







Python安装后的edge-tts 库可以使用微软 Edge 浏览器的语音合成功能将文本转换成语音。edge-tts是微软神经网络语音朗读服务,只是它剃除了朗读标签和一些功能,用户无法享用完整版优质的语音朗读服务。好在于它的语音朗读质量优越, 连IVONA也跟不上。剃除了朗读标签后,你会很快发现,它只会调用固定的单个语音库来朗读整篇文章,如果想要朗读包涵角色的对话的文本,这可害苦了想使用免费版的用户,偏偏在外语教学与学习辅助中,听对话朗读又是一个重要的学习途径,设计与编写一个可以处理包涵角色朗读的小工具是必要的。(注:微软edge-tts库经常升级,端口也会随着发生改变,若不及时升级会发生不能合成声音的错误警报。相关应用程序可以下面链接下载。20241029)
设计界面:(有点丑)
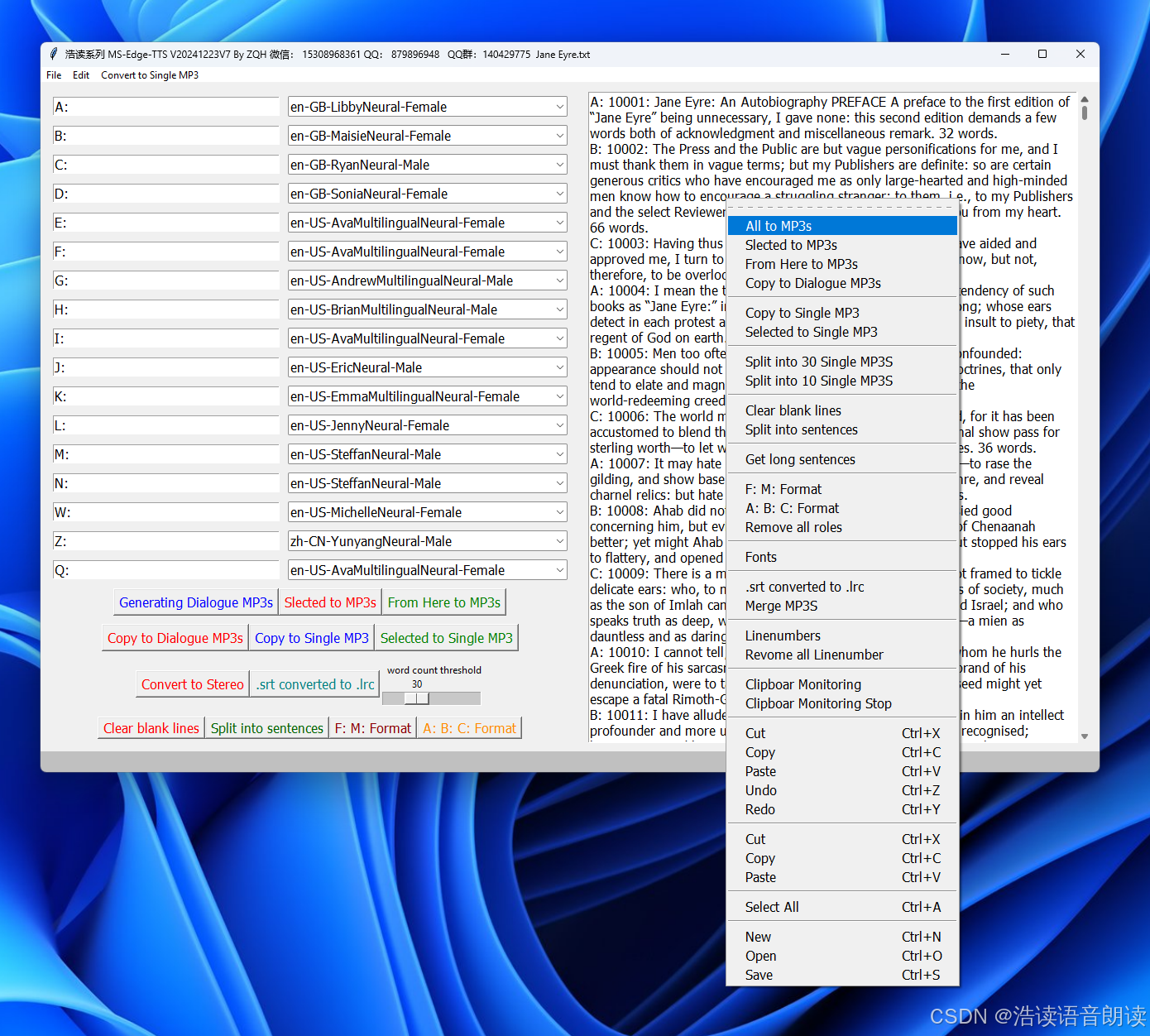
功能:
以上是用python设计编写的,它可以
1. 同时处理16角色的文本,按段成MP3及歌词,
2. 生成的MP3转成立体声音,高大音量,
3. 内置edge-tts全部的语音库任意选择
4. 角色与语音库选择后动态保存
5.支持简单文本编辑,支持普通文本转MP3和歌词
相关关键代码:
# 创建角色文本框和语音库ComboBox
role_entries = []
voice_lib_comboboxes = []
for i in range(17):
frame = tk.Frame()
frame.pack(pady=5)
# 创建角色文本框
role_entry = tk.Entry(frame, width=20)
role_entry.pack(side=tk.LEFT, padx=5)
role_entries.append(role_entry)
role_entry.bind("<KeyRelease>", on_role_change) # 角色文本框变化时自动保存
# 创建语音库ComboBox
voice_lib_combobox = ttk.Combobox(frame, values=["af-ZA-AdriNeural-Female",
"af-ZA-WillemNeural-Male",
"am-ET-AmehaNeural-Male",
"am-ET-MekdesNeural-Female",
"ar-AE-FatimaNeural-Female",
"ar-AE-HamdanNeural-Male",
"ar-BH-AliNeural-Male",
"ar-BH-LailaNeural-Female",
"ar-DZ-AminaNeural-Female",
"ar-DZ-IsmaelNeural-Male",
"ar-EG-SalmaNeural-Female",
"ar-EG-ShakirNeural-Male",
"ar-IQ-BasselNeural-Male",
"ar-IQ-RanaNeural-Female",
"ar-JO-SanaNeural-Female",
"ar-JO-TaimNeural-Male",
"ar-KW-FahedNeural-Male",
"ar-KW-NouraNeural-Female",
"ar-LB-LaylaNeural-Female",
"ar-LB-RamiNeural-Male",
"ar-LY-ImanNeural-Female",
"ar-LY-OmarNeural-Male",
"ar-MA-JamalNeural-Male",
"ar-MA-MounaNeural-Female",
"ar-OM-AbdullahNeural-Male",
"ar-OM-AyshaNeural-Female",
"ar-QA-AmalNeural-Female",
"ar-QA-MoazNeural-Male",
"ar-SA-HamedNeural-Male",
"ar-SA-ZariyahNeural-Female",
"ar-SY-AmanyNeural-Female",
"ar-SY-LaithNeural-Male",
"ar-TN-HediNeural-Male",
"ar-TN-ReemNeural-Female",
"ar-YE-MaryamNeural-Female",
"ar-YE-SalehNeural-Male",
"az-AZ-BabekNeural-Male",
"az-AZ-BanuNeural-Female",
"bg-BG-BorislavNeural-Male",
"bg-BG-KalinaNeural-Female",
"bn-BD-NabanitaNeural-Female",
"bn-BD-PradeepNeural-Male",
"bn-IN-BashkarNeural-Male",
"bn-IN-TanishaaNeural-Female",
"bs-BA-GoranNeural-Male",
"bs-BA-VesnaNeural-Female",
"ca-ES-EnricNeural-Male",
"ca-ES-JoanaNeural-Female",
"cs-CZ-AntoninNeural-Male",
"cs-CZ-VlastaNeural-Female",
"cy-GB-AledNeural-Male",
"cy-GB-NiaNeural-Female",
"da-DK-ChristelNeural-Female",
"da-DK-JeppeNeural-Male",
"de-AT-IngridNeural-Female",
"de-AT-JonasNeural-Male",
"de-CH-JanNeural-Male",
"de-CH-LeniNeural-Female",
"de-DE-AmalaNeural-Female",
"de-DE-ConradNeural-Male",
"de-DE-FlorianMultilingualNeural-Male",
"de-DE-KatjaNeural-Female",
"de-DE-KillianNeural-Male",
"de-DE-SeraphinaMultilingualNeural-Female",
"el-GR-AthinaNeural-Female",
"el-GR-NestorasNeural-Male",
"en-AU-NatashaNeural-Female",
"en-AU-WilliamNeural-Male",
"en-CA-ClaraNeural-Female",
"en-CA-LiamNeural-Male",
"en-GB-LibbyNeural-Female",
"en-GB-MaisieNeural-Female",
"en-GB-RyanNeural-Male",
"en-GB-SoniaNeural-Female",
"en-GB-ThomasNeural-Male",
"en-HK-SamNeural-Male",
"en-HK-YanNeural-Female",
"en-IE-ConnorNeural-Male",
"en-IE-EmilyNeural-Female",
"en-IN-NeerjaExpressiveNeural-Female",
"en-IN-NeerjaNeural-Female",
"en-IN-PrabhatNeural-Male",
"en-KE-AsiliaNeural-Female",
"en-KE-ChilembaNeural-Male",
"en-NG-AbeoNeural-Male",
"en-NG-EzinneNeural-Female",
"en-NZ-MitchellNeural-Male",
"en-NZ-MollyNeural-Female",
"en-PH-JamesNeural-Male",
"en-PH-RosaNeural-Female",
"en-SG-LunaNeural-Female",
"en-SG-WayneNeural-Male",
"en-TZ-ElimuNeural-Male",
"en-TZ-ImaniNeural-Female",
"en-US-AnaNeural-Female",
"en-US-AndrewMultilingualNeural-Male",
"en-US-AndrewNeural-Male",
"en-US-AriaNeural-Female",
"en-US-AvaMultilingualNeural-Female",
"en-US-AvaNeural-Female",
"en-US-BrianMultilingualNeural-Male",
"en-US-BrianNeural-Male",
"en-US-ChristopherNeural-Male",
"en-US-EmmaMultilingualNeural-Female",
"en-US-EmmaNeural-Female",
"en-US-EricNeural-Male",
"en-US-GuyNeural-Male",
"en-US-JennyNeural-Female",
"en-US-MichelleNeural-Female",
"en-US-RogerNeural-Male",
"en-US-SteffanNeural-Male",
"en-ZA-LeahNeural-Female",
"en-ZA-LukeNeural-Male",
"es-AR-ElenaNeural-Female",
"es-AR-TomasNeural-Male",
"es-BO-MarceloNeural-Male",
"es-BO-SofiaNeural-Female",
"es-CL-CatalinaNeural-Female",
"es-CL-LorenzoNeural-Male",
"es-CO-GonzaloNeural-Male",
"es-CO-SalomeNeural-Female",
"es-CR-JuanNeural-Male",
"es-CR-MariaNeural-Female",
"es-CU-BelkysNeural-Female",
"es-CU-ManuelNeural-Male",
"es-DO-EmilioNeural-Male",
"es-DO-RamonaNeural-Female",
"es-EC-AndreaNeural-Female",
"es-EC-LuisNeural-Male",
"es-ES-AlvaroNeural-Male",
"es-ES-ElviraNeural-Female",
"es-ES-XimenaNeural-Female",
"es-GQ-JavierNeural-Male",
"es-GQ-TeresaNeural-Female",
"es-GT-AndresNeural-Male",
"es-GT-MartaNeural-Female",
"es-HN-CarlosNeural-Male",
"es-HN-KarlaNeural-Female",
"es-MX-DaliaNeural-Female",
"es-MX-JorgeNeural-Male",
"es-NI-FedericoNeural-Male",
"es-NI-YolandaNeural-Female",
"es-PA-MargaritaNeural-Female",
"es-PA-RobertoNeural-Male",
"es-PE-AlexNeural-Male",
"es-PE-CamilaNeural-Female",
"es-PR-KarinaNeural-Female",
"es-PR-VictorNeural-Male",
"es-PY-MarioNeural-Male",
"es-PY-TaniaNeural-Female",
"es-SV-LorenaNeural-Female",
"es-SV-RodrigoNeural-Male",
"es-US-AlonsoNeural-Male",
"es-US-PalomaNeural-Female",
"es-UY-MateoNeural-Male",
"es-UY-ValentinaNeural-Female",
"es-VE-PaolaNeural-Female",
"es-VE-SebastianNeural-Male",
"et-EE-AnuNeural-Female",
"et-EE-KertNeural-Male",
"fa-IR-DilaraNeural-Female",
"fa-IR-FaridNeural-Male",
"fi-FI-HarriNeural-Male",
"fi-FI-NooraNeural-Female",
"fil-PH-AngeloNeural-Male",
"fil-PH-BlessicaNeural-Female",
"fr-BE-CharlineNeural-Female",
"fr-BE-GerardNeural-Male",
"fr-CA-AntoineNeural-Male",
"fr-CA-JeanNeural-Male",
"fr-CA-SylvieNeural-Female",
"fr-CA-ThierryNeural-Male",
"fr-CH-ArianeNeural-Female",
"fr-CH-FabriceNeural-Male",
"fr-FR-DeniseNeural-Female",
"fr-FR-EloiseNeural-Female",
"fr-FR-HenriNeural-Male",
"fr-FR-RemyMultilingualNeural-Male",
"fr-FR-VivienneMultilingualNeural-Female",
"ga-IE-ColmNeural-Male",
"ga-IE-OrlaNeural-Female",
"gl-ES-RoiNeural-Male",
"gl-ES-SabelaNeural-Female",
"gu-IN-DhwaniNeural-Female",
"gu-IN-NiranjanNeural-Male",
"he-IL-AvriNeural-Male",
"he-IL-HilaNeural-Female",
"hi-IN-MadhurNeural-Male",
"hi-IN-SwaraNeural-Female",
"hr-HR-GabrijelaNeural-Female",
"hr-HR-SreckoNeural-Male",
"hu-HU-NoemiNeural-Female",
"hu-HU-TamasNeural-Male",
"id-ID-ArdiNeural-Male",
"id-ID-GadisNeural-Female",
"is-IS-GudrunNeural-Female",
"is-IS-GunnarNeural-Male",
"it-IT-DiegoNeural-Male",
"it-IT-ElsaNeural-Female",
"it-IT-GiuseppeNeural-Male",
"it-IT-IsabellaNeural-Female",
"ja-JP-KeitaNeural-Male",
"ja-JP-NanamiNeural-Female",
"jv-ID-DimasNeural-Male",
"jv-ID-SitiNeural-Female",
"ka-GE-EkaNeural-Female",
"ka-GE-GiorgiNeural-Male",
"kk-KZ-AigulNeural-Female",
"kk-KZ-DauletNeural-Male",
"km-KH-PisethNeural-Male",
"km-KH-SreymomNeural-Female",
"kn-IN-GaganNeural-Male",
"kn-IN-SapnaNeural-Female",
"ko-KR-HyunsuNeural-Male",
"ko-KR-InJoonNeural-Male",
"ko-KR-SunHiNeural-Female",
"lo-LA-ChanthavongNeural-Male",
"lo-LA-KeomanyNeural-Female",
"lt-LT-LeonasNeural-Male",
"lt-LT-OnaNeural-Female",
"lv-LV-EveritaNeural-Female",
"lv-LV-NilsNeural-Male",
"mk-MK-AleksandarNeural-Male",
"mk-MK-MarijaNeural-Female",
"ml-IN-MidhunNeural-Male",
"ml-IN-SobhanaNeural-Female",
"mn-MN-BataaNeural-Male",
"mn-MN-YesuiNeural-Female",
"mr-IN-AarohiNeural-Female",
"mr-IN-ManoharNeural-Male",
"ms-MY-OsmanNeural-Male",
"ms-MY-YasminNeural-Female",
"mt-MT-GraceNeural-Female",
"mt-MT-JosephNeural-Male",
"my-MM-NilarNeural-Female",
"my-MM-ThihaNeural-Male",
"nb-NO-FinnNeural-Male",
"nb-NO-PernilleNeural-Female",
"ne-NP-HemkalaNeural-Female",
"ne-NP-SagarNeural-Male",
"nl-BE-ArnaudNeural-Male",
"nl-BE-DenaNeural-Female",
"nl-NL-ColetteNeural-Female",
"nl-NL-FennaNeural-Female",
"nl-NL-MaartenNeural-Male",
"pl-PL-MarekNeural-Male",
"pl-PL-ZofiaNeural-Female",
"ps-AF-GulNawazNeural-Male",
"ps-AF-LatifaNeural-Female",
"pt-BR-AntonioNeural-Male",
"pt-BR-FranciscaNeural-Female",
"pt-BR-ThalitaNeural-Female",
"pt-PT-DuarteNeural-Male",
"pt-PT-RaquelNeural-Female",
"ro-RO-AlinaNeural-Female",
"ro-RO-EmilNeural-Male",
"ru-RU-DmitryNeural-Male",
"ru-RU-SvetlanaNeural-Female",
"si-LK-SameeraNeural-Male",
"si-LK-ThiliniNeural-Female",
"sk-SK-LukasNeural-Male",
"sk-SK-ViktoriaNeural-Female",
"sl-SI-PetraNeural-Female",
"sl-SI-RokNeural-Male",
"so-SO-MuuseNeural-Male",
"so-SO-UbaxNeural-Female",
"sq-AL-AnilaNeural-Female",
"sq-AL-IlirNeural-Male",
"sr-RS-NicholasNeural-Male",
"sr-RS-SophieNeural-Female",
"su-ID-JajangNeural-Male",
"su-ID-TutiNeural-Female",
"sv-SE-MattiasNeural-Male",
"sv-SE-SofieNeural-Female",
"sw-KE-RafikiNeural-Male",
"sw-KE-ZuriNeural-Female",
"sw-TZ-DaudiNeural-Male",
"sw-TZ-RehemaNeural-Female",
"ta-IN-PallaviNeural-Female",
"ta-IN-ValluvarNeural-Male",
"ta-LK-KumarNeural-Male",
"ta-LK-SaranyaNeural-Female",
"ta-MY-KaniNeural-Female",
"ta-MY-SuryaNeural-Male",
"ta-SG-AnbuNeural-Male",
"ta-SG-VenbaNeural-Female",
"te-IN-MohanNeural-Male",
"te-IN-ShrutiNeural-Female",
"th-TH-NiwatNeural-Male",
"th-TH-PremwadeeNeural-Female",
"tr-TR-AhmetNeural-Male",
"tr-TR-EmelNeural-Female",
"uk-UA-OstapNeural-Male",
"uk-UA-PolinaNeural-Female",
"ur-IN-GulNeural-Female",
"ur-IN-SalmanNeural-Male",
"ur-PK-AsadNeural-Male",
"ur-PK-UzmaNeural-Female",
"uz-UZ-MadinaNeural-Female",
"uz-UZ-SardorNeural-Male",
"vi-VN-HoaiMyNeural-Female",
"vi-VN-NamMinhNeural-Male",
"zh-CN-XiaoxiaoNeural-Female",
"zh-CN-XiaoyiNeural-Female",
"zh-CN-YunjianNeural-Male",
"zh-CN-YunxiNeural-Male",
"zh-CN-YunxiaNeural-Male",
"zh-CN-YunyangNeural-Male",
"zh-CN-liaoning-XiaobeiNeural-Female",
"zh-CN-shaanxi-XiaoniNeural-Female",
"zh-HK-HiuGaaiNeural-Female",
"zh-HK-HiuMaanNeural-Female",
"zh-HK-WanLungNeural-Male",
"zh-TW-HsiaoChenNeural-Female",
"zh-TW-HsiaoYuNeural-Female",
"zh-TW-YunJheNeural-Male",
"zu-ZA-ThandoNeural-Female",
"zu-ZA-ThembaNeural-Male",
],width=35)
voice_lib_combobox.pack(side=tk.LEFT, padx=5)
voice_lib_comboboxes.append(voice_lib_combobox)
voice_lib_combobox.bind("<<ComboboxSelected>>", on_voice_change) # ComboBox选择变化时自动保存
# 加载之前保存的角色和语音库
load_roles()
load_voices()
roles_audio_path = r"C:\edgetts\rolesaudio"
os.makedirs(roles_audio_path, exist_ok=True) # Ensure the directory exists
# Initialize a counter for naming MP3 files uniquely
mp3_counter = 10000
async def main(TEXT, VOICE):
"""Main async function to generate MP3."""
if not TEXT.strip():
print("TEXT is empty, audio processing not executed.")
messagebox.showerror("文本为空", "文本为空,未执行音频处理")
return
global mp3_counter # Access the global counter
try:
# Increment the counter and create the filenames
mp3_counter += 1
output_file = os.path.join(roles_audio_path, f"{mp3_counter}.mp3")
webvtt_file = os.path.join(roles_audio_path, f"{mp3_counter}.vtt")
communicate = edge_tts.Communicate(TEXT, VOICE)
submaker = edge_tts.SubMaker()
# Write audio data to the file
with open(output_file, "wb") as file:
async for chunk in communicate.stream():
if chunk["type"] == "audio":
file.write(chunk["data"])
elif chunk["type"] == "WordBoundary":
submaker.create_sub((chunk["offset"], chunk["duration"]), chunk["text"])
# Write subtitles to the WebVTT file
with open(webvtt_file, "w", encoding="utf-8") as file:
file.write(submaker.generate_subs())
print(f"Generated file: {output_file} and {webvtt_file}")
except FileNotFoundError:
print("Error: Unable to find output file or write to path.")
except Exception as e:
print(f"Error processing audio and metadata: {e}")
messagebox.showerror("网络连接失败", f"处理音频和元数据时发生错误: {e}")
原始代码如下,可以根据这个代码进行加工升级,就可以估出类似的朗读机。
import tkinter as tk
from tkinter import ttk, messagebox
import edge_tts
import asyncio
import re # 导入正则表达式模块
import os
# 可选的语音列表
voices = [
"zh-CN-XiaoxiaoNeural", "zh-CN-YunyangNeural", # 中文女声1, 中文男声
"en-US-JennyNeural", "en-US-GuyNeural", # 英文女声1, 英文男声
"de-DE-KatjaNeural", "de-DE-MichaelNeural", # 德文女声1, 德文男声
"fr-FR-DeniseNeural", "fr-FR-HugoNeural", # 法文女声1, 法文男声
"ja-JP-AikoNeural", "ja-JP-KenjiNeural", # 日文女声1, 日文男声
"es-ES-MariaNeural", "es-ES-PabloNeural", # 西班牙女声1, 西班牙男声
"it-IT-RobertaNeural", "it-IT-GiorgioNeural", # 意大利女声1, 意大利男声
"ko-KR-SumiNeural", "ko-KR-MinSookNeural" # 韩文女声1, 韩文男声
]
class TextToSpeechApp:
def __init__(self, root):
self.root = root
self.root.title("对话朗读程序")
# 初始化角色与语音选择
self.character_entries = []
self.voice_comboboxes = []
self.voice_map = {} # 初始化语音映射
# 创建角色输入框和语音选择框
for i in range(16):
character_entry = tk.Entry(root, width=15)
character_entry.grid(row=i, column=0, padx=10, pady=5)
self.character_entries.append(character_entry)
voice_combobox = ttk.Combobox(root, values=voices, width=30)
voice_combobox.grid(row=i, column=1, padx=10, pady=5)
self.voice_comboboxes.append(voice_combobox)
voice_combobox.current(0) # 默认选择第一个声音
# 创建对话文本输入框
self.dialogue_frame = tk.Frame(root)
self.dialogue_frame.grid(row=0, column=2, rowspan=16, padx=10, pady=5)
self.dialogue_text = tk.Text(self.dialogue_frame, height=10, width=50)
self.dialogue_text.pack(expand=True, fill='both')
# 创建对话框边框
scrollbar = tk.Scrollbar(self.dialogue_frame, command=self.dialogue_text.yview)
scrollbar.pack(side='right', fill='y')
self.dialogue_text['yscrollcommand'] = scrollbar.set
# 创建朗读按钮
read_button = tk.Button(root, text="朗读对话", command=self.read_dialogue)
read_button.grid(row=16, column=0, columnspan=3, pady=10)
async def speak_dialogue(self, dialogue_lines):
for character, line in dialogue_lines:
voice = self.voice_map.get(character)
if voice:
# 生成有效的文件名
output_file = f"{character}.mp3"
communicate = edge_tts.Communicate(text=line.strip(), voice=voice)
await communicate.save(output_file)
print(f"生成语音文件:{output_file}")
else:
print(f"未找到角色 {character} 的声音设置")
def read_dialogue(self):
# 获取对话文本
dialogue_content = self.dialogue_text.get("1.0", tk.END).strip()
if not dialogue_content:
messagebox.showwarning("警告", "请在对话文本框中输入内容!")
return
# 收集角色及其对应对话内容
dialogue_lines = []
lines = dialogue_content.split('\n')
# 填充语音映射
for i, line in enumerate(lines):
match = re.match(r'([A-Z]):\s*(.*)', line.strip())
if match:
character = match.group(1) # 角色名
dialogue_line = match.group(2) # 对话内容
# 获取当前选定的语音
selected_voice = self.voice_comboboxes[i].get()
self.voice_map[character] = selected_voice # 更新语音映射
dialogue_lines.append((character, dialogue_line))
if dialogue_lines:
asyncio.run(self.speak_dialogue(dialogue_lines))
else:
messagebox.showwarning("警告", "未检测到有效的对话!")
if __name__ == "__main__":
root = tk.Tk()
app = TextToSpeechApp(root)
root.mainloop()

















 5762
5762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









