






1. NumPy的优势
1.1 NumPy介绍
NumPy(Numerical Python)是一个开源的科学计算库,用于快速处理任意维度的数组。
Numpy支持常见的数组和矩阵操作。对于同样的数值计算任务,使用Numpy比直接使用Python要简洁的多。
NumPy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
在大多数情况下,NumPy都会随Python一起安装,但如果你需要单独安装,可以使用pip进行安装:
pip install numpy
NumPy的主要功能有:
- 数组计算:NumPy的核心是ndarray(多维数组对象),提供了快速的数学运算、逻辑运算、形状操作、广播等功能。
- 矩阵操作:NumPy允许进行矩阵乘法、求逆、求特征值等线性代数运算。
- 随机数生成:NumPy提供了生成随机数的能力,可以创建符合正态分布、均匀分布等不同分布的随机数组。
- 数值积分与优化:NumPy包含了数值积分和优化算法,适用于求解函数的积分和最值问题。
- 文件读写:NumPy支持读写多种格式的数组文件,如.npy、.npz等。
- 线性代数:提供了丰富的线性代数函数,包括矩阵运算、求解线性方程组、特征值和特征向量等。
- 傅里叶变换:NumPy包含了傅里叶变换的相关函数,可以用于信号处理、图像处理等领域。
1.2 ndarray介绍
NumPy提供了一个N维数组类型ndarray,它描述了相同类型的"itme"组合。ndarray 提供了高效的存储和处理大型数据集的能力,是进行科学计算和数据分析的基础。
用ndarray进行存储:
import numpy as np
# 创建一个一维数组
a = np.array([1, 2, 3, 4, 5])
# 创建一个二维数组
b = np.array([[1, 2, 3], [4, 5, 6]])
# 创建一个三维数组
c = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
a, b, c
输出结果为:
# 执行a, b, c后,其输出结果为
(array([1, 2, 3, 4, 5]),
array([[1, 2, 3],
[4, 5, 6]]),
array([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]]))
使用NumPy的ndarray与Python的列表嵌套存储相比,是存在优势的,下面我们来进行验证。
1.3 ndarray与Python原生list运算效率对比
运行下面的代码:
import random
import time
import numpy as np
a = []
for i in range(1000000000):
a.append(random.random())
# 通过%time查看当前行的代码运行一次花费的时间
%time sum1=sum(a)
b = np.array(a)
%time sum2=np.sum(b)
输出结果为:
CPU times: total: 46.9 ms
Wall time: 56.6 ms
CPU times: total: 15.6 ms
Wall time: 15.6 ms
由数据对比可知,ndarray的计算速度要快上不少,节省了不少时间。
1.4 ndarray的优势
1.4.1 内存存储方式
ndarray在存储数据的时候,数据与数据的地址都是连续的,这样就给使得批量操作数组元素时速度更快。这是因为ndarray中的所有元素的类型都是相同的;
而Python列表中的元素类型是任意的,所以ndarray在存储元素时内存可以连续,而python原生list就只能通过寻址方式找到下一个元素,这虽然也导致了在通用性能方面Numpy的ndarray不及Python原生list,但在科学计算中,Numpy的ndarray就可以省掉很多循环语句,代码使用方面比Python原生list简单的多。
1.4.2 ndarray支持并行化运算(向量化运算)
Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制,所以,其效率远高于纯Python代码。
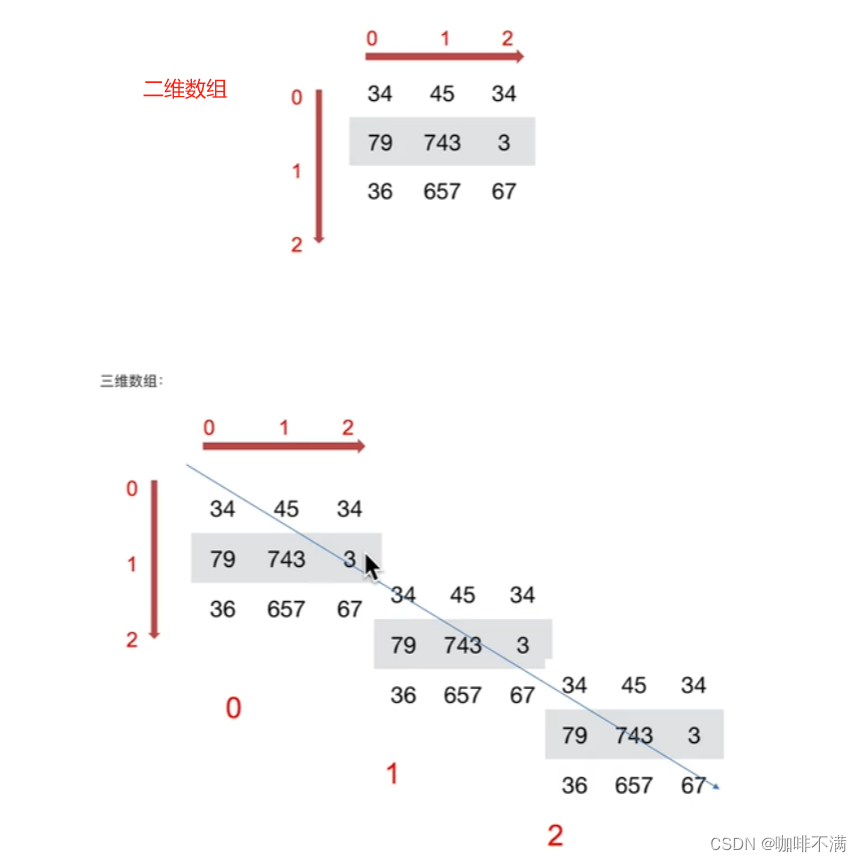
2. N维数组-ndarray
2.1 ndarray的属性
数组属性反映了数组本身固有的信息。
| 属性名字 | 属性解释 |
|---|---|
| ndarray.shape | 数组维度的元组 |
| ndarray.ndim | 数组维数 |
| ndarray.size | 数组中的元素数量 |
| ndarray.itemsize | 一个数组元素的长度 |
| ndarray.dtype | 数组元素的类型 |
当然也可以直接通过查看文档了解更多的信息:
import numpy as np
help(np.ndarray)
class ndarray(builtins.object)
ndarray(shape, dtype=float, buffer=None, offset=0,strides=None, order=None)
An array object represents a multidimensional, homogeneous array of fixed-size items. An associated data-type object describes the format of each element in the array (its byte-order, how many bytes it occupies in memory, whether it is an integer, a floating point number, or something else, etc.)
Arrays should be constructed usingarray,zerosorempty(refer to the See Also section below). The parameters given here refer to
a low-level method (ndarray(...)) for instantiating an array.
For more information, refer to thenumpymodule and examine the methods and attributes of an array.
…
2.2 ndarray的形状
通过代码来创建一些数组。
import numpy as np
array1 = np.array([[1,2,3], [4,5,6]])
array2 = np.array([1,3,5,7,9])
array3 = np.array([[[1,2], [3,4]], [[5,6], [7,8]]])
array1.shape
array2.shape
array3.shape
输出结果为:
(2, 3) # 二维数组
(5,) # 一维数组
(2, 2, 2) # 三维维数组
3. 基本操作
3.1 生成数组的方法
3.1.1 生成0和1的数组
- np.ones(shape, dtype)
- np.ones_like(a, dtype)
- np.zeros(shape, dtype)
- np.zeros_like(a, dtype)
import numpy as np
ones = np.ones([4, 8]) # 生成4行8列的全1矩阵
ones
输出结果为:
array([[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.]])
zeros = np.zeros_like(ones) # 将全1矩阵改为同行同列的全0矩阵
zeros
输出结果为:
array([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
3.1.2 从现有的数组中生成
下面的代码示例:
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
arr
输出结果为:
array([[1, 2, 3],
[4, 5, 6]])
另外,还有一种asarray方法来创建数组。
arr = np.array([[1, 2, 3], [4, 5, 6]])
arr
# 输出结果为
# array([[1, 2, 3],
# [4, 5, 6]])
arr1 = np.array(arr) # 深拷贝
arr1
# 输出结果为
# array([[1, 2, 3],
# [4, 5, 6]])
arr2 = np.asarray(arr) # 浅拷贝
arr2
# 输出结果为
# array([[1, 2, 3],
# [4, 5, 6]])
# 修改原数组中的值
arr[0, 0] = 10
print(arr[0, 0])
# 输出结果为
# 10
arr
# 输出结果为
# array([[10, 2, 3],
# [ 4, 5, 6]])
arr1
# 输出结果为
# array([[1, 2, 3],
# [4, 5, 6]])
arr2
# 输出结果为
# array([[10, 2, 3],
# [ 4, 5, 6]])
3.1.2 生成固定范围内的数组
3.1.2.1 np.linspace(start, stop, num, endpoint)
- 创建等差数组——指定数量
- 参数
- start:序列的起始值
- stop:序列的终止值
- num:要生成等间隔样例数量,默认为50
- endpoint:数列中是否包含stop值,默认为true
np.linspace(0, 100, 11)
# 执行结果为
array([ 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., 100.])
3.1.2.2 np.arrage(start, stop, step, dtype)
- 创建等差数组——指定步长
- 参数:
- step:步长,默认值为1
np.arange(10, 100, 2)
# 执行结果为
# array([10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42,
# 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76,
# 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98])
3.1.2.3 np.logspace(start, stop, num)
- 创建等比数列
- 参数
- num:要生成等比数列的数量,默认为50
# 生成10^x
np.logspace(0, 2, 3)
# 执行结果为
# array([ 1., 10., 100.])
3.1.2 生成随机数组
3.1.2.1 正态分布
- np.random.randn(d0, d1, … dn)
- 功能:从标准正态分布中返回一个或多个样本值
- np.random.normal(loc=0.0, scale=1.0, size=None)
- loc:float
此概率分布的均值(对应着整个分布的中心centre) - scale: float
此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高) - size: int or tuple of ints
输出的shape,默认为None,只输出一个值
- loc:float
- np.random.standard normal(size=None)返回指定形状的标准正态分布的数组,
代码展示如下:
import numpy as np
import matplotlib.pyplot as plt
# 生成均值为1.75, 标准差为1的正态分布数据,100000000个
x1 = np.random.normal(1.75, 1, 100000000)
# 1. 绘制画布
plt.figure(figsize=(20, 8), dpi=1000)
# 2. 绘制图像
plt.hist(x1, 1000)
# 3. 展示图像
plt.show()
下面是绘制的图像
还有另外一种参数
stock_change = np.random.normal(0, 1, [4, 5])
stock_change
# 执行结果为
# array([[-0.07343123, 0.85828909, -0.53859673, -0.33504883, 0.92722191],
# [ 1.20410613, -0.17707847, -0.22810201, 2.06332424, 0.62370079],
# [-0.03909452, -0.89459127, -1.29837664, -1.16698214, -1.47110174],
# [-0.31251457, 1.40358518, -0.09564691, 0.81625364, -0.30557632]])
3.1.2.2 均匀分布
- np.random.rand(d0, d1,… dn)
- 返回[0.0,1.0)内的一组均匀分布的数。
- np.random.uniform(low=0.0,high=1.0,size=None)
- 功能:从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high.
- 参数介绍:
- low:采样下界,filoat类型,默认值为0;
- high:采样上界,float类型,默认值为1;
- size:输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k),则输出mnk个样本,缺省时输出1个值。
- 返回值:ndarray类型,其形状和参数size中描述一致。
- np.random.randint(low, high=None, size=None, dtype=“I”)
- 从一个均匀分布中随机采样,生成一个整数或N维整数数组。
- 取数范围:若high不为None时,取[low,high)之间随机整数,否则取值[0,low)之间随机整数。
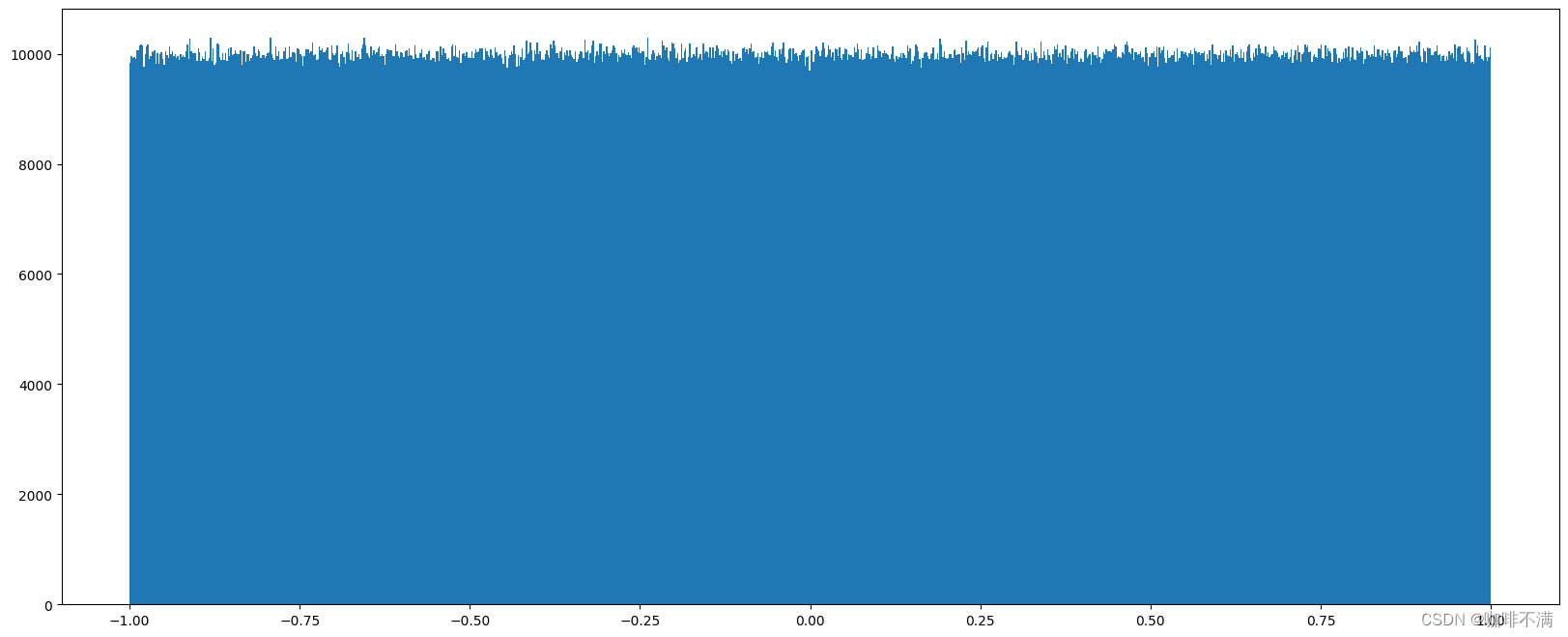
代码展示如下:
import numpy as np
import matplotlib.pyplot as plt
x2 = np.random.uniform(-1, 1, 10000000)
# 1. 绘制画布
plt.figure(figsize=(10, 10), dpi=100)
# 2. 绘制图像
plt.hist(x1, bins = 1000)
# 3. 展示图像
plt.show()
下面是绘制的图像:
3.2 数组的索引、切片
-
一维、二维、三维的数组如何索引?
- 直接进行索引,切片。
- 对象[:,:」- 先行后列
-
二维数组索引方式:
import numpy as np
random_data = np.random.normal(0, 1, [4, 5])
random_data
# 执行结果为
# array([[-6.91170397e-01, 1.05658456e-01, -5.89351993e-01,
# -2.21543309e-01, 1.06325249e+00],
# [-3.19562934e-01, -3.60183322e-01, 4.43128156e-01,
# -3.43462327e-01, 1.53589554e+00],
# [ 1.14135674e-01, -8.19353230e-02, 1.48187923e+00,
# 8.48903981e-01, -2.72218976e+00],
# [ 1.17056407e+00, -5.65536429e-01, 1.12495627e+00,
# 1.31499650e-01, -1.68119945e-03]])
random_data[0, 0:3]
# 执行结果为
# array([-0.6911704 , 0.10565846, -0.58935199])
- 三维数组索引方式
three_dimensional_array = np.array(
[[[1, 2, 3], [4, 5, 6]],[ [5, 6 , 7], [10, 11, 12]]]
)
three_dimensional_array
# 执行结果为
# array([[[ 1, 2, 3],
# [ 4, 5, 6]],
#
# [[ 5, 6, 7],
# [10, 11, 12]]])
# 想要获取12这个数字
three_dimensional_array[1, 1, 2]
# 执行结果为
# 12
3.3 数组形状修改
3.3.1 ndarray.reshape(shape, order)
- 返回一个具有相同的数据域,但shape不一样的视图
- 行、列不进行互换
stock_change
# 执行结果
# array([[ 0.44339819, 1.54955448, 1.07050935, 0.48085666, 1.18180945],
# [-0.21080738, -1.33541332, 0.65786619, -1.34373628, 0.5230377 ],
# [ 0.27264498, 0.57616681, -0.49485241, -0.90567332, 0.22385249],
# [-0.73744206, -0.24905045, -1.37285789, -0.47820998, 0.36067824]])
stock_change.reshape([5, 4])
# 执行结果
# array([[ 0.44339819, 1.54955448, 1.07050935, 0.48085666],
# [ 1.18180945, -0.21080738, -1.33541332, 0.65786619],
# [-1.34373628, 0.5230377 , 0.27264498, 0.57616681],
# [-0.49485241, -0.90567332, 0.22385249, -0.73744206],
# [-0.24905045, -1.37285789, -0.47820998, 0.36067824]])
stock_change.reshape([-1, 2])
# 执行结果
# array([[ 0.44339819, 1.54955448],
# [ 1.07050935, 0.48085666],
# [ 1.18180945, -0.21080738],
# [-1.33541332, 0.65786619],
# [-1.34373628, 0.5230377 ],
# [ 0.27264498, 0.57616681],
# [-0.49485241, -0.90567332],
# [ 0.22385249, -0.73744206],
# [-0.24905045, -1.37285789],
# [-0.47820998, 0.36067824]])
# 当不确定要改为多少行或是多少列时,如果分割不均匀会报错 20/3 = 2
# stock_change.reshape([3, -1]) # 报错
3.3.2 ndarray.resize(new_shape)
- 修改数组本身的形状(需要保持元素个数前后相同)
- 行、列不进行互换
stock_change.resize([10, 2])
stock_change
# 执行结果
# array([[ 0.44339819, 1.54955448],
# [ 1.07050935, 0.48085666],
# [ 1.18180945, -0.21080738],
# [-1.33541332, 0.65786619],
# [-1.34373628, 0.5230377 ],
# [ 0.27264498, 0.57616681],
# [-0.49485241, -0.90567332],
# [ 0.22385249, -0.73744206],
# [-0.24905045, -1.37285789],
# [-0.47820998, 0.36067824]])
3.3.3 ndarray.T
- 数组的转置
- 将数组的行、列进行互换
stock_change.T # 上述例子可知,其形状为10*2
# 转置后
# array([[ 0.44339819, 1.07050935, 1.18180945, -1.33541332, -1.34373628,
# 0.27264498, -0.49485241, 0.22385249, -0.24905045, -0.47820998],
#
# [ 1.54955448, 0.48085666, -0.21080738, 0.65786619, 0.5230377 ,
# 0.57616681, -0.90567332, -0.73744206, -1.37285789, 0.36067824]])
3.4 数组类型修改
stock_change.astype(np.int64)
# 执行结果
# array([[ 0, 1],
# [ 1, 0],
# [ 1, 0],
# [-1, 0],
# [-1, 0],
# [ 0, 0],
# [ 0, 0],
# [ 0, 0],
# [ 0, -1],
# [ 0, 0]], dtype=int64)
# 可以看到,数组由小数变为了整数
3.5 数组的去重
temp = np.array([[1, 2, 3, 4], [4, 5, 6, 7]])
temp
# 执行结果
# array([[1, 2, 3, 4],
# [4, 5, 6, 7]])
temp = np.unique(temp)
temp
# 执行结果
# array([1, 2, 3, 4, 5, 6, 7])
# 可以看到,相同的元素3和4只保留了一份
以上是我对NumPy的ndarray基础知识的学习总结,如有不足请批评指正,希望一起进步!!!















 187
187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









