









字符串基础算法
Trie
字典树是众多字符串算法中最简单但用途很广泛的算法,所以说性价比很高嘛~
字典树的用途主要是对于源字符很多且有公共前缀的一些字符串建树,在查询时可以快速判断目标是否存在与源字典里。
模板
封装到struct里啦
struct Trie
{
int ch[MAXNODE][SIGMASIZE];//ch[i][j]表示节点i的下一个字符是j的节点标号
bool val[MAXNODE];
int sz;
Trie(){sz=1;memset(ch[0],0,sizeof(ch[0]));}
int idx(char c){return c-'A';}
void insert(char * s)//向字典树中插入
{
int u=0,n=strlen(s);
for(int i=0;i<n;i++)
{
int c=idx(s[i]);
if(!ch[u][c])
{
memset(ch[sz],0,sizeof(ch[sz]));
val[sz]=0;
ch[u][c]=sz++;
}
u=ch[u][c];
}
val[u]=true;
}
bool search(char * s)//查询
{
int u=0,n=strlen(s);
for(int i=0;i<n;i++)
{
int c=idx(s[i]);
u=ch[u][c];
if((i==n-1)&&val[u])
return true;
}
return false;
}
};应用
字典树的模板是十分好理解的,如果不跟其它字符串算法结合字典树应用也很水。
一道很明显的动规题,代码不难写,主要是想到用字典树优化动规
状态转移方程:
#include<cstring>
#include<vector>
using namespace std;
const int maxnode = 4000 * 100 + 10;
const int sigma_size = 26;
// 字母表为全体小写字母的Trie
struct Trie
{
int ch[maxnode][sigma_size];
int val[maxnode];
int sz; // 结点总数
void clear() { sz = 1; memset(ch[0], 0, sizeof(ch[0])); } // 初始时只有一个根结点
int idx(char c) { return c - 'a'; } // 字符c的编号
// 插入字符串s,附加信息为v。注意v必须非0,因为0代表“本结点不是单词结点”
void insert(const char *s, int v)
{
int u = 0, n = strlen(s);
for(int i = 0; i < n; i++)
{
int c = idx(s[i]);
if(!ch[u][c]) // 结点不存在
{
memset(ch[sz], 0, sizeof(ch[sz]));
val[sz] = 0; // 中间结点的附加信息为0
ch[u][c] = sz++; // 新建结点
}
u = ch[u][c]; // 往下走
}
val[u] = v; // 字符串的最后一个字符的附加信息为v
}
// 找字符串s的长度不超过len的前缀
void find_prefixes(const char *s, int len, vector<int>& ans)
{
int u = 0;
for(int i = 0; i < len; i++)
{
if(s[i] == '\0') break;
int c = idx(s[i]);
if(!ch[u][c]) break;
u = ch[u][c];
if(val[u] != 0) ans.push_back(val[u]); // 找到一个前缀
}
}
};
#include<cstdio>
const int maxl = 300000 + 10; // 文本串最大长度
const int maxw = 4000 + 10; // 单词最大个数
const int maxwl = 100 + 10; // 每个单词最大长度
const int MOD = 20071027;
int d[maxl], len[maxw], S;
char text[maxl], word[maxwl];
Trie trie;
int main()
{
int kase = 1;
while(scanf("%s%d", text, &S) == 2)
{
trie.clear();
for(int i = 1; i <= S; i++)
{
scanf("%s", word);
len[i] = strlen(word);
trie.insert(word, i);
}
memset(d, 0, sizeof(d));
int L = strlen(text);
d[L] = 1;
for(int i = L-1; i >= 0; i--)
{
vector<int> p;
trie.find_prefixes(text+i, L-i, p);
for(int j = 0; j < p.size(); j++)
d[i] = (d[i] + d[i+len[p[j]]]) % MOD;
}
printf("Case %d: %d\n", kase++, d[0]);
}
return 0;
}KMP
KMP算法思想
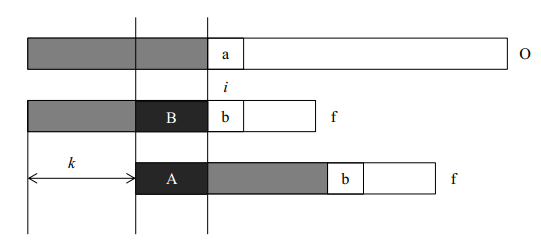
我们首先用一个图来描述kmp算法的思想。在字符串O中寻找f,当匹配到位置i时两个字符串不相等,这时我们需要将字符串f向前移动。常规方法是每次向前移动一位,但是它没有考虑前i-1位已经比较过这个事实,所以效率不高。事实上,如果我们提前计算某些信息,就有可能一次前移多位。假设我们根据已经获得的信息知道可以前移k位,我们分析移位前后的f有什么特点。我们可以得到如下的结论:
1. A段字符串是f的一个前缀。
2. B段字符串是f的一个后缀。
3. A段字符串和B段字符串相等。
所以前移k位之后,可以继续比较位置i的前提是f的前i-1个位置满足:长度为i-k-1的前缀A和后缀B相同。只有这样,我们才可以前移k位后从新的位置继续比较。
所以kmp算法的核心即是计算字符串f每一个位置之前的字符串的前缀和后缀公共部分的最大长度(不包括字符串本身,否则最大长度始终是字符串本身)。获得f每一个位置的最大公共长度之后,就可以利用该最大公共长度快速和字符串O比较。当每次比较到两个字符串的字符不同时,我们就可以根据最大公共长度将字符串f向前移动,移动位数如下:
移动位数=已匹配长度-最大公共长度
接着继续比较下一个位置。事实上,字符串f的前移只是概念上的前移,只要我们在比较的时候从最大公共长度之后比较f和O即可达到字符串f前移的目的。
next数组计算
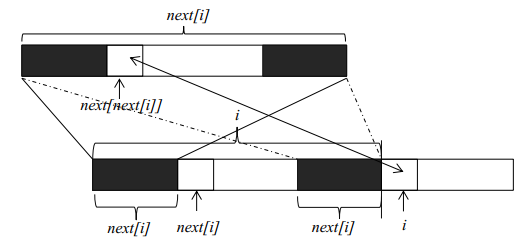
理解了kmp算法的基本原理,下一步就是要获得字符串f每一个位置的最大公共长度。这个最大公共长度在算法导论里面被记为next数组。在这里要注意一点,next数组表示的是长度,下标从1开始;但是在遍历原字符串时,下标还是从0开始。假设我们现在已经求得next[1]、next[2]、……next[i],分别表示长度为1到i的字符串的前缀和后缀最大公共长度,现在要求next[i+1]。由下图我们可以看到,如果位置i和位置next[i]处的两个字符相同(下标从零开始),则next[i+1]等于next[i]加1。如果两个位置的字符不相同,我们可以将长度为next[i]的字符串继续分割,获得其最大公共长度next[next[i]],然后再和位置i的字符比较。这是因为长度为next[i]前缀和后缀都可以分割成上部的构造,如果位置next[next[i]]和位置i的字符相同,则next[i+1]就等于next[next[i]]加1。如果不相等,就可以继续分割长度为next[next[i]]的字符串,直到字符串长度为0为止。
求next数组代码如下:
void next (char p[],int f[])
{
int m=strlen(p);
f[0]=0;f[1]=0;
for(int i=1;i<m;i++)
{
int j=f[i];//j在每次循环开始时都表示next[i]的值,同时也表示需要比较的下一个位置
while(j&&p[i]!=p[j]) j=f[j];
f[i+1]= p[i]==p[j]? j+1:0;
}
}字符串匹配
计算完成next数组之后,我们就可以利用next数组在字符串O中寻找字符串f的出现位置。匹配的代码和求next数组的代码非常相似,因为匹配的过程和求next数组的过程其实是一样的。假设现在字符串f的前i个位置都和从某个位置开始的字符串O匹配,现在比较第i+1个位置。如果第i+1个位置相同,接着比较第i+2个位置;如果第i+1个位置不同,则出现不匹配,我们依旧要将长度为i的字符串分割,获得其最大公共长度next[i],然后从next[i]继续比较两个字符串。这个过程和求next数组一致。代码如下:
void find (char t[],char p[],int f[])
{
int n=strlen(t),m=strlen(p);
next(p,f);
int j=0;
for(int i=0;i<n;i++)
{
while(j&&p[j]!=t[i]) j=f[j];
if(p[j]==t[i]) j++;//这里的j跟上次不同,代表的是主串与子串相契合的长度
if(j==m) printf("%d\n",i-m+1);
}
}输出的为位置。
AC自动机 by张澈
AC自动机应用了前面所讲的Trie和KMP的思想,它用于多个模板的模式匹配问题,在Trie的基础上加上失配边,从而建立状态转移图

函数&变量解释:
| 函数或变量 | 解释 |
|---|---|
| ch[节点编号][字符编号] | 用于建立Trie |
| f[节点编号] | 类似KMP中的next[] |
| val[节点编号] | 其值为当前节点单词编号,如此节点非单词节点,则值为0 |
| last[节点编号] | 难点!!由于此处的“字典树”中的一个节点对应的单词不止一个,也就是说找到一个单词后意味着可能有其他单词也找到了,而一个节点最多只能代表一个单词,所以需要连一条边指向其他等价的单词。注意:last作为一条边其原点不一定是单词节点,但终点一定是单词节点 |
| init() | 初始化 |
| index(char *) | 给字母标号,类似Trie |
| insert(char *,int) | 插入一个模板串,类似Trie |
| print(int) | 查找到源串中有模板串递归打印,这里由于要统计个数,此函数作用是cnt数组自加 |
| find(char *) | 传入一个源串,匹配方法几乎与KMP一致。当状态转移图建好后,遍历源串的每一个字符,沿着失配边走直至可以匹配,对于此可以匹配的节点,若是单词节点,调用print(),若不是单词节点但其失配边指向的有单词节点,也输出 |
| getFail() | 适配函数,与KMP的适配函数有异曲同工之妙,先把所得根节点下的节点入队,再循环地每次取出一个节点r,遍历其子节点u,v=f[u],如果v有一条字符与r到u的字符相同的边e,则将u指向e所指的节点s。last[u]为last[f[u]],特别地:当u为单词节点时,last[u]指向f[u] |
#include<cstring>
#include<queue>
#include<cstdio>
#include<map>
#include<string>
using namespace std;
const int SIGMA_SIZE = 26;
const int MAXNODE = 11000;
const int MAXS = 150 + 10;
map<string,int> ms;
struct ACA
{
int ch[MAXNODE][SIGMA_SIZE];
int f[MAXNODE]; // fail函数
int val[MAXNODE]; // 每个字符串的结尾结点都有一个非0的val
int last[MAXNODE]; // 输出链表的下一个结点
int cnt[MAXS];
int sz;
void init()
{
sz = 1;
memset(ch[0], 0, sizeof(ch[0]));
memset(cnt, 0, sizeof(cnt));
ms.clear();
}
// 字符c的编号
int idx(char c){return c-'a';}
// 插入字符串。v必须非0
void insert(char *s, int v)
{
int u = 0, n = strlen(s);
for(int i = 0; i < n; i++) {
int c = idx(s[i]);
if(!ch[u][c]) {
memset(ch[sz], 0, sizeof(ch[sz]));
val[sz] = 0;
ch[u][c] = sz++;
}
u = ch[u][c];
}
val[u] = v;
ms[string(s)] = v;
}
// 递归打印以结点j结尾的所有字符串
void print(int j)
{
if(j)
{
cnt[val[j]]++;
print(last[j]);
}
}
// 在T中找模板
int find(char* T)
{
int n = strlen(T);
int j = 0; // 当前结点编号,初始为根结点
for(int i = 0; i < n; i++) // 文本串当前指针
{
int c = idx(T[i]);
while(j && !ch[j][c]) j = f[j]; // 顺着细边走,直到可以匹配
j = ch[j][c];
if(val[j]) print(j);
else if(last[j]) print(last[j]); // 找到了!
}
}
// 计算fail函数
void getFail()
{
queue<int> q;
f[0] = 0;
// 初始化队列
for(int c = 0; c < SIGMA_SIZE; c++)
{
int u = ch[0][c];
if(u) { f[u] = 0; q.push(u); last[u] = 0; }
}
// 按BFS顺序计算fail
while(!q.empty())
{
int r = q.front(); q.pop();
for(int c = 0; c < SIGMA_SIZE; c++)
{
int u = ch[r][c];
if(!u) continue;
q.push(u);
int v = f[r];
while(v && !ch[v][c]) v = f[v];
f[u] = ch[v][c];
last[u] = val[f[u]] ? f[u] : last[f[u]];
}
}
}
};
ACA ac;
char text[1000001], P[151][80];
int n, T;
int main()
{
while(scanf("%d", &n) == 1 && n)
{
ac.init();
for(int i = 1; i <= n; i++)
{
scanf("%s", P[i]);
ac.insert(P[i], i);
}
ac.getFail();
scanf("%s", text);
ac.find(text);
int best = -1;
for(int i = 1; i <= n; i++)
if(ac.cnt[i] > best) best = ac.cnt[i];
printf("%d\n", best);
for(int i = 1; i <= n; i++)
if(ac.cnt[ms[string(P[i])]] == best) printf("%s\n", P[i]);
}
return 0;
}














 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









