







业务场景
由于业务需要导出如下图中订单数据和订单项信息,而一个订单对应多个订单项,所以会涉及到自定义合并行
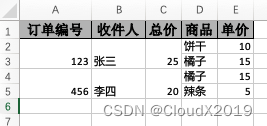
1.简单处理
项目使用的EasyExcel,经查找发现Excel种有个AbstractMergeStrategy抽象类,可以用于合并单元格。
于是先简单的写一个工具类实现根据数据自定义合并单元行,基本思路是获取当前单元格内容和上一行的单元格内容比对,如果相同则添加合并区域,如果不同则不处理,如果上一个单元格在合并区域中,则先移除合并区域再将当前单元格添加到合并区域中。
public class RowMergeStrategy extends AbstractMergeStrategy {
@Override
protected void merge(final Sheet sheet, final Cell cell, final Head head, final Integer relativeRowIndex) {
//判断是否为需要合并的列
if (...) {
mergeWithPrevRow(sheet, cell, cell.getRowIndex(), cell.getColumnIndex());
}
}
/**
* 合并行
*
* @param sheet 当前sheet
* @param cell 用于比对的合并单元格(可以指定根据其他列的单元格合并,也可以根据当前单元格和上一个单元格数据自动合并)
* @param curRowIndex 当前单元格行索引
* @param curColIndex 当前单元格列索引
*/
private void mergeWithPrevRow(Sheet sheet, Cell cell, int curRowIndex, int curColIndex) {
//获取当前行的当前列的数据和上一行的当前列列数据,通过上一行数据是否相同进行合并
int preRowIndex = curRowIndex - 1;
Row preRow = cell.getSheet().getRow(preRowIndex);
Cell preCell = preRow.getCell(cell.getColumnIndex());
// 1 比较当前行的 单元格 与上一行的单元格是否相同
if (Objects.equals(getCellData(cell), getCellData(preCell))) {
List<CellRangeAddress> mergeRegions = sheet.getMergedRegions();
// 2 查看上一行的单元格是否在合并区域中
Optional<CellRangeAddress> optional = mergeRegions.stream()
.filter(c -> c.isInRange(preRowIndex, curColIndex)).findFirst();
CellRangeAddress address;
if (optional.isPresent()) {
//3.1 如果单元格在合并区域中,则先删除原合并区域,再将合并区域下拉一行
address = optional.get();
sheet.removeMergedRegion(mergeRegions.indexOf(address));
address.setLastRow(curRowIndex);
} else {
//3.2 如果单元格不在合并区域中,则将当前单元格和上一单元格组成合并区域
address = new CellRangeAddress(preRowIndex, curRowIndex, curColIndex, curColIndex);
}
// 4 将合并区域区域加入sheet中
sheet.addMergedRegion(address);
}
}
}
2.优化数据显示
第一个版本上线后财务反馈数据有问题。如图,求和数值实际应该是45,但是显示为90,导致财务不好对账
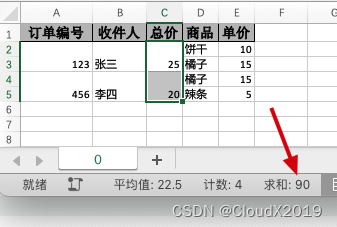
经排查发现图中C3、C5单元格虽然已经合并了,但是数据仍然存在,导致下拉选中的时候将他们的值也计算进去了。于是在1.0的基础上调整,将合并单元格仅保留首行数据,其他行内容直接清空
/**
* 合并行
*
* @param sheet 当前sheet
* @param cell 用于比对的合并单元格(可以指定根据其他列的单元格合并,也可以根据当前单元格和上一个单元格数据自动合并)
* @param curRowIndex 当前单元格行索引
* @param curColIndex 当前单元格列索引
*/
private void mergeWithPrevRow(Sheet sheet, Cell cell, int curRowIndex, int curColIndex) {
//获取当前行的当前列的数据和上一行的当前列列数据,通过上一行数据是否相同进行合并
int preRowIndex = curRowIndex - 1;
List<CellRangeAddress> mergeRegions = cell.getSheet().getMergedRegions();
//1 查询当前单元格上一行的单元格是否为合并单元格
Optional<CellRangeAddress> optional = mergeRegions.stream()
.filter(c -> c.isInRange(preRowIndex, curColIndex)).findFirst();
CellRangeAddress address;
if (optional.isPresent()) {
//2.1 上一行是合并单元格,则取合并单元格第一行的数据比对
address = optional.get();
Row firstRow = sheet.getRow(address.getFirstRow());
Cell firstCell = firstRow.getCell(cell.getColumnIndex());
if (Objects.equals(getCellData(cell), getCellData(firstCell))) {
sheet.removeMergedRegion(mergeRegions.indexOf(address));
address.setLastRow(curRowIndex);
sheet.addMergedRegion(address);
//匹配成功清空当前单元格
cell.setBlank();
}
} else {
//2.2 上一行不是合并单元格,则取上一行单元格数据比对
Row preRow = sheet.getRow(preRowIndex);
Cell preCell = preRow.getCell(cell.getColumnIndex());
if (Objects.equals(getCellData(cell), getCellData(preCell))) {
address = new CellRangeAddress(preRowIndex, curRowIndex, curColIndex, curColIndex);
sheet.addMergedRegion(address);
//匹配成功清空当前单元格
cell.setBlank();
}
}
}
3.优化合并策略
第二版上线后数据问题已经解决,但是财务反馈导出大量数据时太慢。本来打算调整为异步导出解决此问题,但是经过测试发现10000条数据如果不合并直接生成excel只要几秒,但是使用合并自定义合并策略就非常慢,需要一二十分钟,这个时间差大的太离谱了,于是查看合并策略代码有哪些地方可以优化的。
经过查看代码可以发现在上述2.1步骤中一直查找合并单元格数据,然后一直删除再新增。假设10000条数据,有3列需要自动合并,每三行合并,执行以上代码会执行6666✖️3次新增和3333✖️3次删除,大大的影响了效率。于是调整代码,处理数据时只保存需要合并的单元格信息,导出完成再统一添加合并信息到sheet
//此处需要实现WorkbookWriteHandler,保证文件写完后再添加合并区域到sheet
public class RowMergeStrategy extends AbstractMergeStrategy implements WorkbookWriteHandler
/**
* 文件写完后写入合并区域信息
* @param context
*/
@Override
public void afterWorkbookDispose(final WorkbookWriteHandlerContext context) {
//当前表格写完后,统一写入
Map<Integer, List<CellRangeAddress>> rangeMap = ExcelThreadContext.getMap(RANGE_CONTEXT_KEY);
if (CollUtil.isNotEmpty(rangeMap)) {
rangeMap.values().stream().flatMap(list -> list.stream().filter(CollUtil::isNotEmpty))
.forEach(address -> context.getWriteContext().writeSheetHolder().getSheet().addMergedRegion(address));
}
//清除线程中的数据
ExcelThreadContext.clear();
}
private void mergeWithPrevCell(Sheet sheet, Cell cell, int curRowIndex, int curColIndex) {
//ExcelThreadContext 就是一个ThreadLocal,用于缓存当前表格数据
//用于存储每列的最后一个合并区域的首行单元格 key:列序号 value:最后一个合并区域首行单元格
Map<Integer, Cell> cellMap = ExcelThreadContext.getMap(CONTEXT_KEY);
//用于存储每列的所有合并单元格信息 key:列序号 value:合并单元格列表
Map<Integer, List<CellRangeAddress>> rangeMap = ExcelThreadContext.getMap(RANGE_CONTEXT_KEY);
int preRowIndex = curRowIndex - 1;
//1 获取该列最后一个合并区域
List<CellRangeAddress> addressList = rangeMap.get(curColIndex);
CellRangeAddress address = this.getLastRangeAddress(addressList);
//2.1 上一行在合并区域内,则取合并区域第一行的数据比对
if (Objects.nonNull(address) && address.isInRange(preRowIndex, curColIndex)) {
Cell firstCell = cellMap.get(curColIndex);
if (Objects.equals(getCellData(cell), getCellData(firstCell))) {
//3.1 修改合并区域,将当前单元格加入合并区域
address.setLastRow(curRowIndex);
cell.setBlank();
}
} else {
//2.2 上一行不在合并区域内 比较当前单元格 与上一行是否内容相同
Row preRow = sheet.getRow(preRowIndex);
Cell preCell = preRow.getCell(cell.getColumnIndex());
if (Objects.equals(getCellData(cell), getCellData(preCell))) {
//3.2 添加合并区域,将当前单元格和上一行合并,并将当前合并区域放入线程
address = new CellRangeAddress(preRowIndex, curRowIndex, curColIndex, curColIndex);
rangeMap.put(curColIndex, this.addRangeAddress(addressList, address));
//将上一行单元格放入线程
cellMap.put(curColIndex, preCell);
cell.setBlank();
}
}
ExcelThreadContext.setData(CONTEXT_KEY, cellMap);
ExcelThreadContext.setData(RANGE_CONTEXT_KEY, rangeMap);
}
private List<CellRangeAddress> addRangeAddress(final List<CellRangeAddress> list, final CellRangeAddress address) {
List<CellRangeAddress> addressList = list;
if (CollUtil.isEmpty(addressList)) {
addressList = new ArrayList<>();
}
addressList.add(address);
return addressList;
}
private CellRangeAddress getLastRangeAddress(List<CellRangeAddress> list) {
if (CollUtil.isEmpty(list)) {
return null;
}
return list.get(list.size() - 1);
}
经过测试,原本生成文件需要20分钟左右,现优化到只需要20多秒了。
工具类
/**
* excel线程上下文.
*
*/
public class ExcelThreadContext {
private static final ThreadLocal<Map<String, Object>> THREAD_LOCAL = ThreadLocal.withInitial(HashMap::new);
public static void clear() {
THREAD_LOCAL.remove();
}
public static void setData(String key, Object value) {
Map<String, Object> map = get();
map.put(key, value);
}
public static Integer getInteger(String key) {
return getInteger(key, 1);
}
public static Integer getInteger(String key, Integer defaultValue) {
Map<String, Object> map = get();
return Convert.toInt(map.get(key), defaultValue);
}
public static <K, V> Map<K, V> getMap(String key) {
return getMap(key, new HashMap<>());
}
public static <K, V> Map<K, V> getMap(String key, Map<K, V> defaultValue) {
Map<String, Object> map = get();
try {
return (Map<K, V>) map.getOrDefault(key, defaultValue);
} catch (Exception e) {
return defaultValue;
}
}
public static <T> T getObject(String key) {
return getObject(key, null);
}
public static <T> T getObject(String key, T defaultValue) {
Map<String, Object> map = get();
try {
return (T) map.getOrDefault(key, defaultValue);
} catch (Exception e) {
return defaultValue;
}
}
private static void set(Map<String, Object> map) {
THREAD_LOCAL.set(map);
}
public static Map<String, Object> get() {
return THREAD_LOCAL.get();
}
}
因为数据是存储在线程中的,需要每次使用后清理线程数据
/**
* 清理线程数据.
*
*/
public class ClearExcelThreadHandler implements WorkbookWriteHandler {
@Override
public void afterWorkbookDispose(final WriteWorkbookHolder writeWorkbookHolder) {
ExcelThreadContext.clear();
}
/**
* 数据越小越靠前,默认值为0
* 此处排在最后,防止其他业务没处理完就将线程数据清理掉了
* @return
*/
@Override
public int order() {
return Integer.MAX_VALUE;
}
}
...
//使用方法
EasyExcel.write(file, clazz)
.registerWriteHandler(new ClearExcelThreadHandler())
.sheet()
.doWrite(dataList);















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









