







集合类型是Redis提供了一种内置数据类型,集合与列表相反,集合中的元素没有顺序,并且每个元素都是唯一的。
集合类型底层用散列表实现,性能非常好,同时,集合还支持数学意义上的操作:交集、并集、差集运算。
集合类型的操作
命令
sadd key member1 member2... #添加元素
srem key member1 member2... #移除元素
smembers key #获取集合中所有元素
sismember key member #判断是否为集合中的元素
sdiff key1 key2.. #计算差集
sinter key1 key2.. #计算交集
sunion key1 key2.. #计算并集
scard key #获取集合中元素的个数
#集合运算 并存储结合到新的集合
sdiffstore destination key1 key2...
sinterstore destination key1 key2...
sunionstore destination key1 key2...
srandmember key count #随机获取集合中count个元素, count为负值时可能重复获取,count为整数时不会获取重复的元素,获取个数都为|count|
spop key #从集合中弹出一个元素示例
127.0.0.1:6379> sadd s1 a b c
(integer) 3
127.0.0.1:6379> smembers s1
1) "b"
2) "c"
3) "a"
127.0.0.1:6379> srem s1 a
(integer) 1
127.0.0.1:6379> smembers s1
1) "b"
2) "c"
127.0.0.1:6379> sismember s1 b
(integer) 1
127.0.0.1:6379> scard s1
(integer) 2
127.0.0.1:6379> sadd s2 b c d
(integer) 3
127.0.0.1:6379> sadd s3 d e f
(integer) 3
127.0.0.1:6379> sdiff s1 s2 s3
(empty list or set)
127.0.0.1:6379> sinter s1 s2
1) "b"
2) "c"
127.0.0.1:6379> sunion s1 s2 s3
1) "d"
2) "b"
3) "c"
4) "f"
5) "e"
127.0.0.1:6379> sdiffstore s4 s1 s2
(integer) 0
127.0.0.1:6379> smembers s4
(empty list or set)
127.0.0.1:6379> sinterstore s5 s1 s2
(integer) 2
127.0.0.1:6379> smembers s5
1) "b"
2) "c"
127.0.0.1:6379> sunionstore s6 s1 s3 s2
(integer) 5
127.0.0.1:6379> smembers s6
1) "c"
2) "f"
3) "e"
4) "d"
5) "b"
127.0.0.1:6379> srandmember s6 2
1) "f"
2) "c"
127.0.0.1:6379> spop s6 2
1) "e"
2) "b"
127.0.0.1:6379> 实践
1)存储文章标签
文章标签的特点有:每篇文章的标签都不同,可以对单个标签进行操作,对顺序没有要求。
实现方式为:
ket = post:articleid:tags集合非常适合对标签进行单独操作,可以直接使用sadd和srem命令方便的进行操作。
另外,值得一提的是,在某些情况下,可能是对标签进行整体编辑而不是单个编辑,对于这种情况就没有发挥集合的优势,可以直接使用字符串来完成。
2)通过标签来搜索文章
在博客、社区类的网站中经常会有这样的需求:根据文章类型(标签)来查找对应的文章。
这样的需求如果用关系型数据库来实现,就需要三张表:文章表,标签表,标签文章关系表,并且需要通过一个Join查询来得到结果,当数据量比较大时,效率很低,而且不易于维护。
如果使用Redis来实现,那么只需要提供一个这样的数据结构即可:
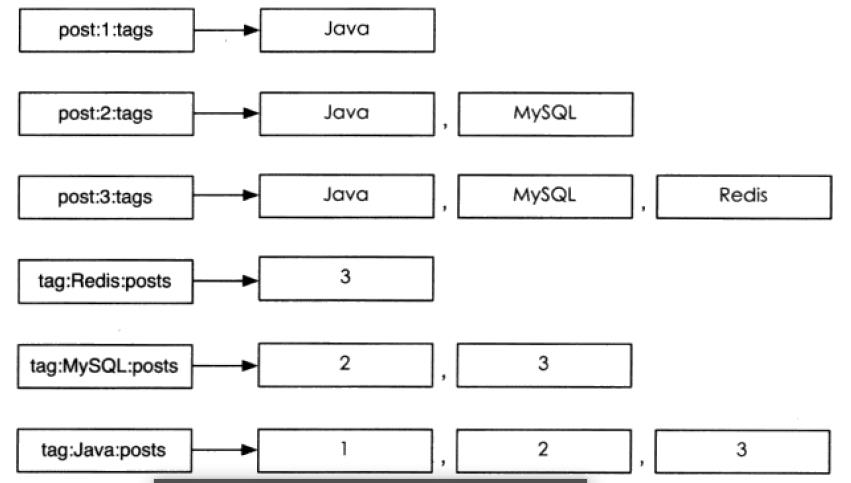
#对每一个标签提供一个这样的集合
tag:type:posts
在该集合中存储对应的文章id这样,获取指定标签的文章列表就可以这样完成:
$articleids = smember tag:redis:post
loop $articleids
$articlecontext = hget post:articleid title














 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









