







随着这几年大数据技术的迅猛发展,人们对于处理数据的要求也越来越高,由最早的MapReduce,到后来的hive、再到后来的spark,为了获取更快、更及时的结果,计算模型也在由以前的T+1的离线数据慢慢向流处理转变,比如每年双十一阿里的实时大屏,要求秒级的输出结果;再比如当我们以100迈的速度开车的时候,我们希望地图导航软件能给我们毫秒级延迟的导航信息。
那么对于已经有了storm、spark streaming这样的流处理框架之后,我们为什么还要选择Apache Flink来作为我们的流处理框架呢?
真正的流处理
低延迟
对于spark streaming来说,虽然也是一个流处理框架,但是他的底层是一个微批的模式,只是这个批足够小,使我们看起来像一个流处理,这种对于我们普通的需求来说已经足够了,但是对于我们上面所说的地图导航软件来说,我们需要的延迟是毫秒级别的,因为如果你延迟了半分钟,我可能已经开出来好远了,你给我的导航信息也没什么用了。
所以对于微批处理的框架,天生是会造成数据延迟的,flink作为一个真正的流处理框架,可以每来一个数据处理一个,实现真正的流处理、低延迟。
高吞吐
就像我们前面说的,阿里双十一的数据计算是很大的,这个时候对这么庞大的数据进行计算,就需要我们有一个支持高吞吐量的计算框架来满足更实时的需求。
多种窗口
flink本身提供了多种灵活的窗口,我们结合实际来讲讲这几个窗口的含义.
- 滚动窗口: 每隔五分钟计算当前这五分钟内的销售总额。
- 滑动窗口: 每隔五分钟计算一下前一个小时的销售总额。
- session窗口 :统计用户在他登录的这段时间里,他的访问总次数
- 全局窗口:我们可以统计自程序上线以来的一些数值。
除了时间窗口(time window),还有计数窗口(count window),count window窗口也可以有滚动和滑动窗口,比如我们每隔100个数来统计一下这100个数的平均值。
自带状态(state)
何为状态,白话讲一下,比如我们从kafka消费了一条条的数据,然后又一条条的写入了文件,这种是没有状态的计算,因为单条数据不需要依赖其前后的数据。
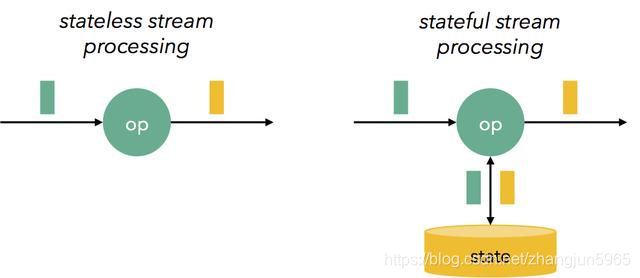
当我们要实现一个窗口计数,统计每个小时的pv数,我们可以想象,有这么一个变量,每来一个数据这个变量就加一,然后程序运行一半的时候,因为某一种原因挂了,这个时候那个变量如果是存在内存里的,就丢了,程序重启之后,我们必须重新从窗口的开始来计算,那么有没有一种机制,可以自动的帮我把这个临时变量可靠的存起来呢,这个就是flink中的状态,对于上述场景,当我们恢复程序的时候,选择从上一个checkpoint恢复,那么我们就可以继续从程序挂掉的时候继续计算,而不用从窗口的开始进行计算了。
精确一次传输语义
对于一个大型分布式系统来说,因为网络、磁盘等等原因造成程序失败是很常见的,那么当我们恢复了程序之后,如何保证数据不丢不重呢?
flink提供了Exactly-once语义来处理这个问题。
时间管理
flink提供了多种时间语义来供我们使用。
-
事件时间
也就是我们计算的时候使用数据中的时间,比如我们的程序因为某些原因挂了半个小时,当程序起来的时候我们希望程序能接着上次的继续处理,这个时候事件时间就派上用场了。
此外,对于一些告警系统,日志中的时间往往能真实的反应出有问题的时间,更有实际意义 -
处理时间
也就是flink程序当前的时间 -
摄取时间
数据进入flink程序的时间

水印
真实的生产环境中,数据的传输会经过很多流程、在这个过程中,免不了由于网络抖动等等各种原因造成数据的延迟到达、本来应该先来的数据迟到了,这种情况怎么处理呢,flink的watermark机制来帮你处理。
我们可以简单的理解为,通过设置一个可以接受的延迟时间,如果你的数据到点了没过来flink会等你几秒钟,然后等你的数据过来了再触发计算,但是由于是流处理,肯定不能无限制的等下去,对于超过了我设置的等待时间还没来的数据,那么我只能抛弃或者存到另一个流里面用别的逻辑来处理了。
复杂事件处理
先来说这么一个场景,比如说我们要监控机器的温度,连续10分钟之内有三次温度超过50度,生成一个警告,如果连续一个小时之内出现过两次上述警告,生成一个报警。
对于这么一个场景,是不是觉得普通的api程序不好做了?那好,flink的复杂事件处理(CEP)派上用场了,使用cep可以处理很多类似的复杂的场景。
其实flink还有很多好用的功能,等待我们一起去开发!
更多精彩内容,欢迎关注我的公众号【大数据技术与应用实战】,一起进步!















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









