







Boyer-Moore算法
简介
Boyer-Moore算法是1977年,Robert S.Boyer和J Strother Moore提出了另一种在O(n)时间复杂度内,完成字符串匹配的算法,其在绝大多数场合的性能表现,比KMP算法还要出色。KMP算法和BM算法,它们分别是前缀匹配和后缀匹配的经典算法。
上一篇文章中介绍的KMP算法,并不是效率最高的算法,实际采用并不多。各种文本编辑器的”查找”功能(Ctrl+F),大多采用Boyer-Moore算法。
BM算法实现原理
这里根据Moore教授自己的例子来解释这种算法(简单易懂)。
1.

设字符串为”HERE IS A SIMPLE EXAMPLE”,搜索词为”EXAMPLE”。
2.

首先,”字符串”与”搜索词”头部对齐,从尾部开始比较。
因为如果尾部字符不匹配,那么只要一次比较,就可以知道前7个字符肯定不是要找的结果。
首先,”S”与”E”不匹配。”S”就被称为”坏字符”,即不匹配的字符。我们还发现,”S”不包含在搜索词”EXAMPLE”之中,这意味着可以把搜索词直接移到”S”的后一位。
3.

依然从尾部开始比较,发现”P”与”E”不匹配,所以”P”是”坏字符”。但是,”P”包含在搜索词”EXAMPLE”之中。所以,将搜索词后移两位,两个”P”对齐。
4.
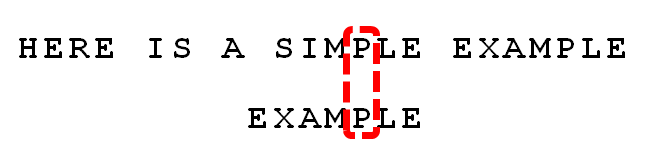
由此总结出”坏字符规则”:
后移位数 = 坏字符的位置 - 搜索词中的上一次出现位置
如果”坏字符”不包含在搜索词之中,则上一次出现位置为 -1。
以”P”为例,它作为”坏字符”,出现在搜索词的第6位(搜索词从0开始编号),在搜索词中的上一次出现位置为4,所以后移 6 - 4 = 2位。再以前面第二步的”S”为例,它出现在第6位,上一次出现位置是 -1(即未出现),则整个搜索词后移 6 - (-1) = 7位。
5.

依然从尾部开始比较,”E”与”E”匹配。
6.
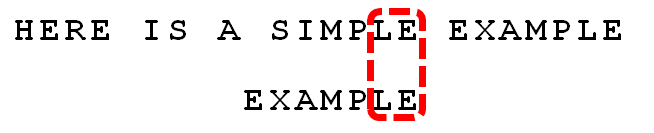
比较前面一位,”LE”与”LE”匹配。
7.
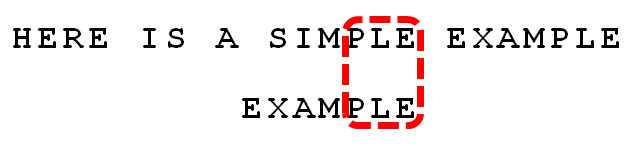
比较前面一位,”PLE”与”PLE”匹配。
8.

比较前面一位,”MPLE”与”MPLE”匹配。我们把这种情况称为”好后缀”(good suffix),即所有尾部匹配的字符串。注意,”MPLE”、”PLE”、”LE”、”E”都是好后缀。
9.
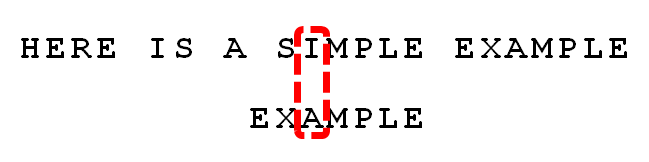
比较前一位,发现”I”与”A”不匹配。所以,”I”是”坏字符”。
10.
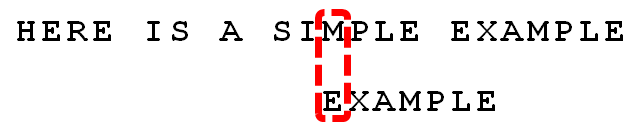
根据”坏字符规则”,此时搜索词应该后移 2 - (-1)= 3 位。问题是,此时有没有更好的移法?
11.

我们知道,此时存在”好后缀”。所以,可以采用”好后缀规则”:
后移位数 = 好后缀的位置 - 搜索词中的上一次出现位置
计算时,位置的取值以”好后缀”的最后一个字符为准。如果”好后缀”在搜索词中没有重复出现,则它的上一次出现位置为 -1。
所有的”好后缀”(MPLE、PLE、LE、E)之中,只有”E”在”EXAMPLE”之中出现两次,所以后移 6 - 0 = 6位。
12.
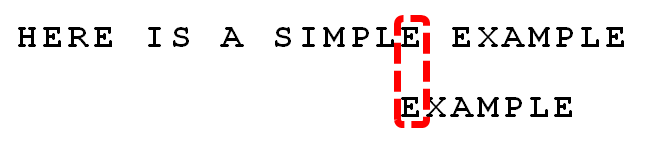
可以看到,”坏字符规则”只能移3位,”好后缀规则”可以移6位。所以,Boyer-Moore算法的基本思想是,每次后移这两个规则之中的较大值。
更巧妙的是,这两个规则的移动位数,只与搜索词有关,与原字符串无关。因此,可以预先计算坏字符规则和好后缀规则的大小,或者生成《坏字符规则表》和《好后缀规则表》。使用时,只要查表比较一下就可以了。(后面代码中是实现一个好后缀规则表和坏字符规则函数,进行比较大小)。
13.
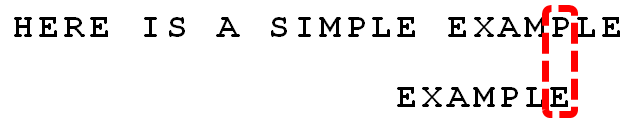
继续从尾部开始比较,”P”与”E”不匹配,因此”P”是”坏字符”。根据”坏字符规则”,后移 6 - 4 = 2位。
14.

从尾部开始逐位比较,发现全部匹配,于是搜索结束。如果还要继续查找(即找出全部匹配),则可继续重复以上操作即可。
C语言实现
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
typedef int status;
#define MAXSIZE 100
#define ERROR 0
#define TRUE 1
//获取value“后缀规则”,移动距离
status GetValue(int **value,char *target){
int i = 0,j = 0;
char temp;
int tarlen = strlen(target);
(*value) = (int *)malloc(sizeof(int) *MAXSIZE);
if(!(*value))return ERROR;
for(i = 0; i < MAXSIZE; i++){ //初始化
(*value)[i] = -1; //-1代表后缀无匹配的字符
}
for(i = tarlen -1; i >0; i--){
temp = target[i];
if(i <tarlen -1)
(*value)[i] = (*value)[i+1]; //后一位赋值到前一位
for(j = 0; j<i ;j++){
if(target[j] ==temp){
(*value)[i] = i - j; //移动的距离
}
}
}
return TRUE;
}
//初始化字符串和搜索词
status InitData(char **source,char **target){
char ch;
int i =0;
(*source) = (char *)malloc(sizeof(char) * MAXSIZE); //初始化
(*target) = (char *)malloc(sizeof(char) * MAXSIZE);
if(!(*source) || !(*target))return ERROR;
printf("请输入字符串以#结束:\n");
while((ch=getchar())!='#'){
(*source)[i++] = ch;
(*source)[i] = '\0';
}
printf("请输入搜索词以#结束:\n");
getchar(); //回车清除
i = 0;
while((ch =getchar())!='#'){
(*target)[i++] = ch;
(*target)[i] = '\0';
}
return TRUE;
}
//获取“坏字符”移动距离
int BadValue(char bad,char *target){
int i =0;
int badindex = -1;
for(i = 0; i < strlen(target); i++){
if(bad==target[i]){
badindex = strlen(target) - 1 - i;
}
}
return badindex;
}
//BM算法
status BM(char *source,char *target, int *value){
int i = 0,j = 0, soulen = strlen(source),tarlen = strlen(target); //初始化
int badvalue = 0,distance = 0;
if(soulen<tarlen){ //比较长度
printf("字符串的长度小于搜索词的长度\n");
return ERROR;
}
i = tarlen -1;j = tarlen -1; //从尾开始匹配
while(i < soulen ){
if(source[i] == target[j]){ //字符匹配成功
if(j ==0){
printf("匹配成功\n");
return TRUE;
}
i--;j--;
}else{ //未匹配成功
if(j == tarlen -1){ //如果尾字符未匹配成功,"坏字符规则"
badvalue = BadValue(source[i],target);
if(badvalue == -1)
badvalue = strlen(target);
i =i+ tarlen - 1 - j + badvalue;
j = tarlen -1;
}else{ //有后缀,比较"坏字符规则"和"后缀规则"
badvalue = BadValue(source[i],target);
if(badvalue == -1)
badvalue = strlen(target);
distance = badvalue > value[j-1] ? badvalue : value[j-1];
printf("移动距离:%d\n",distance);
j = tarlen -1; //更新j位置
i = i+ tarlen - 1 - j + distance; //更新i的位置
}
}
}
printf("匹配失败....");
return ERROR;
}
void main(){
char *source,*target; //source字符串,target搜索词
int *value; //好后缀词表
int i = 0;
InitData(&source,&target); //初始化
GetValue(&value,target); //获取后缀表
BM(source,target,value); //BM算法
for(i = 0; i<strlen(target);i++){
printf("%d\n",value[i]);
}
if(source && target){
printf("%s\n",source);
printf("%s\n",target);
}
}














 2299
2299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









