







文章目录
一、深度学习中的Epoch,Batchsize,Iterations
一个epoch指代所有的数据送入网络中完成一次前向计算及反向传播的过程。由于一个epoch常常太大,计算机无法负荷,我们会将它分成几个较小的batches。
Iterations
所谓iterations就是完成一次epoch所需的batch个数。
batch numbers就是iterations。
简单一句话说就是,我们有2000个数据,分成4个batch,那么batch size就是500。运行所有的数据进行训练,完成1个epoch,需要进行4次iterations。
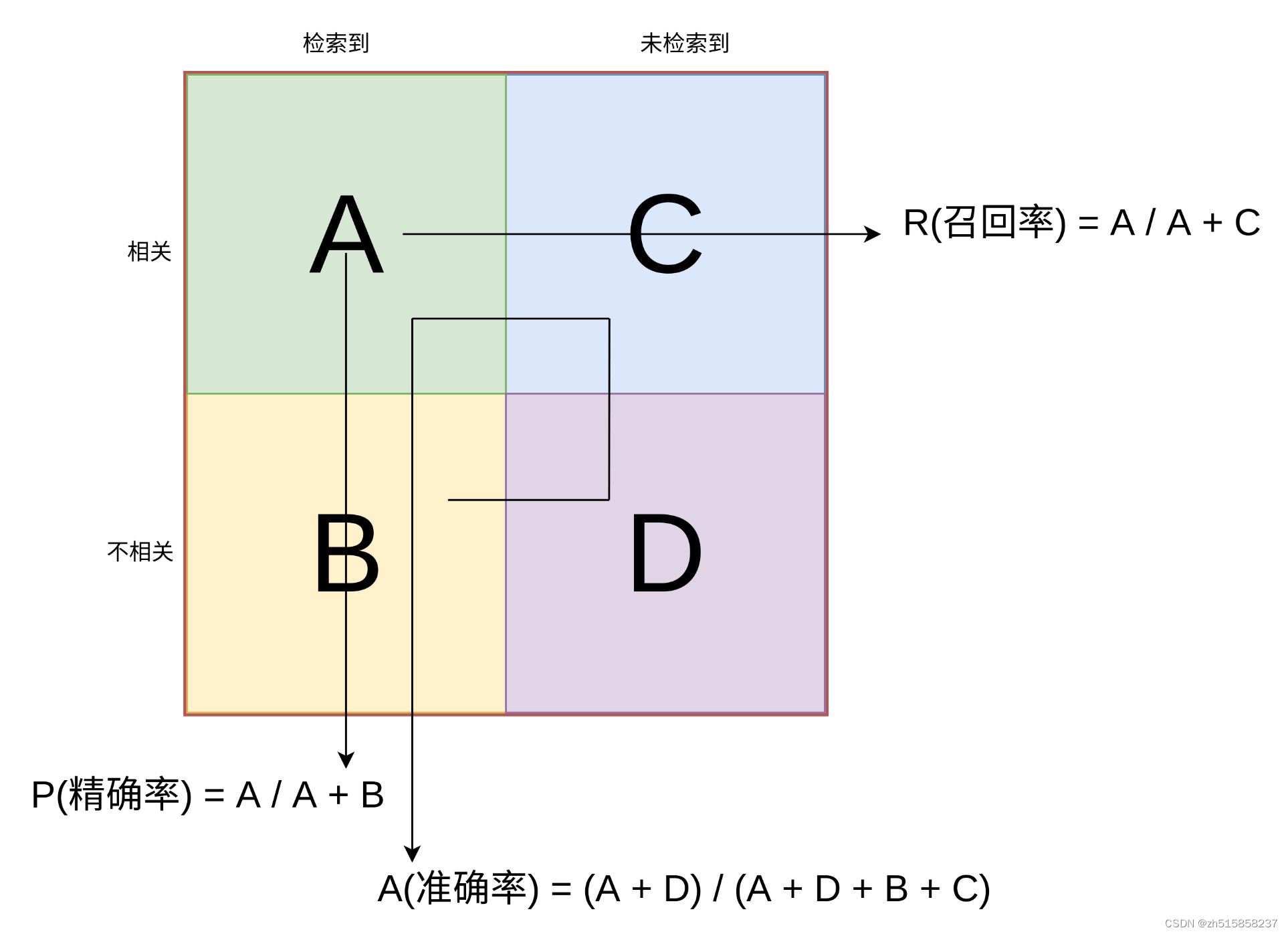
二、什么是准确率(Accuracy) 、精确率(Precision) 、召回率(Recall)
准确率(Accuracy)——分类器正确分类的样本数与样本总数之比,就称为准确率,即(TP+TN)/(TP+TN+FP+FN)
三、什么是先验概率、后验概率、似然概率
先验概率可理解为统计概率,后验概率可理解为条件概率。
1)先验——根据若干年的统计(经验)或者气候(常识),某地方下雨的概率;
2)似然——下雨(果)的时候有乌云(因/证据/观察的数据)的概率,即已经有了果,对证据发生的可能性描述;
3)后验——根据天上有乌云(原因或者证据/观察数据),下雨(结果)的概率;
四、什么是迁移学习
迁移学习指的是利用预训练模型(神经网络的权重和参数都已经被其他人利用更大规模的数据集训练好了)并用自己的数据集将模型「微调」的过程。这种思路中预训练模型扮演着特征提取器的角色。你将移除网络的最后一层并用你自有的分类器置换(取决于你的问题空间)。然后冻结其他所有层的权重并正常训练该网络(冻结这些层意味着在梯度下降/最优化过程中保持权值不变)。
五、人的大脑神经元同时处于激活状态的比例是多少
从脑神经科学的角度来看,大脑神经元只有1%~4%的部分同时处于激活状态,这是大脑在表现丰富性和能量消耗之间做的一个平衡,所以说大脑中神经元的激活其实是处于一种稀疏状态的。(摘抄自:《Deep Sparse Rectifier Neural Networks》)
六、残差连接是什么
网络层数增加了,根据导数的链式法则,就容易出现梯度消散或爆炸等问题。例如,如果各网络层激活函数的导数都比较小,那么在多次连乘后梯度可能会越来越小,这就是常说的梯度消散。对于深层网络来说,传到浅层,梯度几乎就没了。
在解决这类问题时,除了采用合适的激活函数外,还有一个重要技巧,即使用残差连接。
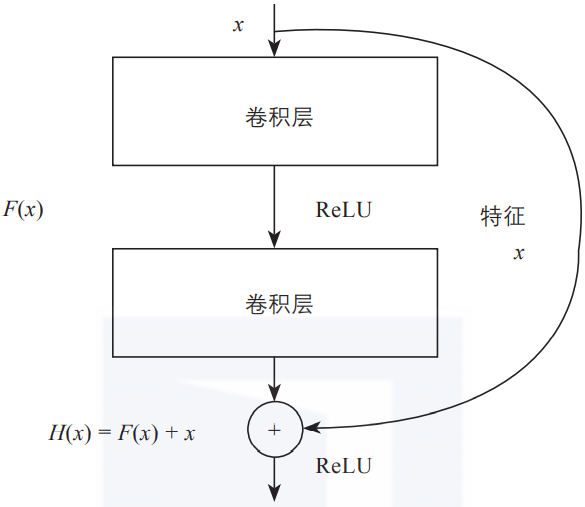
如上图所示,每一个导数都加上了一个恒等项1,dh/dx = d(f + x)/dx = 1 + df/dx。此时就算原来的导数df/dx很小,误差仍然能够有效地反向传播,这也是残差连接的核心思想。
七、迁移学习和微调是啥关系
其实 “Transfer Learning” 和 “Fine-tune” 并没有严格的区分,含义可以相互交换,只不过后者似乎更常用于形容迁移学习的后期微调中。
我个人的理解,微调应该是迁移学习中的一部分。微调只能说是一个trick。
八、如何微调
对于不同的领域微调的方法也不一样,比如语音识别领域一般微调前几层,图片识别问题微调后面几层,这个原因我这里也只能讲个大概,具体还要大神来解释:
- 对于图片来说,我们CNN的前几层学习到的都是低级的特征,比如,点、线、面,这些低级的特征对于任何图片来说都是可以抽象出来的,所以我们将他作为通用数据,只微调这些低级特征组合起来的高级特征即可,例如,这些点、线、面,组成的是圆还是椭圆,还是正方形,这些代表的含义是我们需要后面训练出来的。
- 对于语音来说,每个单词表达的意思都是一样的,只不过发音或者是单词的拼写不一样,比如 苹果,apple,apfel(德语),都表示的是同一个东西,只不过发音和单词不一样,但是他具体代表的含义是一样的,就是高级特征是相同的,所以我们只要微调低级的特征就可以了。
另外,
1.新数据集和原始数据集合类似,那么直接可以微调一个最后的FC层或者重新指定一个新的分类器
2.新数据集比较小和原始数据集合差异性比较大,那么可以使用从模型的中部开始训练,只对最后几层进行fine-tuning
3.新数据集比较小和原始数据集合差异性比较大,如果上面方法还是不行的化那么最好是重新训练,只将预训练的模型作为一个新模型初始化的数据
4.新数据集的数据尺寸大小一定要与原始数据集相同,比如CNN中输入的图片大小一定要相同,才不会报错
九、如何解决神经网络训练时loss不下降的问题
下面这篇文章讲得很好:
https://mp.weixin.qq.com/s/IHAiQEZEt_Gr_DlZVKrzvg
十、如何对推理做加速
- onnx
- tensorRT
- 模型蒸馏
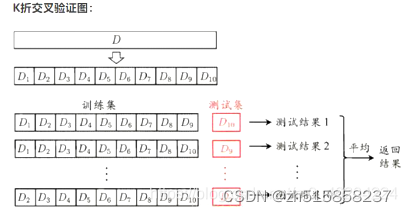
十一、什么是交叉验证
交叉验证,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。在此基础上可以得到多组不同的训练集和测试集,某次训练集中的某样本在下次可能成为测试集中的样本,即所谓“交叉”。
那么什么时候才需要交叉验证呢?交叉验证用在数据不是很充足的时候。比如在我日常项目里面,对于普通适中问题,如果数据样本量小于一万条,我们就会采用交叉验证来训练优化选择模型。如果样本大于一万条的话,我们一般随机的把数据分成三份,一份为训练集,一份为验证集,最后一份为测试集。用训练集来训练模型,用验证集来评估模型预测的好坏和选择模型及其对应的参数。把最终得到的模型再用于测试集,最终决定使用哪个模型以及对应参数。
K折交叉验证(K-Folder Cross Validation)会把样本数据随机的分成K份,每次随机的选择K-1份作为训练集,剩下的1份做测试集。当这一轮完成后,重新随机选择K-1份来训练数据。如下图所示:
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, random_state=4590, shuffle=True)
- n_splits int,默认= 5。必须至少为2
- random_state int,默认=无。如果不设置random_state的话,则每次构建的模型是不同的。
- shuffle bool,默认= False
十二、NLP任务中广泛使用的新范式
NLP任务中广泛使用的新范式归为以下7类,即分类(Class)、匹配(Matching)、序列标注(Seq Lab)、阅读理解(MRC)、序列到序列(Seq2Seq)、序列到动作序列(Seq2ASeq)和语言模型((M)LM)。
具体的范式描述如下:
分类范式(Class)为文本指定预定义的标签。文本分类通常将文本输入一个基于深度神经网络的编码器来提取特征,然后将其输入一个浅层分类器来预测标签,如 =CLS(ENC( ))。 可以是独热编码,ENC(⋅)通常是卷积网络、循环网络或Transformers,CLS(⋅)常由一个简单的多层感知器和汇聚层实现。
匹配范式(Matching)是预测两个文本语义相关性的一种范式。Matching范式可以简单地表述为 =CLS(ENC( , )), 和 是被预测的两段文本, 可以是离散或连续的。
序列标注范式(Seq Lab)可用于模拟各种任务,如词性标注(POS)、命名实体识别(NER)和组块分析。传统的基于神经网络的序列标注模型由编码器和解码器组成,如 1,⋯, =DEC(ENC( 1,⋯, ))。 1,⋯, 是 1,⋯, 对应的标签。
机器阅读理解范式(MRC)从输入序列中提取连续词元序列(span)来回答给定的问题。MRC范式可以描述为 ⋯ + =DEC(ENC( , )), 和 表示篇章和问题, ⋯ + 是从 或 中获得span。
序列到序列范式(Seq2Seq)是一种通用且功能强大的范式,可以处理各种NLP任务。Seq2Seq范式通常由编码器—解码器框架实现,如 1,⋯, =DEC(ENC( 1,⋯, ))。与Seq Lab不同,这里输入和输出的长度不需要相同。
序列到动作序列范式(Seq2ASeq)是一种广泛使用的结构化预测范式。Seq2ASeq范式的例子通常被称为基于转移的模型,可规范为 =CLS(ENC( ), ), = 1,⋯, 是动作序列, = 1,⋯, −1是状态序列。
语言模型范式(LM)估计给定单词序列出现在句子中的概率。它可以被简单表示为 =DEC( 1,⋯, −1),DEC可以是任何自回归的模型。一种LM的变体ML可以被规范为: =DEC(ENC( ̃)), ̃由将 的一些词元(token)替换为特殊词元[MASK]得到, 表示待预测的词元。
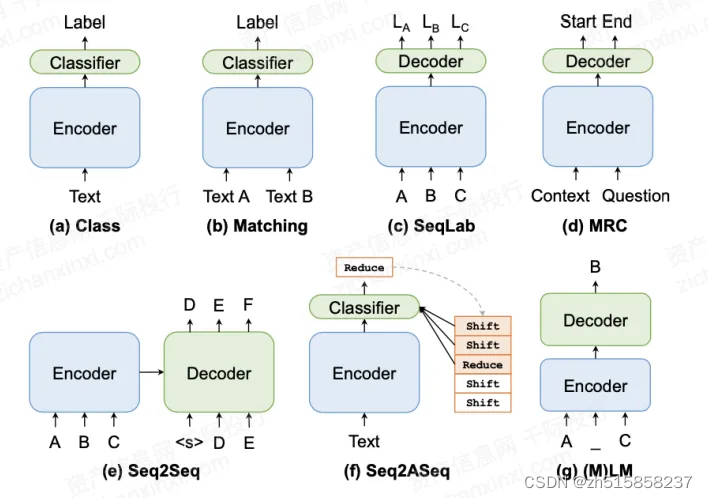
图:自然语言处理中的七种主流范式
参考文献:
- https://www.zhihu.com/question/52668301
- 《Deep Sparse Rectifier Neural Networks》
- https://www.51cto.com/article/667563.html
- https://blog.csdn.net/weixin_40852935/article/details/115461422 (讲述finetune相关)
- https://blog.csdn.net/goodmorning2014/article/details/83302444
- https://tangshusen.me/Dive-into-DL-PyTorch/#/chapter03_DL-basics/3.11_underfit-overfit
- https://www.cnblogs.com/pinard/p/5992719.html
- https://blog.csdn.net/weixin_43935696/article/details/113873603
- https://blog.csdn.net/m0_46204224/article/details/105617436
- https://zhuanlan.zhihu.com/p/493320250















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









