






grep命令介绍
命令介绍
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来(匹配到的标红grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
关于egrep:在此命令后跟的模板可以进行正则表达式的匹配
#1.查看源文本
[root@blackstone test]# cat grep_basic
aaaaaaaa
bbbbbbbbbbbbbb
AAAAAAAaaaaaa
asczxcasBCXSDASCZADAD
SADASCZXCASD
#2.过滤包含字符b的行以及下两行
[root@blackstone test]# grep -A2 b grep_basic
bbbbbbbbbbbbbb
AAAAAAAaaaaaa
asczxcasBCXSDASCZADAD
#3.过滤包含字符b的行以及前1行
[root@blackstone test]# grep -B1 b grep_basic
aaaaaaaa
bbbbbbbbbbbbbb
#4.过滤包含b的行以及其上下两行
[root@blackstone test]# grep -C1 b grep_basic
aaaaaaaa
bbbbbbbbbbbbbb
AAAAAAAaaaaaa
#5.统计匹配的行数
[root@blackstone test]# grep -c aaa grep_basic
2
#6.使用e添加或或关系匹配的条目,即就是同时对AAA或者bbb进行筛选
[root@blackstone test]# grep -e AAA -e bbb grep_basic
bbbbbbbbbbbbbb
AAAAAAAaaaaaa
#7.筛选的同时显示行号并忽略大小写
[root@blackstone test]# grep -in b grep_basic
2:bbbbbbbbbbbbbb
4:asczxcasBCXSDASCZADAD
#8.筛选过程仅显示匹配到的部分
[root@blackstone test]# grep -o ADA grep_basic
ADA
ADA
#9.无输出筛选---主要用于shell编程中对返回值的判断确认信息的存在性
[root@blackstone test]# grep -q aa grep_basic
#10.进行取反显示,即就是匹配到的行不显示
[root@blackstone test]# grep -v aa grep_basic
bbbbbbbbbbbbbb
asczxcasBCXSDASCZADAD
SADASCZXCASD
#11.严格匹配字符,要求行内字符必须和模式完全一致
[root@blackstone test]# grep -w aa grep_basic
[root@blackstone test]# grep -w aaa grep_basic
[root@blackstone test]# grep -w aaaaaaaa grep_basic
aaaaaaaa
#12.使用文件进行匹配---通过以下的操作我们可以得知,文件内容匹配是默认的匹配方式
[root@blackstone test]# cat a.txt
aaaaaaaa
[root@blackstone test]# grep -f a.txt grep_basic
aaaaaaaa
[root@blackstone test]# vim a.txt
[root@blackstone test]# grep -f a.txt grep_basic
aaaaaaaa
AAAAAAAaaaaaa
命令参数
常用参数已加粗
-A<显示行数>:除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-B<显示行数>:除了显示符合样式的那一行之外,并显示该行之前的内容。
-C<显示行数>:除了显示符合样式的那一行之外,并显示该行之前后的内容。
-c:统计匹配的行数
-e :实现多个选项间的逻辑or 关系
-E:扩展的正则表达式
-f FILE:从FILE获取PATTERN匹配
-F :相当于fgrep
-i --ignore-case #忽略字符大小写的差别。
-n:显示匹配的行号
-o:仅显示匹配到的字符串
-q: 静默模式,不输出任何信息
-s:不显示错误信息。
-v:显示不被pattern 匹配到的行,相当于[^] 反向匹配
-w :匹配 整个单词
#查看源字符文件
[root@blackstone test]# cat grep_regular
abxc
123456
//a
[]
,.;'[]
#1.使用.匹配字符,由于.匹配任意字符,故可以到文本中的文字均被标红
[root@blackstone test]# grep . grep_regular
#查看原文本
[root@blackstone test]# cat grep_01
ggle
gogle
google
gooooooooooooooooooooooooooogle
gagle
#1.过滤字符中的o出现次数为0次或多次
[root@blackstone test]# grep "g[o]*gle" grep_01
ggle
gogle
google
gooooooooooooooooooooooooooogle
#2.过滤字符o的次数大于等于1
[root@blackstone test]# grep "g[o].*gle" grep_01
gogle
google
gooooooooooooooooooooooooooogle
#3.问号匹配0/1次前置字符,这里由于在grep中执行故需要加\进行转义
[root@blackstone test]# grep "g[o]\?gle" grep_01
ggle
gogle
#4.使用+匹配前置字符大于等于1次,同样使用\进行转义
[root@blackstone test]# grep "g[o]\+gle" grep_01
gogle
google
gooooooooooooooooooooooooooogle
#5.匹配次数区间为[1,2]其中{}符号添加\进行转义
[root@blackstone test]# grep "g[o]\{1,2\}gle" grep_01
gogle
google
#6.使用-E或者egrep直接支持正则进行匹配
[root@blackstone test]# grep -E "g[o]{10,}gle" grep_01
gooooooooooooooooooooooooooogle
[root@blackstone test]# egrep "g[o]{10,}gle" grep_01
gooooooooooooooooooooooooooogle
[root@blackstone test]# egrep "g[o]{,10}gle" grep_01
ggle
gogle
google
#查看源字符文件
[root@blackstone test]# cat grep_regular
abxc
123456
//a
[]
,.;'[]
[root@blackstone test]# cat grep_03
hello world hello world
hiiiii world hiii world
hello world heiii wwwww
#1.匹配含有he的行
[root@blackstone test]# grep "\(he\)" grep_03
#2.对he结果进行分组,在后续的匹配中进行引用,形成包夹型的匹配字符
[root@blackstone test]# grep "\(he\).*\1" grep_03
#3.设置多个分组并向后引用第二组进行字符匹配
[root@blackstone test]# grep "\(he\).*\(wo\).*\2" grep_03
echo命令——输出
echo 命令主要用来显示字符串信息。
echo 【选项] 字符串
常用选项:
echo -n 表示不换行输出
echo -e 表示输出转义符(字符串必须加引号,转义符才生效常用的转义符(转义符需结合-e同时使用,且字符串必须加引号):
| 选项 | 作用 |
|---|---|
| \n | 插入换行符,输出换行 |
| \r | 光标移至行首,并且不换行 |
| \s | 当前shell的名称,如bash |
| \t | 插入Tab键(即制表符) |
| \f | 换行,但光标仍停留在原处 |
| \ \ | 表示插入\本身 |
| \b | 插入退格键,表示退格,不显示前一个字符 |
| \c | 抑制更多的输出或不换行 |
[root@yuji ~]# echo "helloworld"
helloworld
[root@yuji ~]# echo -e "hello\nworld" //插入换行符,即输出换行
hello
world
[root@yuji ~]# echo -e "hello\tworld" //插入制表符
hello world
[root@yuji ~]# echo -e "hello\bworld" //退格一次
hellworld
[root@yuji ~]# echo -e "hello\b\bworld" //退格两次
helworld
[root@yuji ~]# echo -e "hello\world" //插入\本身
hello\world
[root@yuji ~]# echo -n "helloworld" //内容结尾不会携带换行符
helloworld[root@yuji ~]#
[root@yuji ~]# echo -e "helloworld\c" //内容结尾不会携带换行符
helloworld[root@yuji ~]#
sort命令——排序
sort将文件的每一行作为一个单位相互比较,比较原则是从首字符向后依次按ASCII码进行比较,最后将它们按升序输出。(以行为单位来排序输出)
sort [选项] 参数
cat file | sort 选项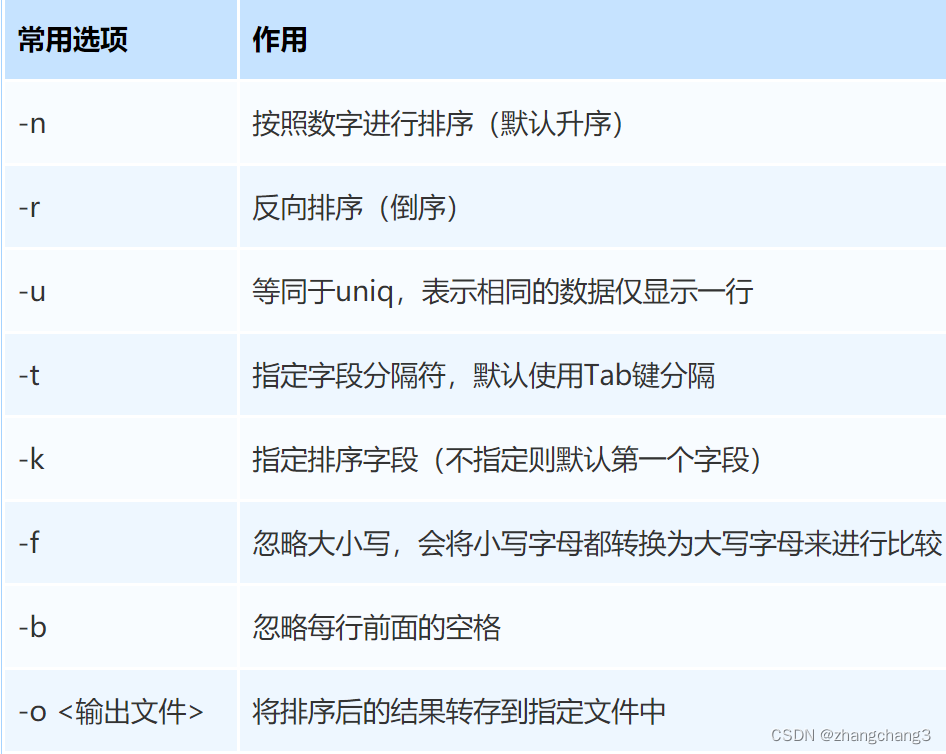
uniq命令——去重
uniq命令用于报告或者忽略文件中连续的重复行,常与sort命令结合使用。
uniq [选项] 参数
cat file | uniq 选项常用选项:
| 常用选项 | 作用 |
|---|---|
| -c | 统计连续重复的行的次数,并且合并重复的行 |
| -u | 显示仅出现一次的行(包括不连续的重复行) |
| -d | 仅显示重复出现的行(必须是连续的重复行 |
[root@yuji ~]# cat 2.txt
1
2
33
33
33
444
444
1
33
2
444
[root@yuji ~]# uniq 2.txt
1
2
33
444
1
33
2
444 [root@yuji ~]# cat 3.txt
1
2
5
6
33
33
33
444
444
1
33
2
444
[root@yuji ~]# uniq -u 3.txt
1
2
5
6
1
33
2
444
tr命令——删除、替换、压缩
tr命令常用来对来自标准输入的字符进行替换、压缩和删除。
cat file | tr [选项] 参数常用选项:
| 选项 | 作用 |
|---|---|
| -c | 保留字符集1的字符,其他字符包括换行符\n用字符集2替换 |
| -d | 删除所有属于字符集1的字符 |
| -s | 将连续重复的字符串压缩成一个 |
| -t | 字符集2 替换 字符集1,不加选项效果相同 |
常用参数
| 参数 | 说明 |
|---|---|
| 字符集1 | 指定要转换或删除的原字符集。当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集。但执行删除操作时,不需要参数“字符集2” |
| 字符集2 | 指定要转换成的目标字符集 |
tr命令的一般使用
[root@yuji ~]# echo abc | tr 'a-z' 'A-Z' //将所有小写字母替换为大写
ABC
[root@yuji ~]# echo abc | tr 'a' 'A' //将小写a替换为大写A
Abc
[root@yuji ~]# echo abc | tr -t 'a' 'A' //将小写a替换为大写A
Abc
[root@yuji ~]# echo "192.168.80.10" | tr '.' ' ' //将.替换为空格
192 168 80 10
[root@yuji ~]# echo -e "abc\ncba\nab"
abc
cba
ab
[root@yuji ~]# echo -e "abc\ncba\nab" | tr -c "ab" "0"
ab000ba0ab0[root@yuji ~]#
[root@yuji ~]# echo -e "abc\ncba\nab" | tr -c "ab\n" "0"
ab0
0ba
ab
[root@yuji ~]# echo "hhhi woooorld"
hhhi woooorld
[root@yuji ~]# echo "hhhi woooorld" | tr -s "h"
hi woooorld
[root@yuji ~]# echo "hhhi woooorld" | tr -s "ho"
hi world
[root@yuji ~]# echo "hhhi woooorld" | tr -s "ho" "z"
zi wzrld
[root@yuji ~]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@yuji ~]# echo $PATH | tr ":" "\n"
/usr/local/sbin
/usr/local/bin
/usr/sbin
/usr/bin
/root/bin
cut命令——截取字段或字符串
用于显示行中的指定部分,删除文件中指定字段。
cut [选项] 参数
cat file | cut [选项] 参数常用选项:
| 选项 | 作用 |
|---|---|
| -d | 指定分隔符(默认分隔符为Tab) |
| -f n | 按字段进行截取。指定第n个字段;1-3表示从第1个字段到第3个字段;1,4,7表示第1、第4、第7个字段 |
| -b | 以字节为单位进行截取 |
| -c | 以字符为单位进行截取 |
| –complement | 排除所指定的字段 |
| –output-delimiter | 更改输出内容的分隔符 |
截取字符串的常用方法:
1.${i:起始下标值:截取长度}
#i是变量,字符的下标值从0开始。例如 ${i:0:2}
2.echo $i | cut -c 1-3
#-c表示按字符截取,字符下标值从1开始,起始位置-终止位置。1是起始位置,3是终止位置。
3.expr substr $i 1 3
#下标值从1开始。1代表起始位置,3代表截取的字符长度
[root@yuji ~]# i=123456789
[root@yuji ~]# echo ${i:2:4} //从下标值为2的字符开始截取,共截取4个字符
3456
[root@yuji ~]# echo $i | cut -c 3-6 //截取第3到第6个字符
3456
[root@yuji ~]# expr substr $i 3 4 //从第3个字符开始截取,共截取4个字符
3456
split命令——拆分文件
split命令用于在Linux下将大文件拆分为若干小文件。
split 选项 参数 原始文件 拆分后文件名前缀常用选项:
| 选项 | 作用 |
|---|---|
| -l | 指定行数 |
| -b | 指定大小 |
eval命令——扫描命令2次
命令字前加上eval,shell会在执行命令之前扫描它两次,eval命令首先会先扫描命令行进行所有的置换,然后再执行命令,该命令适用于那些一次扫描无法实现功能的变量,该命令会对变量进行两次扫描。
[root@yuji ~]# echo "hello world">file
[root@yuji ~]# cat file
hello world
[root@yuji ~]# myfile="cat file"
[root@yuji ~]# echo $myfile //输出变量myfile的值
cat file
[root@yuji ~]# eval $myfile //扫描命令2次,先将myfile置换成"cat file",之后执行"cat file"
hello world
[root@yuji ~]# cat demo.sh
#!/bin/bash
eval echo $$# //先将$$#置换成$5(即\$置换成$,$#置换成参数个数5),之后执行“echo $5”,即输出第5个位置参数的值
[root@yuji ~]# bash demo.sh 1 2 3 4 5
5















 1335
1335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









