[0, 486, 1196, 30, 0, 74, 0],
[1139, 35, 0, 0, 0, 0, 865]
]
用程序分别计算各个类别的精确率与召回率:
n = len(M)
for i in range(n):
rowsum, colsum = sum(M[i]), sum(M[r][i] for r in range(n))
try:
print 'precision: %s' % (M[i][i]/float(colsum)), 'recall: %s' % (M[i][i]/float(rowsum))
except ZeroDivisionError:
print 'precision: %s' % 0, 'recall: %s' %0
AUC
顾名思义,AUC(Area Under roc Curve)的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的Performance。
Precision/Recall和ROC是两个不同的评价指标和计算方式,一般情况下,检索用前者,分类、识别等用后者。
由于ROC曲线是针对二分类的情况,对于多分类问题,ROC曲线的获取主要有两种方法:
https://blog.csdn.net/YE1215172385/article/details/79443552















 1590
1590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









