







一、数据模型
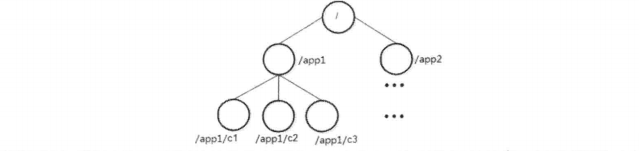
在 ZooKeeper 中,每一个数据节点都被称为一个 ZNode,所有 ZNode 按层次化结构进行组织,形成一棵树
事务id
在 ZooKeeper 中,事务是指能够改变 ZooKeeper 服务器状态的操作,我们也称之为事务操作或更新操作,一般包括数据节点创建与删除、数据节点内容更新和客户端会话创建与失效等操作。对于每一个事务请求,ZooKeeper都会为其分配一个全局唯一的事务 ID,用 ZXID 来表示,通常是一个 64 位的数字。每一个 ZXID 对应一次更新操作,从这些 ZXID 中可以间接地识别出 ZooKeeper 处理这些更新操作请求的全局顺序。
二、节点特性
ZooKeeper 的命名空间是由一系列数据节点组成的在 ZooKeeper 中,每个数据节点都是有生命周期的,其生命周期的长短取决于数据节点的节点类型。在 ZooKeeper 中,节点类型可以分为持久节点(PERSISTENT)、临时节点(EPHEMERAL)和顺序节点(SEQUENTIAL)三大类,具体在节点创建过程中,通过组合使用,可以生成以下四种组合型节点类型∶
1.持久节点(PERSISTENT)
持久节点是 ZooKeeper 中最常见的一种节点类型。所谓持久节点,是指该数据节点被创建后,就会一直存在于ZooKeeper 服务器上,直到有删除操作来主动清除这个节点。
2.持久顺序节点(PERSISTENT_SEQUENTIAL)
持久顺序节点的基本特性和持久节点是一致的,额外的特性表现在顺序性上。在 ZooKeeper 中,每个父节点都会为它的第一级子节点维护一份顺序,用于记录下每个子节点创建的先后顺序。基于这个顺序特性,在创建子节点的时候,可以设置这个标记,那么在创建节点过程中,ZooKeeper 会自动为给定节点名加上一个数字后缀,作为一个新的、完整的节点名。另外需要注意的是,这个数字后缀的上限是整型的最大值。
3.临时节点(EPHEMERAL)
和持久节点不同的是,临时节点的生命周期和客户端的会话绑定在一起,也就是说,如果客户端会话失效,那么这个节点就会被自动清理掉。注意,这里提到的是客户端会话失效,而非 TCP连接断开。另外,ZooKeeper 规定了不能基于临时节点来创建子节点,即临时节点只能作为叶子节点。
4.临时顺序节点(EPHEMERAL SEQUENTIAL)
临时顺序节点的基本特性和临时节点也是一致的,同样是在临时节点的基础上,添加了顺序的特性。
三、版本
1.版本概念
为了保证分布式数据原子性操作,ZooKeeper 中为数据节点引入了版本的概念,每个数据节点都具有三种类型的版本信息,对数据节点的任何更新操作都会引起版本号的变化

ZooKeeper 中的版本概念和传统意义上的软件版本有很大的区别,它表示的是对数据节点的数据内容、子节点列表,或是节点ACL 信息的修改次数,我们以其中的 version这种版本类型为例来说明。在一个数据节点/zk-book 被创建完毕之后,节点的 version值是 0,表示的含义是"当前节点自从创建之后,被更新过0次"。如果现在对该节点的数据内容进行更新操作,那么随后,version的值就会变成1。
需要注意的是其表示的是对数据节点数据内容的变更次数,强调的是变更次数,因此即使前后两次变更并没有使得数据内容的值发生变化,version的值依然会变更
2.zookeeper如何使用版本保证分布式数据一致性呢
事实上,在 ZooKeeper 中, version 属性正是用来实现乐观锁机制中的"写入校验"的,我们其实可以把一个乐观锁控制的事务分成如下三个阶段∶数据读取、写入校验和数据写入,其中写入校验阶段是整个乐观锁控制的关键所在。在写入校验阶段,事务会检查数据在读取阶段后是否有其他事务对数据进行过更新,以确保数据更新的一致性。那么,如何来进行写入校验呢?我们首先可以来看下 JDK 中最典型的乐观锁实现——CAS。
3.校验流程
在进行一次 setDataRequest 请求处理时,首先进行了版本检查∶ZooKeeper会从setDataRequest请求中获取到当前请求的版本version,同时从数据记录 nodeRecord中获取到当前服务器上该数据的最新版本 currentVersion。如果 version 为"-1",那么说明客户端并不要求使用乐观锁,可以忽略版本比对,如果 version不是"-1",那么就比对version和 currentVersion,如果两个版本不匹配,那么将会抛出 BadVersionException 异常。
四、Watcher机制
1.工作内容
在 ZooKeeper 中,引入了 Watcher 机制来实现分布式的通知功能。 ZooKeeper 允许客户端向服务端注册一个 Watcher 监听,当服务端的一些指定事件触发了这个 Watcher,那么就会向指定客户端发送一个事件通知来实现分布式的通知功能。
zookeeper很多应用场景都用到了该机制,例如数据的发布/订阅,一个典型的发布/阅模型系统定义了一种一对多的订阅关系,能够让多个订阅者同时监听某一个主题对象,当这个主题对象自身状态变化时,会通知所有订阅者,使它们能够做出相应的处理。
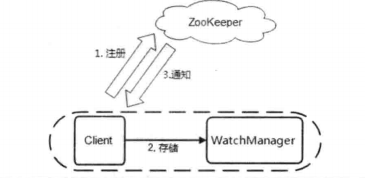
如图 ,我们可以看到,ZooKeeper 的 Watcher 机制主要包括客户端线程、客户端 WatchManager 和 ZooKeeper 服务器三部分。在具体工作流程上,简单地讲,客户端在向 ZooKeeper 服务器注册 Watcher 的同时,会将 Watcher 对象存储在客户端的 WatchManager 中。当ZooKeeper 服务器端触发 Watcher 事件后,会向客户端发送通知,客户端线程从 WatchManager 中取出对应的 Watcher 对象来执行回调逻辑。
2,客户端注册wacher流程:
(1)调用 getData()/getChildren()/exist()三个 API,传入 Watcher 对象
(2)标记请求 request,封装 Watcher 到 WatchRegistration
(3)封装成 Packet 对象,发服务端发送 request
(4)收到服务端响应后,将 Watcher 注册到 ZKWatcherManager 中进行管理
(5)请求返回,完成注册。
2.服务端处理wacher流程
(1)服务端接收 Watcher 并存储
接收到客户端请求,处理请求判断是否需要注册 Watcher,需要的话将数据节点的节点路径和 ServerCnxn(ServerCnxn 代表一个客户端和服务端的连接,实现了 Watcher 的 process 接口,此时可以看成一个 Watcher 对象)存储在WatcherManager 的 WatchTable 和 watch2Paths 中去。
(2)封装 WatchedEvent
首先将通知状态(KeeperState)、事件类型(EventType)以及节点路径(Path)封装成一个 WatchedEvent 对象。
(3)查询 Watcher
根据数据节点的节点路径从 watchTabLe 中取出对应的 Watcher。如果没有找到 Watcher,说明没有任何客户端在该数据节点上注册过 Watcher,直接退出。而如果找到了这个 Watcher,会将其提取出来,同时会直接从 watchTable和 watch2Paths 中将其删除——从这里我们也可以看出,Watcher 在服务端是一次性的,即触发一次就失效了。
(4)调用 process 方法来触发 Watcher。
在这一步中,会逐个依次地调用从步骤 3 中找出的所有 Watcher 的 process方法。那么这里的 process 方法究竟做了些什么呢?在上文中我们已经提到,对于需要注册 Watcher 的请求,ZooKeeper 会把当前请求对应的 ServerCnxn 作为一个 Watcher 进行存储,因此,这里调用的 process方法
3.客户端回调wacher流程
客户端 SendThread 线程接收事件通知,交由 EventThread 线程回调 Watche
(1)反序列化。
ZooKeeper客户端接到请求后,首先会将字节流转换成 WatcherEvent 对象。
(2)处理 chrootPath。
如果客户端设置了chrootPath 属性,那么需要对服务端传过来的完整的节点路径进行 chrootPath处理,生成客户端的一个相对节点路径。例如客户端设置了 chrootPath 为/appl,那么针对服务端传过来的响应包含的节点路径为/app/locks,经过chrootPath处理后,就会变成一个相对路径∶/locks。
(3)还原 WatchedEvent。
在本节的"回调方法 process()部分"中提到,process 接口的参数定义是 WatchedEvent,因此这里需要将 WwatcherEvent 对象转换成 Watched Event。
(4)回调 watcher。
最后将 WatchedEvent 对象交给 EventThread 线程,在下一个轮询周期中进行 Watcher 回调。
4. ACL(Access Control List)访问控制列表
ACL 权限控制,使用:scheme:id:perm 来标识,主要涵盖 3 个方面:
(1)权限模式(Scheme):授权的策略
(2)授权对象(ID):授权的对象
(3)权限(Permission):授予的权限
其特性如下:
ZooKeeper的权限控制是基于每个znode节点的,需要对每个节点设置权限
每个znode支持设置多种权限控制方案和多个权限
子节点不会继承父节点的权限,客户端无权访问某节点,但可能可以访问它的子节点
4.1.权限模式(Scheme)
权限模式分成四个 等级
(1)IP:从 IP 地址粒度进行权限控制
(2)Digest:最常用,用类似于 username:password 的权限标识来进行权限配置,便于区分不同应用来进行权限控制
(3)World:最开放的权限控制方式,是一种特殊的 digest 模式,只有一个权限标“world:anyone”
(4)Super:超级用户
4.2.授权对象
授权对象指的是权限赋予的用户或一个指定实体,例如 IP 地址或是机器灯。
4.3.权限 Permission
(1)CREATE:数据节点创建权限,允许授权对象在该 Znode 下创建子节点
(2)DELETE:子节点删除权限,允许授权对象删除该数据节点的子节点
(3)READ:数据节点的读取权限,允许授权对象访问该数据节点并读取其数据内容或子节点列表等
(4)WRITE:数据节点更新权限,允许授权对象对该数据节点进行更新操作
(5)ADMIN:数据节点管理权限,允许授权对象对该数据节点进行 ACL 相关设置操作















 1295
1295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









