






计算机系统
大作业
题 目 程序人生-Hello’s P2P
班 级 2203601
学 生 梅朗潇
指 导 教 师 吴锐
计算机科学与技术学院
2024年5月
在这篇文章中,我们运用一系列工具,如gcc、gdb、edb等,对hello程序从源代码开始的整个生命周期进行详尽的分析。我们将深入研究其预处理、编译、汇编和链接等各个阶段的演变过程以及最终形成可执行文件。除此之外,我们还介绍了与进程管理相关的知识,并深入探讨了系统底层软硬件结合的方面。通过对hello程序的深入剖析,我们能够更全面地理解计算机系统的运作原理。
关键词:预处理; 编译; 汇编; 链接;进程管理; 存储管理; IO管理
目 录
2.2在Ubuntu下预处理的命令.......................................................................... - 5 -
3.2 在Ubuntu下编译的命令............................................................................. - 6 -
4.2 在Ubuntu下汇编的命令............................................................................. - 7 -
5.2 在Ubuntu下链接的命令............................................................................. - 8 -
5.3 可执行目标文件hello的格式.................................................................... - 8 -
6.2 简述壳Shell-bash的作用与处理流程..................................................... - 10 -
6.3 Hello的fork进程创建过程..................................................................... - 10 -
6.6 hello的异常与信号处理............................................................................ - 10 -
7.1 hello的存储器地址空间............................................................................ - 11 -
7.2 Intel逻辑地址到线性地址的变换-段式管理............................................ - 11 -
7.3 Hello的线性地址到物理地址的变换-页式管理....................................... - 11 -
7.4 TLB与四级页表支持下的VA到PA的变换............................................. - 11 -
7.5 三级Cache支持下的物理内存访问.......................................................... - 11 -
7.6 hello进程fork时的内存映射.................................................................. - 11 -
7.7 hello进程execve时的内存映射.............................................................. - 11 -
7.8 缺页故障与缺页中断处理........................................................................... - 11 -
8.1 Linux的IO设备管理方法.......................................................................... - 13 -
8.2 简述Unix IO接口及其函数....................................................................... - 13 -
第1章 概述
1.1 Hello简介
P2P,即Program to Process。对于Hello程序,就是指作为Program的hello.c转变到Process的运行时进程。P2P一般经历四个步骤,预处理、编译、汇编、链接。由C语言编写的hello.c文件经过预处理得到hello.i,hello.i文件经过编译得到hello.s,由汇编语言构成的hello.s经过汇编后生成可重定位目标文件hello.o,hello.o文件和其他系统目标文件经过链接器生成最后的可执行文件hello。然后就可以在shell中执行hello,shell为它分配进程空间,得到一个hello的运行时进程。这样就完成了Hello程序的P2P。
020,即Zero-0 to Zero-0。在执行Hello程序时,shell通过fork创建子进程,调用execve加载并运行可执行文件hello。OS和MMU会为进程生成虚拟地址,并将其映射到物理地址上。数据从磁盘传输到CPU中,Cache,TLB和多级页表等加速数据的访问。IO管理与信号处理实现hello的输入和输出。最后回收hello进程,操作系统会将该进程移除,释放相应的虚拟空间。完成Hello程序的020。
1.2 环境与工具
列出你为编写本论文,折腾Hello的整个过程中,使用的软硬件环境,以及开发与调试工具。
CPU:11th Gen Intel(R) Core(TM) i7-1165G7 @ 2.80GHz
RAM:16.0GB
系统:x64Windows11 x64Ubuntu
工具:Codeblocks 64位,VsCode64位,vim objump gdb gcc readelf等工具
1.3 中间结果
hello.c :源程序
hello.i :预处理后的源程序文件
hello.s :编译后得到的汇编程序
hello.o :汇编后得到的可重定位目标文件
hello :可执行目标文件
elf.txt :hello.o的elf文件
hello1.asm :hello.o的反汇编文件
hello.elf :hello的elf文件
hello.asm :hello的反汇编文件
1.4 本章小结
本章介绍了hello程序的P2P和020的整个过程,对hello程序的一生做了总的概括。列出了本次调试的硬件配置,软件环境,开发工具等,同时介绍了调试过程中生成的中间文件的名称及功能。
第2章 预处理
2.1 预处理的概念与作用
2.2.1 预处理的概念
预处理是指预处理器在编译之前,对源文件进行加工的一个过程。预处理阶段主要处理源代码中的预处理指令(以#开头的指令),如文件包含(#include)、宏定义(#define)、条件编译(#ifdef等)等,并根据这些指令对源代码进行相应的修改和替换。
2.2.2 预处理的作用
通过#include指令,预处理器可以将其他文件的内容包含到当前文件中,避免了重复编写相同的代码,提高了代码的可维护性和重用性。通过#define指令,定义一个宏,宏是一个简单的文本替换工具。预处理器使用宏可以避免使用魔法数(magic number),简化复杂或频繁使用的表达式或字符串。通过#ifdef、#ifndef、#if、#else、#elif和#endif等条件编译指令,预处理器可以根据条件选择性地编译源代码的某一部分。这有助于在开发和调试过程中,根据不同的环境或需求编译不同的代码段。预处理也会删除注释等。最后得到.i结尾的文件用于进一步的编译过程。
2.2在Ubuntu下预处理的命令
预处理的命令:gcc hello.c -E -o hello.i
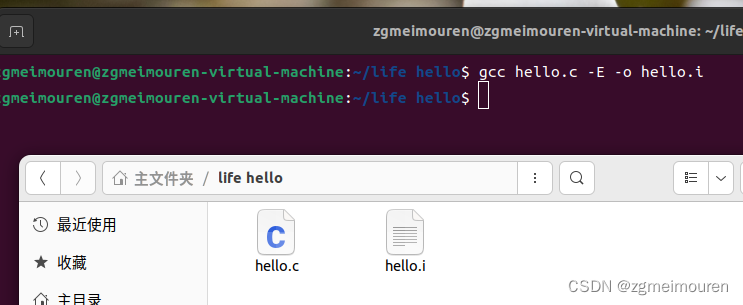
图2.2.1 预处理命令及结果
2.3 Hello的预处理结果解析
通过预处理指令后,生成了hello.i文件,打开hello.i文件,对比hello.c文件。可以看到,预处理对源程序的#include指令的头文件进行展开将代码扩展到了3000行左右。在文件的最后依旧保留着源码。
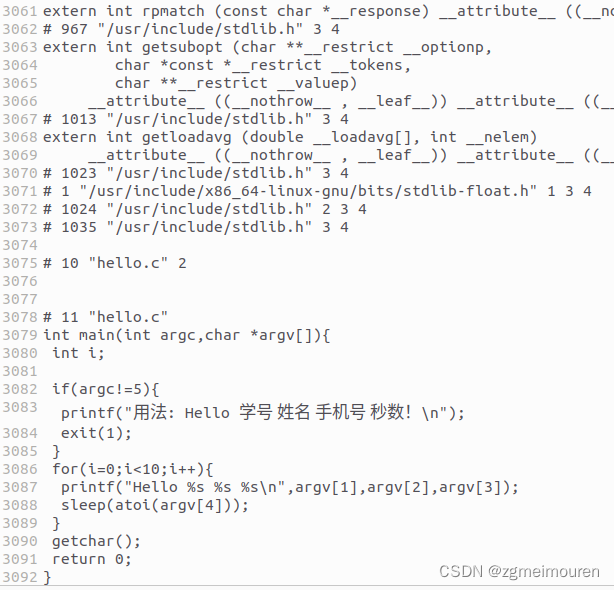
图2.3.1 hello.i中的源码部分
前3000行的代码全部源自#include指令的展开,对于<stdio.h>的头文件,预处理器会从系统路径"/usr/include/stdio.h"中复制该文件的内容到.i文件中,其他头文件类似,因此会将代码拓展到3000行。
2.4 本章小结
本章在Ubuntu中对hello.c进行了预处理,得到了hello.i文件,并且对与处理文件进行了解析。
第3章 编译
3.1 编译的概念与作用
编译是将高级语言编写的程序代码转化为机器可以理解和执行的机器代码的过程。编译器是负责执行这一过程的软件工具。
编译的作用是将高级语言代码转化为机器代码,以便计算机能够直接执行。编译器会对预处理后的代码进行词法分析、语法分析和语义分析,然后生成中间代码或汇编代码。
注意:这儿的编译是指从 .i 到 .s 即预处理后的文件到生成汇编语言程序。
3.2 在Ubuntu下编译的命令
编译命令:gcc hello.i -S -o hello.s

图3.2.1 编译命令及结果
3.3 Hello的编译结果解析
3.3.1数据
源程序的数据会有常量、变量(全局/局部/静态)、表达式、类型等。常量会被转化成立即数直接在机器代码中操作。对于变量,使用时会访问对应的内存地址。对于表达式和类型,编译器会进行分析并优化,优化为适合机器执行的形式的机器代码,以此来执行表达式的计算。
在hello.s中有两个字符串常量。
![]()
![]()
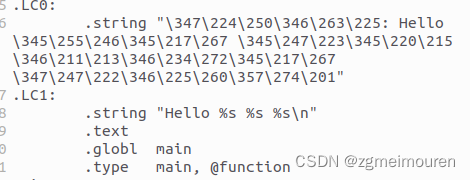
图3. 3.1.1 字符串常量
程序的参数有int型的argc,被存放在寄存器edx中,并入栈到-20(%rbp)的位置,与常量5比较,进行分支。还有第二个参数为数组char* argv,其起始地址存放在寄存器rsi并入栈在-32(%rbp)的位置。
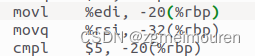
图3. 3.1.3 参数argc及argv
程序的局部变量有i,直接被赋值为0到-4(%rbp)的位置。
![]()
图3. 3.1.4 局部变量i
程序只有一个全局函数变量main。
![]()
图3. 3.1.5 全局函数变量main
3.3.2赋值
程序的赋值操作只有i = 0,使用movl指令将四字节的立即数0直接赋值到i在栈中分配的位置-4(%rbp)。
![]()
图3. 3.2.1 局部变量i赋值为0
3.3.3算术操作
程序中的算术操作体现在i++,通过addl指令直接将立即数1加到i在栈中的位置-4(%rbp)。
![]()
图3. 3.3.1 局部变量i++
3.3.4关系操作及控制转移
程序的关系操作有argc != 5和i < 10两处,对应控制转移的if条件跳转与for循环。
参数argc入栈的位置为-20(%rbp),通过cmp指令和je指令判断5和argc的关系,如果相等跳转到.L3,不相等继续执行。以此实现if的条件跳转的控制转移。
![]()
图3. 3.4.1 if条件跳转
i在栈中的位置是-4(%rbp),i < 10的判断转化为i <= 9的判断,cmp比较9和i,jle判断小于等于,若i小于等于9跳转到.L4的循环体内,否则继续执行。以此实现for循环的控制转移。
![]()
图3. 3.4.2 for循环
3.3.5函数操作
hello程序采用了七个函数main,puts,printf,exit,atoi,sleep,getchar。
main函数的参数有两个int的argc和char*的argv数组,分别通过edi和rsi来传递,main函数中通过call指令调用了其他函数,main只有一个局部变量i存在栈中。
puts函数在main中被call指令调用,通过rdi传递参数,rdi中是第一个字符串常量的初始地址。以此打印出第一个字符串。
![]()
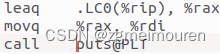
图3. 3.5.1 puts函数的调用
printf函数被call指令调用,通过rdi传递第二个字符串常量的初始地址,通过rsi传递argv[1],rdx传递argv[2],rcx传递argv[3]。
![]()

图3. 3.5.2 printf函数的调用
exit函数通过rdi传递参数常量1,通过call指令被调用。
![]()
图3. 3.5.3 exit函数的调用
atoi函数和sleep函数一起调用,atoi通过rdi传递argv[4],返回值在eax中,返回值转移到edi,进而传递到sleep函数。
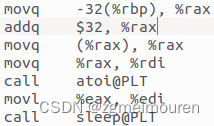
图3. 3.5.4 atoi函数和sleep函数的调用
getchar函数直接使用call指令调用即可。
3.4 本章小结
本章首先介绍了编译的概念与作用,然后在Ubuntu中生成了编译文件hello.s,对编译文件的内容进行了分析,包括数据、赋值、算术操作、关系操作、控制转移以及函数操作。
第4章 汇编
4.1 汇编的概念与作用
汇编是将由编译器产生的汇编语言代码hello.s文件转换成机器语言目标代码hello.o文件的过程。这个过程由汇编器完成。
汇编可以将高级语言转化为机器可直接识别执行的代码文件,汇编器将.s 汇编程序翻译成机器语言指令,把这些指令打包成可重定位目标程序的格式。
4.2 在Ubuntu下汇编的命令
汇编命令:gcc hello.s -c -o hello.o

图4.2.1 汇编命令
4.3 可重定位目标elf格式
通过readelf命令得到hello.o的elf文件。

图4.3.1 elf文件的生成
elf头,该部分描述了elf文件的基本信息,包括文件类型、文件版本、目标平台等信息。
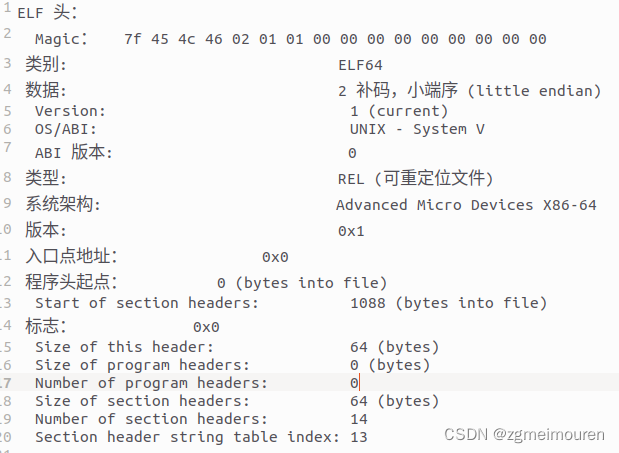
图4.3.2 elf头
elf头之后的是节头表,该部分列出了elf文件中各个节的相关信息,如名称、类型、大小、偏移量、标志等。

图4.3.3 elf节头
节头后是程序头表但本文件没有程序头表。之后就是重定位节,包含了重定位信息,链接后会重新分配地址,用于修正代码和数据在加载过程中的地址。本文件中有.rela.text和.rela.eh_frame重定位节。
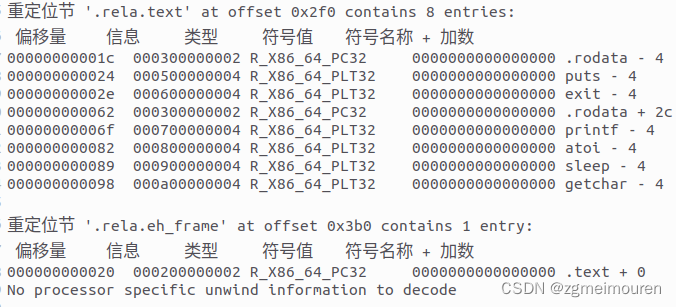
图4.3.4 elf重定位节
重定位节后是符号表(Symbol table),包含了elf文件中定义的符号,例如函数和变量的名称、类型、绑定属性等。其中就有上面分析的六个函数。
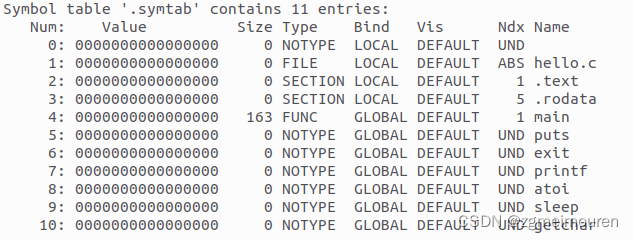
图4.3.5 elf重定位节
4.4 Hello.o的结果解析
通过反汇编指令objdump -d -r hello.o > hello1.asm得到hello.o的反汇编文件hello1.asm。
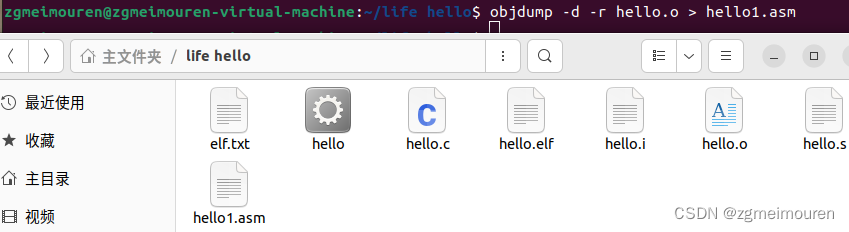
图4.4.1 反汇编指令
增加机器语言:每一条指令增加了一个十六进制的表示,即该指令的机器语言。
![]()
![]()
图4.4.2 机器语言对比
操作数改为十六进制表示:所有的操作数全部由汇编文件的十进制转变为十六进制表示。
![]()
![]()
图4.4.3 操作数对比
跳转改为偏移量表示:所有跳转的位置被表示为<主函数+段内偏移量>这样确定的地址,而不再是段名称.Lx。
![]()
![]()
图4.4.4 跳转对比
函数调用改为重定位函数条目:反汇编文件中对函数的调用与重定位条目相对应。call后面不再是函数名称,而是一条重定位条目指引的信息。
![]()
![]()
图4.4.5 调用对比
4.5 本章小结
本章介绍了汇编的概念和作用,解析了可重定向目标elf的内容,分析了hello.o反汇编的内容,同时与hello.s文件中的对应内容进行了比较分析。
第5章 链接
5.1 链接的概念与作用
链接是将编译后生成的目标文件hello.o与各种库函数以及必要的启动代码等组合在一起,形成一个可以在特定操作系统和硬件平台上运行的可执行文件hello的过程。链接是由叫做链接器的程序自动执行的,它们使得分离编译成为可能。我们不用将一个大型的应用程序组织为一个巨大的源文件,而是可以把它分解为更小、更好管理的模块,可以独立地修改和编译这些模块。当我们改变这些模块中的一个时,只需简单地重新编译它,并重新链接应用。
5.2 在Ubuntu下链接的命令
链接命令:ld -o hello -dynamic-linker /lib64/ld-linux-x86-64.so.2 /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o hello.o /usr/lib/x86_64-linux-gnu/libc.so /usr/lib/x86_64-linux-gnu/crtn.o
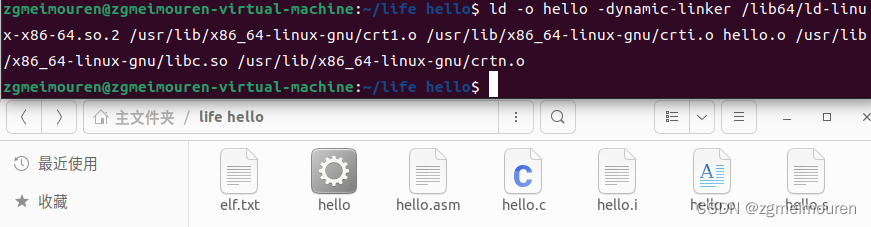
图5.2.1 链接命令
5.3 可执行目标文件hello的格式
elf头描述了elf文件的基本信息,包括文件类型、文件版本、目标平台等信息。与hello.o的elf头基本一致。类型发生改变,程序头大小和节头数量增加,并且获得了入口地址。
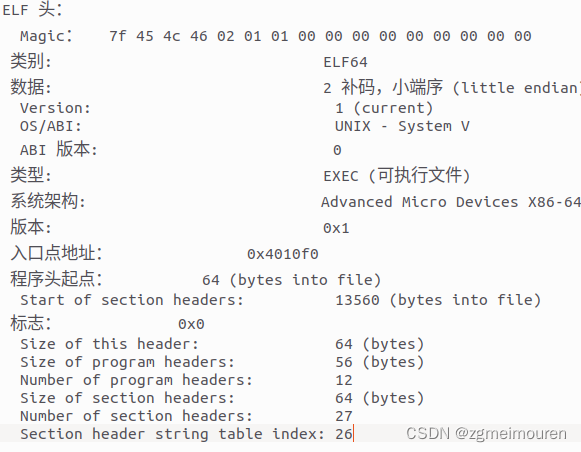
图5.3.1 hello的elf头
之后为节头,描述了各个节的大小、偏移量和其他属性。链接器链接时,会将各个文件的相同段合并成一个大段,并且根据这个大段的大小以及偏移量重新设置各个符号的地址。
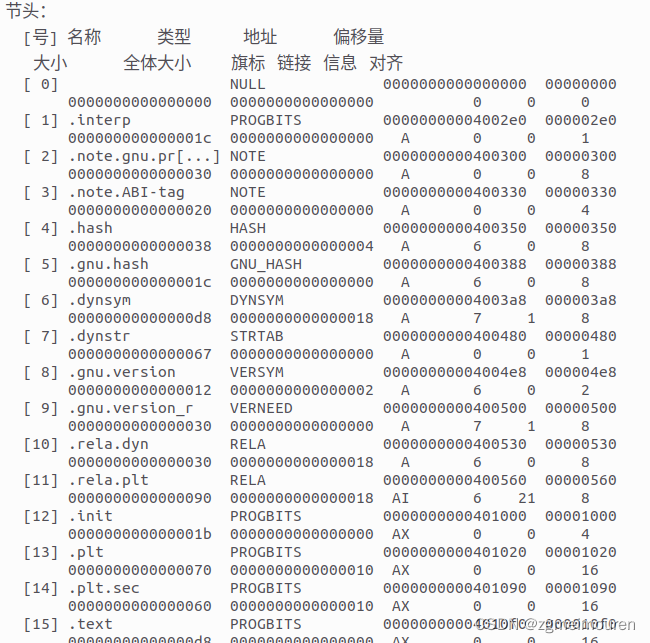
图5.3.2 hello的节头
相比于hello.o的elf文件,hello的elf文件多出了程序头,是一个结构数组,用来描述可执行文件和共享库中各个程序段的信息。

图5.3.3 hello的程序头
之后是动态段,包含了ELF文件中的动态链接信息。动态段用于描述动态链接器(dynamic linker)在加载可执行文件或共享库时所需的一些信息。每个条目包含了一个标记(tag)和相应的值。

图5.3.4 hello的动态段
符号表保存着定位、重定位程序中符号定义和引用的信息,所有重定位需要引用的符号都在其中声明。
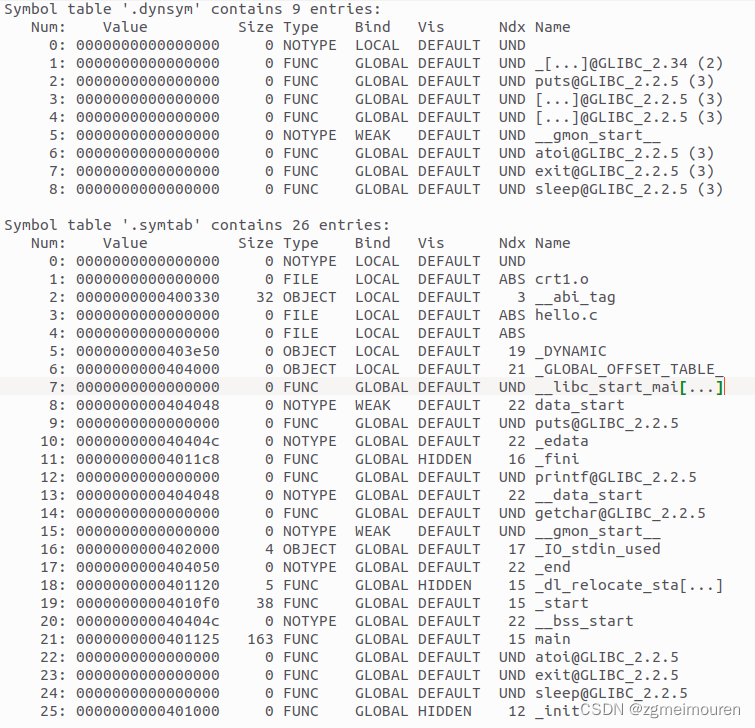
图5.3.4 hello的符号表
5.4 hello的虚拟地址空间
程序从地址0x400000开始到0x401000被载入,虚拟地址从0x4000000x400f0结束,根据5.3中的节头部表,可以通过edb找到各段的信息。
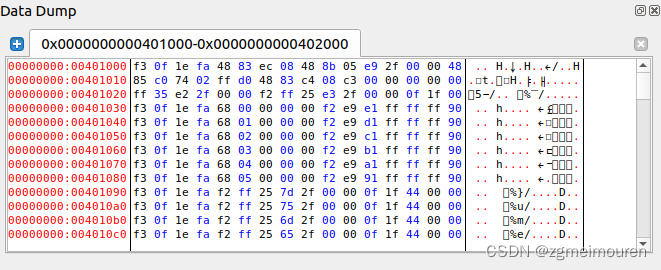
例如.init节,根据图5.3.2的hello的节头可知该段地址从0x401000开始,偏移量为0x1000。与edb查询的虚拟地址空间一致。
5.5 链接的重定位过程分析

图5.5.1 hello的反汇编文件hello.asm
hello的反汇编代码的起始地址从0x401000处开始,是由于链接后分配了地址空间,而hello.o的反汇编代码的地址从0开始。
![]()
![]()
图5.5.2 起始地址改变
hello的反汇编代码通过重定位过程添加许多函数,是由于动态链接器将共享库中hello.c用到的函数加入可执行文件中。而hello.o的反汇编代码只有main函数中的内容。

图5.5.3 动态链接的共享库函数
hello因为已经重定位了,所以在函数调用和调用字符串常量时直接调用已经确定好的具体地址,而hello.o的反汇编代码只涉及了hello.o一个文件,就用0x0代替。
重定位过程分两步,符号解析和地址重定位。
链接器首先对目标文件进行符号解析,它将符号引用解析为符号定义。符号引用是指在一个目标文件中引用的符号,而符号定义是指这个符号在另一个目标文件中的实际定义。链接器会根据符号引用和符号定义之间的关系,建立符号表。
链接器根据符号表中的信息,对目标文件中的地址进行重定位。在符号解析之后,某些地址可能需要修改,以便正确地引用其他目标文件中的符号。链接器会根据需要修改这些地址,使得它们能够正确地指向符号定义所在的内存地址。如果有多个目标文件定义了相同的符号,链接器将对这些符号进行合并,确保最终生成的可执行文件或共享库中只有一个定义。
5.6 hello的执行流程
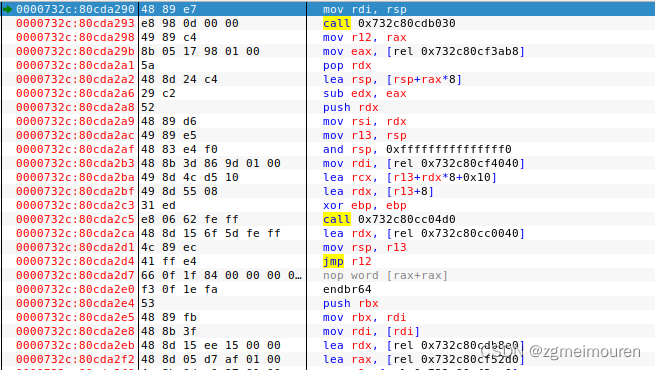
图5.6.1 edb打开hello
加载器负责将可执行目标文件从磁盘加载到内存中,并将控制权转移到程序的入口点。然后,启动函数_libc_start_main负责初始化执行环境,并调用用户层的main函数执行程序的主要逻辑。最后,程序执行完毕后,加载器会返回结果给操作系统进行后续处理。各子程序及地址:0000000000401000 <_init>,0000000000401020 <.plt>,0000000000401090 <puts@plt>,00000000004010a0 <printf@plt>,00000000004010b0 <getchar@plt>,00000000004010c0 <atoi@plt>
00000000004010d0 <exit@plt>,00000000004010e0 <sleep@plt>,00000000004010f0 <_start>,0000000000401125 <main>,0000000000401238 <_fini>。
5.7 Hello的动态链接分析
分析hello程序的动态链接项目,通过edb/gdb调试,分析在动态链接前后,这些项目的内容变化。要截图标识说明。
![]()
图5.7.1 节头中.got.plt的信息
.got.plt函数的位置在00404000。在执行dl_init之前该位置为0。

图5.7.2 执行前该位置内容
执行dl_init之后,指向动态链接器入口。

图5.7.3 执行后该位置内容
5.8 本章小结
本章介绍了链接的概念和作用,并在Ubuntu中生成了可执行目标文件hello,比较了链接前后文件hello和hello.o的elf文件格式区别,并且通过edb调试,分析了重定位后子程序的虚拟地址信息。
第6章 hello进程管理
6.1 进程的概念与作用
进程是指在操作系统中运行的一个正在执行的程序的实例。它是程序执行的动态实体,具有其自己的内存空间、栈、指令指针和其他相关状态。进程是操作系统进行资源分配和调度的基本单位,也是实现并发性和并行性的基础。
操作系统为每个进程分配和管理资源,例如内存、CPU 时间、文件和设备等。进程可以使用操作系统提供的 API 来请求和释放资源,以及进行进程间的通信和同步操作。进程使程序看上去是独占地使用处理器、主存和I/O设备,处理器看上去就好像在不间断地一条接一条地执行程序中的指令,即该程序的代码和数据是系统内存中唯一的对象。
6.2 简述壳Shell-bash的作用与处理流程
Shell是一个交互型应用级程序,也被称为命令解析器,它为用户提供一个操作界面,接受用户输入的命令,并调度相应的应用程序。
Shell首先从终端读入输入的命令,对输入的命令进行解析,如果该命令为内置命令,则立即执行命令,否则调用fork创建一个新的子进程,在该子进程的上下文中执行指定的程序。判断该程序为前台程序还是后台程序,如果为前台程序则等待程序执行结束,若为后台程序则将其放回后台并返回。在过程中shell可以接受从键盘输入的信号并对其进行处理。
6.3 Hello的fork进程创建过程
在Shell中输入./hello命令时,Shell将解析该命令并识别出它是一个可执行文件。然后Shell通过调用加载器来运行该可执行文件。父进程调用fork函数创建一个新的子进程。fork函数会复制父进程的地址空间、文件描述符和其他相关状态,并将其分配给子进程。子进程获得与父进程相同的用户虚拟地址空间的副本,包括代码段、数据段、堆和栈。因此子进程可以运行与父进程相同的代码,并且可以共享相同的数据和变量。子进程还获得与父进程相同的打开文件描述符的副本。因此子进程可以访问和操作与父进程相同的文件。在fork函数返回后,父进程和子进程分别继续执行不同的代码路径。在子进程中,加载器会将新的可执行文件读取到子进程的地址空间中,并开始执行其中的代码。这样,子进程就开始执行 ./hello可执行文件中的程序逻辑。
6.4 Hello的execve过程
父进程调用fork函数创建一个新的子进程。fork函数会复制父进程的地址空间、文件描述符和其他相关状态,并将其分配给子进程。在子进程中,它会调用 execve函数来执行新的可执行文件。execve函数有两个参数:待执行程序的路径和命令行参数。在调用execve函数后,子进程的地址空间、文件描述符等相关状态会被清除,并被新的可执行程序所替换。新的可执行文件被加载到子进程的地址空间中,并开始执行其中的代码。
6.5 Hello的进程执行
结合进程上下文信息、进程时间片,阐述进程调度的过程,用户态与核心态转换等等。
进程上下文信息:
在hello程序中,进程的上下文包括了程序计数器、寄存器、内存映射、打开的文件列表等。当进程被切换时,当前运行进程的上下文信息需要被保存,同时加载要切换的下一个将运行的进程的上下文信息。
进程时间片:
一个进程执行它的控制流的一部分的每一时间段叫做时间片。因此,多任务也叫做时间分片。
进程调度:
在开始执行程序时,操作系统会为该程序创建一个进程,并将其添加到就绪队列中,表示进程已准备好被执行。这个程序中没有明确的调度器,因此可以认为操作系统采用简单的轮转调度算法,按照就绪队列的顺序选择下一个要执行的进程。程序开始执行时,操作系统会将进程的上下文信息加载到CPU中,取出进程的程序计数器值,并开始执行程序代码。在循环中,程序输出hello的字符串,并调用sleep函数进行休眠。在每次循环中,进程会连续运行一个固定时间间隔。当时间间隔耗尽后,进程会被中断,操作系统会保存进程的上下文信息,将CPU分配给下一个就绪态的进程。
用户态与核心态转换:
当程序调用sleep函数时,操作系统会将进程的状态从核心态切换回用户态。这是因为sleep函数只需进行简单的等待,不需要核心态的特权。在sleep函数休眠的期间,进程会被放置在阻塞队列中,等待指定的时间流逝。当指定的休眠时间结束后,操作系统将进程的状态从用户态切换回核心态,以进行下一步的执行。在循环中,程序会再次输出信息并执行休眠操作,如此重复进行,直到循环结束。
6.6 hello的异常与信号处理
回车:
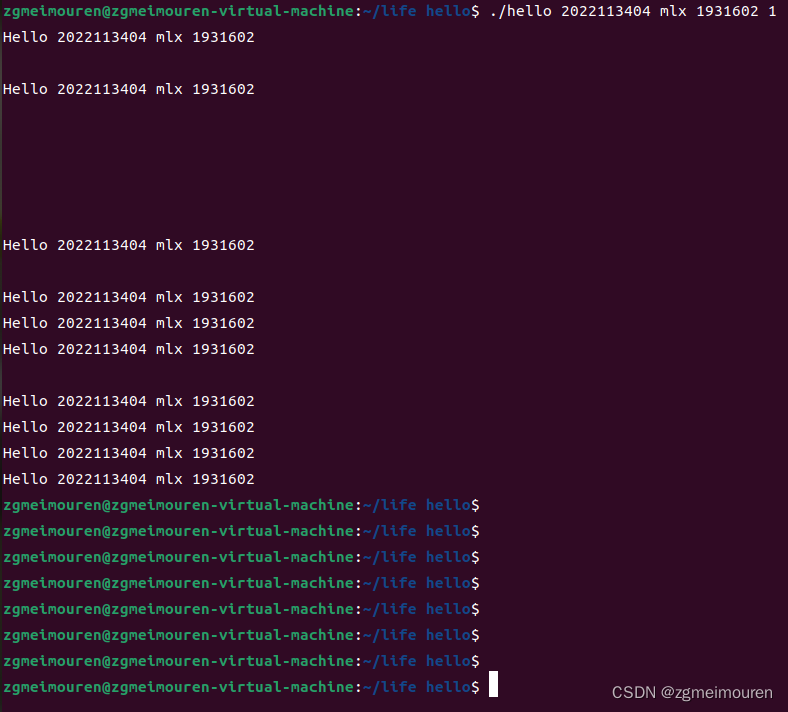
图6.6.1 执行后回车
程序正常执行,但是回车被shell读取,额外的输入内容进入输入缓冲区,在程序结束后被读取。
Ctrl+Z:

图6.6.2 执行后Ctrl+Z
Ctrl + Z,Shell进程收到SIGSTP信号,Shell显示屏幕提示信息并挂起hello进程,程序停止。
Ctrl+C:

图6.6.3 执行后Ctrl+C
Ctrl + C,Shell进程收到SIGINT信号,Shell结束并回收hello进程。
ps,jobs,pstree,fg指令:
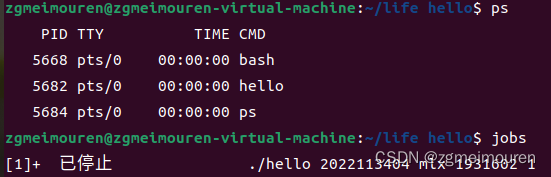
图6.6.4 ps和jobs
ps和jobs指令可以查看进程状态,获取任务列表和任务的状态。
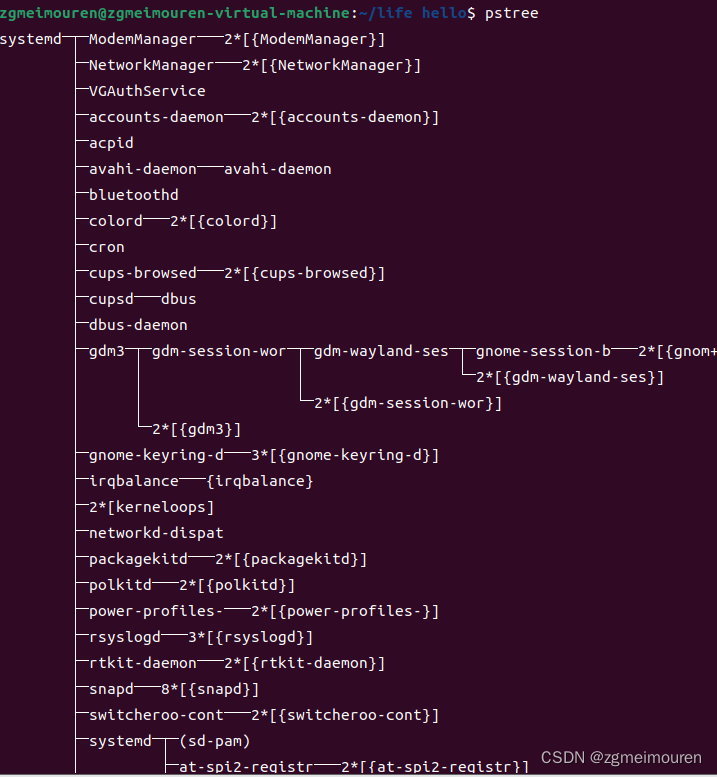
图6.6.5 pstree指令
pstree指令来查看进程树。
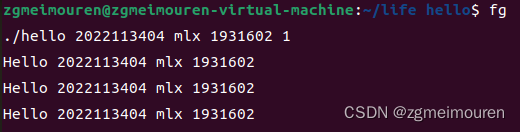
图6.6.6 fg指令
fg指令将后台作业挂到前台。
kill指令:

图6.6.7 kill指令
kill指令杀死停止的hello进程。
6.7本章小结
本章介绍了进程的概念与作用,并且详细分析了hello程序在Shell中创建进程并执行的过程,分析了进程执行中可能出现的各种异常与信号处理。
第7章 hello的存储管理
7.1 hello的存储器地址空间
逻辑地址:
逻辑地址是由一个段标识符加上一个指定段内相对地址的偏移量,由程序hello产生的与段相关的偏移地址部分,argv[1] 和 argv[2] 存储学号和姓名,这是程序中使用的逻辑地址。
虚拟地址:
虚拟地址是由操作系统提供的抽象地址空间,是程序员和程序中使用的地址。在这个程序中,逻辑地址和虚拟地址在这个上下文中可以被认为是相同的,因为程序没有直接涉及到底层的地址映射。
线性地址:
线性地址是虚拟地址空间中的实际地址,它通过分段机制或分页机制映射到物理地址。在现代操作系统中,通常采用分页机制,将线性地址映射到物理地址。
物理地址:
物理地址是计算机系统中实际的硬件地址,指的是RAM(随机访问存储器)中的特定位置。操作系统通过页表等机制将线性地址映射到物理地址,以便程序能够访问实际的物理存储器
7.2 Intel逻辑地址到线性地址的变换-段式管理
段式管理即将程序内容进行分段存储,程序在段寄存器中记录各段的地址,通过段地址加上偏移地址得到线性地址。段式管理通过段表进行,它存储段名、段起点、装入位、段的长度等。当程序引用一个线性地址时,MMU 将该地址分解为页面号和偏移量。使用页面号在页表中查找相应的页表项,该项包含与页面相关联的物理页框号。将物理页框号与偏移量组合,得到最终的物理地址
7.3 Hello的线性地址到物理地址的变换-页式管理
页式内存管理是一种将线性地址映射到物理地址的技术,其中线性地址空间被划分为固定大小的页面,而物理内存也被划分为相同大小的页面。首先将线性地址空间和物理地址空间分割成固定大小的页面。典型的页面大小为4KB。操作系统维护一个页表,用于记录线性地址到物理地址的映射关系。每个页表项对应一个页面。对于较大的地址空间,页表可能会被组织成多级结构,例如页目录和页表。这是为了有效地管理大量的映射关系。
7.4 TLB与四级页表支持下的VA到PA的变换
TLB(Translation Lookaside Buffer,译码后备缓冲器)是一种硬件缓存,用于存储最近的一些虚拟地址到物理地址的映射。它可以加速虚拟地址到物理地址的转换,特别是在使用页式内存管理时。
在四级页表支持下,虚拟地址通常会被划分为四个部分:索引1、索引2、索引3、偏移量。每个索引对应于页表的一个级别,而偏移量对应于页内偏移。当CPU访问一个虚拟地址时,首先会在TLB中查找对应的物理地址。如果TLB中存在相应的映射,就直接使用这个物理地址。如果TLB中未找到相应的映射,就需要在页表中进行查找。四级页表的结构意味着需要经过四次查找过程,分别在每个级别的页表中查找。首先,使用虚拟地址的索引1在一级页表中找到一个指向二级页表的物理地址。然后,使用虚拟地址的索引2在二级页表中找到一个指向三级页表的物理地址。接着,使用虚拟地址的索引3在三级页表中找到一个指向四级页表的物理地址。最后,在四级页表中使用偏移量找到最终的物理地址。在进行上述页表查找的过程中,如果找到了对应的物理地址,将这个映射添加到TLB中,以便未来的访问可以直接从TLB中获取。
7.5 三级Cache支持下的物理内存访问
在一个典型的多级缓存体系结构中,L1缓存是最小且距离CPU核心最近的缓存,L2缓存在L1之上,而L3缓存则通常是共享的,位于多个CPU核心之间。物理内存访问的第一步是将虚拟地址转换为物理地址。这涉及到页表的使用,其中虚拟地址被转化为物理地址,以确定数据存储在物理内存的位置。一旦物理地址确定,系统将首先在L1缓存中查找相应的数据。如果数据在L1缓存中,这就是一个缓存命中(cache hit),数据可以直接从缓存中读取或写入。如果数据在L1缓存中,CPU可以立即访问这些数据,避免了较慢的主存(RAM)访问。这种情况下,访问延迟较低,系统性能较好。如果数据不在L1缓存中(L1缓存未命中),系统将尝试在L2缓存中查找。如果在L2中找到,这被称为L2缓存命中,数据会被复制到L1缓存以供CPU使用。如果数据在L2缓存中也未找到(L2缓存未命中),系统将在L3缓存中查找。L3缓存通常是多个核之间共享的,因此可以被任何一个核使用。如果数据在L3缓存中未找到(L3缓存未命中),系统将从主存(RAM)中读取数据。这通常是最慢的情况,因为主存的访问延迟相对较高。如果数据在缓存中都未找到,系统将从主存中读取或写入数据。这会引起较高的访问延迟,因为主存的速度远远不及缓存。
7.6 hello进程fork时的内存映射
当fork()函数被当前进程调用时,内核为新进程创建各种数据结构,并分配给它一个唯一的PID。为了给这个新进程创建虚拟内存,它创建了当前进程的mm_struct、区域结构和页表的原样副本。它将两个进程中的每个页面都标记为只读,并将两个进程中的每个区域结构都标记为私有的写时复制。
7.7 hello进程execve时的内存映射
加载并执行"hello"程序经历以下步骤:
清理已存在的用户区域:删除当前进程虚拟地址的用户部分中已存在的区域结构,具体而言,删除由mmap指向的vm_area_structs。
映射私有区域:为新程序的代码、数据、bss和栈区域创建新的区域结构。这些新区域都是私有的,采用写时复制机制。代码和数据区域将被映射到"hello"文件的.text和.data区域。bss区域以二进制0初始化,并映射到匿名文件,其大小包括在"hello"中。栈和堆区域也是请求二进制0的,并且初始长度为0。
映射共享区域:如果"hello"程序依赖于共享对象的动态链接,比如C标准库libc.so,那么这些对象将会被动态链接到该程序,然后映射到用户虚拟地址空间的共享区域中。
设置程序计数器:execve的最后一步是设置当前进程上下文中的程序计数器,将其指向代码区域的入口点。这是为了确保在执行新程序时,处理器从正确的位置开始执行指令,即新程序的起始点。
7.8 缺页故障与缺页中断处理
当程序试图访问一个尚未加载到物理内存的页面时,硬件检测到这个问题,并引发缺页故障。这可能是由于该页面在之前被置换到外存,或者是程序第一次访问某个特定的页面。缺页故障触发了缺页中断,导致处理器暂停当前执行的程序,并将控制权交给操作系统内核。操作系统内核收到缺页中断后,会进行一系列的处理步骤,以满足程序对缺失页面的访问请求。操作系统会根据页表信息确定需要调入的页面,并进行页面调度。如果页面在外存中,操作系统会负责将页面加载到物理内存中,并更新页表。在页面加载到物理内存后,操作系统会更新页表,将该页面的映射关系添加到页表中,以便将来的访问可以直接在物理内存中完成。一旦缺页中断处理完成,操作系统会恢复程序的执行,使其重新从触发缺页故障的指令开始执行。
7.9动态存储分配管理
(以下格式自行编排,编辑时删除)
malloc和free:C语言中常用的动态内存管理方法是使用malloc函数分配内存块,并使用free函数释放已分配的内存块。malloc函数可根据指定的大小分配一块指定大小的内存空间,而free函数可以释放已分配的内存空间。
new和delete:C++中引入了new和delete关键字作为动态内存管理的方法。它们与malloc和free类似,但具有更高级别的功能,如调用对象的构造函数和析构函数。
动态内存分配与释放的匹配:每次调用malloc或calloc后,都应该在不再需要该内存块时调用free来释放它,防止内存泄漏。
避免野指针:在释放内存后,将指针设置为NULL,以避免出现野指针问题。
动态数组:使用malloc、calloc和realloc可以实现动态数组,允许在运行时调整数组大小。
内存对齐:一些系统对数据的访问有对齐要求,因此在分配内存时要注意对齐问题。
内存池:对于频繁分配和释放小块内存的情况,可以考虑使用内存池,减少内存碎片和提高性能。
防御性编程:在使用动态内存时,进行防御性编程,检查分配是否成功,避免潜在的错误。
监控和调试:使用工具和技术进行内存泄漏检测和性能分析,以确保程序的稳定性和效率。
7.10本章小结
本章主要介绍了hello的存储器地址空间、intel逻辑地址到线性地址的变换-段式管理、hello的线性地址到物理地址的变换-页式管理、TLB与四级页表支持下的VA到PA的变换、三级Cache支持下的物理内存访问、hello进程fork时的内存映射、hello进程execve时的内存映射、缺页故障与缺页中断处理和动态存储分配管理。
第8章 hello的IO管理
8.1 Linux的IO设备管理方法
在Linux中,IO设备管理主要通过文件系统抽象和设备驱动程序来实现。在Linux中,所有的IO设备(如磁盘、串口、网络接口等)都被抽象为文件,这被称为“一切皆文件”的哲学。通过文件系统接口(如open、read、write、close等函数)来访问和管理IO设备。可以使用标准的文件I/O操作,如读写、复制、重命名等,来对IO设备进行管理和控制。每个IO设备在Linux中都有一个对应的设备文件,它们位于/dev目录下。设备文件提供了用户与底层设备驱动程序之间的接口,用于对设备进行访问和控制。用户可以通过打开设备文件并使用文件I/O操作来读取/写入数据,控制设备的行为。
设备驱动程序位于内核空间,负责管理和控制硬件设备。设备驱动程序与硬件设备交互,将用户空间的IO请求传递给设备,并将设备数据传递给用户。根据设备的特性,可以使用不同的设备驱动程序,如块设备驱动程序(磁盘)、字符设备驱动程序(终端)、网络设备驱动程序等。
8.2 简述Unix IO接口及其函数
Unix I/O(输入/输出)接口是Unix/Linux操作系统提供的一组函数和机制,用于处理文件和设备的输入和输出操作。这些函数通常被称为"Unix I/O函数"或"标准I/O函数"。以下是一些常见的Unix I/O函数:
open函数:
用于打开一个文件,并返回一个文件描述符,该描述符是对文件的引用。
语法:int open(const char *path, int flags, mode_t mode);
read函数:
用于从文件描述符读取数据。
语法:ssize_t read(int fd, void *buf, size_t count);
write函数:
用于向文件描述符写入数据。
语法:ssize_t write(int fd, const void *buf, size_t count);
close函数:
用于关闭文件描述符。
语法:int close(int fd);
lseek函数:
用于在文件中移动文件描述符的读/写位置。
语法:off_t lseek(int fd, off_t offset, int whence);
fcntl函数:
提供对文件描述符的各种控制操作,如设置文件描述符标志。
语法:int fcntl(int fd, int cmd, ... /* arg */ );
dup和dup2函数:
dup复制一个文件描述符,返回一个新的文件描述符,指向相同的文件。
dup2允许将一个文件描述符复制到另一个指定的文件描述符。
语法:int dup(int oldfd);,int dup2(int oldfd, int newfd);
pipe函数:
用于创建一个管道,返回两个文件描述符,分别用于读和写。
语法:int pipe(int pipefd[2]);
select、poll和epoll函数:
用于多路复用,允许监视多个文件描述符的I/O状态。
select是传统的方式,poll是改进的方式,epoll是Linux特有的方式。
ioctl函数:
提供对设备的控制操作。
语法:int ioctl(int fd, unsigned long request, ...);
8.3 printf的实现分析

图8.3.1 printf函数
调用printf时,它首先会将格式化的字符串和参数转换为一个字符数组,通过vsprintf函数来完成。vsprintf函数根据格式化字符串,将数据格式化为特定的文本输出。这个输出被存储在内存中的一个缓冲区中。
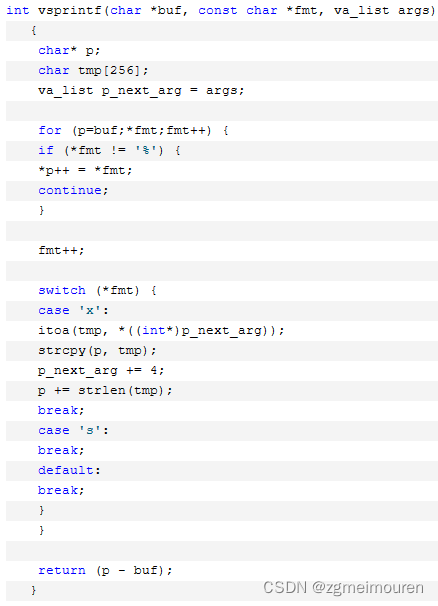
图8.3.2 vsprintf函数
接下来,当printf输出准备好后,它会调用write系统函数来将这些数据发送到标准输出设备(通常是文件描述符1,对应于控制台)。write函数是一个系统调用,它会将数据从应用程序的缓冲区写入到内核中对应文件描述符所关联的文件或设备中。
在底层,操作系统内核包含有关系统调用的代码。在Linux中,这个过程可能涉及到int 0x80中断(在较早的32位系统中)或更现代的syscall指令(在x86_64系统中)。这些都是触发用户空间和内核空间之间切换的机制,允许用户程序请求操作系统执行特权指令。
在字符显示驱动程序中,对于每个字符,首先需要将ASCII码映射到字模库中对应的字模。字模库是一种数据结构,存储了每个字符对应的像素点信息或字形信息。每个字符都对应于一个字模,它描述了字符的外观和排列。
这些字符图形最终被渲染到显示的虚拟显存(VRAM)中。VRAM是一个显存区域,保存着屏幕上每个像素的颜色信息,每个像素对应于屏幕上的一个点。
显示芯片按照刷新频率逐行读取VRAM中的数据,并通过信号线(例如,HDMI、DisplayPort等接口)将每个像素的RGB(红、绿、蓝)颜色信息传输到液晶显示器。这些颜色信息最终被转换为屏幕上的点,形成最终的图像。这个过程在显示器内部的控制电路中完成,使用这些RGB信息来控制每个像素的颜色,从而在屏幕上显示出相应的图像或文本。
8.4 getchar的实现分析

图8.4.1 getchar函数
当用户按下键盘上的键时,硬件触发一个键盘中断。这会导致 CPU 切换到操作系统内核的相应中断处理程序。在这里,处理程序负责获取按键扫描码并将其转换成 ASCII 码。键盘扫描码是硬件发送到计算机的一组值,表示按下或释放的键。中断处理程序会读取这些扫描码。扫描码转换成 ASCII 码的过程通常涉及到键盘映射表,该表将扫描码映射到对应的字符。获取到 ASCII 码后,将其保存到系统的键盘缓冲区。键盘缓冲区是一个数据结构,保存了用户按键的相关信息。当用户在程序中调用 getchar 时,getchar 实际上会调用 read 系统调用来从标准输入读取一个字符。read 等待用户输入,如果缓冲区为空,则它会阻塞,直到有数据可读为止。一旦键盘中断处理程序将按键的 ASCII 码存储到键盘缓冲区,read 就能够从缓冲区中读取一个字符并返回。getchar 或类似的函数通常会继续调用 read 直到接收到回车键(Enter 键)。
8.5本章小结
本章介绍了 Linux 的 I/O 设备的基本概念和管理方法,以及Unix I/O 接口及其函数。最后分析了printf 函数和 getchar 函数的工作过程。
结论
我们使用编程软件用高级语言编写完成hello.c文件,hello.c经过预处理生成hello.i,hello.i被编译生成hello.s。hello.s经过汇编生成hello.o,可重定位目标文件hello.o再经过链接的过程,将其与其他依赖的目标文件和库文件结合,生成最终的可执行目标文件hello。
当运行hello程序时,操作系统首先会创建一个新的进程,系统调用fork函数。这个新进程是父进程的副本,但在不同的虚拟地址空间中执行。在新进程中,execve系统调用函数加载了hello程序的可执行代码和相关的数据,从而取代了原有的进程映像。在这个整个过程中,进程管理发挥了关键作用。fork函数系统调用创建了一个新的进程,使得程序的执行能够并行进行。而execve系统调用则加载了新的程序映像,实现了程序的替换,使得新的可执行程序能够在独立的执行环境中运行。
另一方面,计算机内部的地址管理也至关重要。不同的编译、汇编和链接阶段都涉及到地址的分配和重定位,确保各个模块正确地连接在一起。可执行程序的加载过程中,地址映射和重定位确保程序在内存中以正确的顺序执行。
此外,系统的输入/输出(I/O)在整个过程中也发挥了关键作用。预处理阶段可能会包含文件的读取和宏的替换。编译和链接阶段涉及到读取和写入目标文件。而在程序运行时,I/O负责处理标准输入和标准输出,使得程序能够与用户进行交互。
最终,当hello程序执行完毕后,父进程会负责回收子进程的资源,包括释放内存等,结束整个程序的生命周期。
千里之行始于足下。最简单的最入门的hello程序背后蕴含着百年来计算机发展的精华,麻雀虽小五脏俱全,hello程序的一生帮助我对计算机的各个方面有了全面的认识,尤其是程序执行时的软硬件结合。还有P2P和020的整个流程是现代计算机所有程序执行的基础,让我从hello程序入手了解到计算机系统的基础所在。
附件
hello.c :源程序
hello.i :预处理后的源程序文件
hello.s :编译后得到的汇编程序
hello.o :汇编后得到的可重定位目标文件
hello :可执行目标文件
elf.txt :hello.o的elf文件
hello1.asm :hello.o的反汇编文件
hello.elf :hello的elf文件
hello.asm :hello的反汇编文件
参考文献
[1] https://blog.csdn.net/weixin_42581177/article/details/127575249?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171828878116800227453701%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171828878116800227453701&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-127575249-null-null.142^v100^control&utm_term=%E8%BF%9B%E7%A8%8B&spm=1018.2226.3001.4187
[2] https://www.cnblogs.com/pianist/p/3315801.html
[3] https://blog.csdn.net/qq_62464995/article/details/129844907?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171828895816800185879113%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171828895816800185879113&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-2-129844907-null-null.142^v100^control&utm_term=%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86&spm=1018.2226.3001.4187
[4] https://blog.csdn.net/chichoxian/article/details/53486131?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171828898616800186583119%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171828898616800186583119&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-53486131-null-null.142^v100^control&utm_term=execve&spm=1018.2226.3001.4187















 616
616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









