






前言
喜欢看网络小说的朋友们,经常需要从网上下载小说。有些人不想向正版网页交钱,也不想注册其他网站的账号,那么对于某些比较冷门的小说或者是正在更新的小说来说,就很难下载到txt或者其他格式的小说。
这篇文章主要给大家介绍了小说内容的获取方法,基于网络爬虫,通过requests爬虫库和bs4选择器进行实现,并且给大家例举了常见问题的处理方法。
那么接下来开始我的示范:
一、小说下载

如果你想下载该网站上的任意一本小说的话,直接点击链接进去,如下图所示。

只要将URL中的这个数字拿到就可以了,比方说这里是951,那么这个数字代表的就是这本书的书号,在后面的代码中可以用得到的。
二、具体实现
这里是代码部分,如下所示:
"""
[使用模块]: requests >>> pip install requests <第三方模块>
parsel >>> pip install parsel <第三方模块>
prettytable >>> pip install prettytable <第三方模块>
"""
import requests # 第三方的模块
import parsel # 第三方的模块
import os # 内置模块 文件或文件夹
filename = '小说\\'
if not os.path.exists(filename):
os.mkdir(filename)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
}
rid = input('输入书名ID:')
link = f'https://www.bqg70.com/book/{rid}/'
html_data = requests.get(url=link, headers=headers).text
# print(html_data)
selector_2 = parsel.Selector(html_data)
divs = selector_2.css('.listmain dd')
for div in divs:
title = div.css('a::text').get()
href = div.css('a::attr(href)').get()
url = 'https://www.bqg70.com' + href
try:
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
# getall 返回的是一个列表 []
book = selector.css('#chaptercontent::text').getall()
book = '\n'.join(book)
# 数据保存
with open(filename + title + '.txt', mode='a', encoding='utf-8') as f:
f.write(book)
print('正在下载章节: ', title)
except Exception as e:
print(e)
程序运行之后,在控制台输入书号,即可开始进行抓取了。

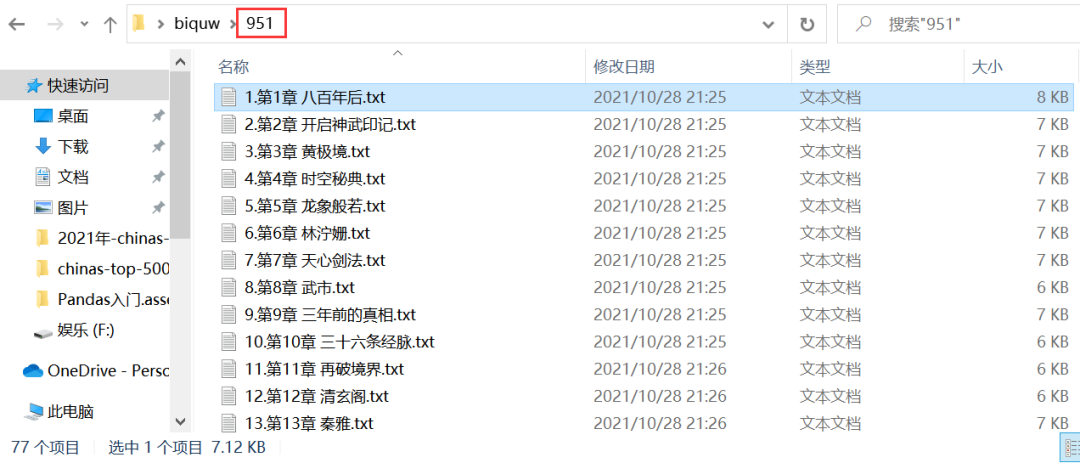
在本地也会自动新建一个书号命名的文件夹,在该文件夹下,会存放小说的章节,如下图所示。
三、常见问题
在运行过程中小伙伴们应该会经常遇到这个问题,如下图所示。

这个是因为访问太快,网站给你反爬了。可以设置随机的user-agent或者上代理等方法解决。

最后
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
最后这里免费分享给大家一份Python全台学习资料,包含视频、源码。课件,希望能帮到那些不满现状,想提升自己却又没有方向的朋友,也可以和我一起来学习交流呀。
编程资料、学习路线图、源代码、软件安装包等!【[点击这里]】领取!
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习
⑤ 历年互联网企业Python面试真题,复习时非常方便


















 7827
7827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









