







 南开大学和中国民航大学提出的EViT架构结合了CNN和ViT,模仿鹰眼视觉机制解决ViT的问题,如计算复杂度和局部信息缺失。实验结果显示在目标检测和实例分割任务中表现出色。
南开大学和中国民航大学提出的EViT架构结合了CNN和ViT,模仿鹰眼视觉机制解决ViT的问题,如计算复杂度和局部信息缺失。实验结果显示在目标检测和实例分割任务中表现出色。
今天跟大家分享南开大学和中国民航大学联合提出的一种新的Vison Transformer架构EViT,该结构是CNN和ViT的混合架构,在设计时参考了鹰眼成像的生理结构,在目标检测、实例分割等多个下游任务中表现优秀。

- 论文标题:EViT: An Eagle Vision Transformer with Bi-Fovea Self-Attention
- 机构:南开大学、中国民航大学等
- 论文地址:https://arxiv.org/pdf/2310.06629.pdf
- 代码地址(即将开源):https://github.com/nkusyl
- 关键词:Vision Transformer、CNN、目标检测、语义分割
1.动机
自2012年起,CNN开始主导多个计算机视觉任务,由于卷积核的感受野限制,CNN难以捕捉图像的全局信息,从而限制了CNN的进一步发展和应用。此时,在NLP领域中快速发展的transformer结构进入了计算机视觉学者的视野。与CNN相比,transformer擅长对特征的全局依赖建模,能很好地捕捉广泛的上下文信息,这种能力对图像分类、目标检测等计算机视觉任务至关重要。
vision transformer(简称ViT)先将图片转为序列,然后使用自注意力模块捕捉图像中的全局依赖,生成有效的特征表示用于图像分类。多种ViT变体先后被提出,打破了CNN在计算机视觉多个任务中的垄断地位。
然而,ViT仍面临着很多问题:
(1)与CNN相比,ViT中的自注意模块具有二次计算复杂度,在处理高分辨率图像时,这个问题尤为突出。
(2)当二维图像转换为序列时,网络的空间局部信息建模能力不足,丢失了特征之间的相对位置关系。
(3)ViT没有归纳偏置,使得网络容易过拟合。
为了解决上述问题,作者借鉴了鹰眼视觉细胞结构,设计了Bionic Eagle Vision(简称BEV)结构,以BEV结构为基础,构建了视觉骨干网络Eagle Vision Transformer(简称EViT),通过调整EViT的深度和宽度,形成了4种不同规模的骨干网络: EViT-Tiny、EViT-Small、EViT-Base、EViT-Large。
2.EViT
2.1 借鉴鹰眼视觉机制
下图中(a)为鹰眼中bi-fovea(双凹)的生理结构,图(b)为双中央凹内感光细胞的密度分布。

在生理结构上,鹰眼有两个明显的中央凹,即深中央凹和浅中央凹。深中央凹位于视网膜中心,具有高密度的感光细胞,这些细胞对于提高鹰眼睛的视觉分辨率非常重要,使鹰能够在远距离识别猎物。浅层中央凹位于视网膜外周区,感光细胞密度相对较低,但可提供更宽的视野。
虽然鹰的一只眼睛不能同时使用深中央凹和浅中央凹进行成像,但鹰的两只眼睛可以合作,在深凹和浅凹之间交替。例如,当鹰向前看时,一只眼睛的深中央凹用来精细地识别目标,同时另一只眼睛的浅中央凹用来感知周围的环境。本文参考了鹰的视觉结构作为交互机制,设计网络结构模拟鹰的视觉的深中央凹和浅中央凹,使得网络能从粗到细地捕捉目标的特征表示。
2.2 EViT总体结构
EViT是CNN和ViT的混合架构,其总体结构如下图所示:
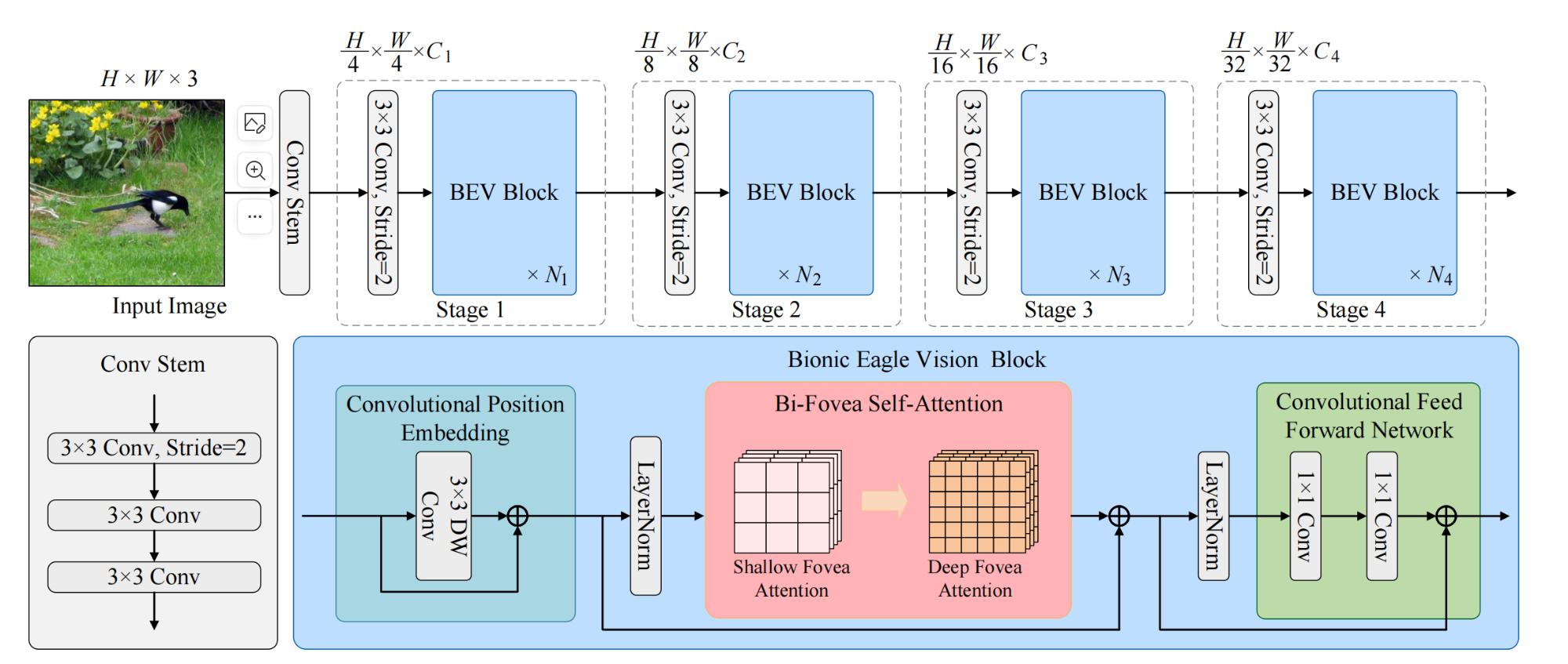
给定尺寸为 H × W × 3 H \times W \times 3 H×W×3的输入图片,首先使用Conv Stem结构得到浅层特征,Conv Stem包含3个连续的 3 × 3 3 \times 3 3×3卷积层;然后使用Bionic Eagle Vision(简称BEV)结构输出不同尺度的信息。
EViT包含4个stage,每个stage为类似的架构,包含1个步长为2的 3 × 3 3 \times 3 3×3卷积和 N i N_i Ni个BEV模块。4个stage的输出特征尺寸分别是输入图像的 1 / 4 1/4 1/4、 1 / 8 1/8 1/8、 1 / 16 1/16 1/16、 1 / 32 1/32 1/32,在特征尺度减小时,特征的通道数也在增加。
2.3 Bionic Eagle Vision(BEV)模块
BEV模块由三部分组成:
-
Convolutional Positional Embedding,简称CPE
-
Bi-Fovea Self-Attention,简称BFSA
-
Convolutional Feed-Forward Network,简称CFFN
BEV的结构可表示如下:
X = CPE ( X i n ) + X i n Y = BFSA ( LN ( X ) ) + X Z = CFFN ( LN ( Y ) ) + Y \begin{aligned} & \mathbf{X}=\operatorname{CPE}\left(\mathbf{X}_{i n}\right)+\mathbf{X}_{i n} \\ & \mathbf{Y}=\operatorname{BFSA}(\operatorname{LN}(\mathbf{X}))+\mathbf{X} \\ & \mathbf{Z}=\operatorname{CFFN}(\operatorname{LN}(\mathbf{Y}))+\mathbf{Y}\end{aligned} X=CPE(Xin)+XinY=BFSA(LN(X))+XZ=CFFN(LN(Y))+Y
上式中LN表示LayerNorm。输入特征首先经过CPE模块将特征位置信息引入到token中,然后使用BFSA做特征提取、融合token中的全局特征和细粒度特征,最后使用CFFN模块进一步增强token的特征表达。
2.4 BFSA
BFSA的结构借鉴了鹰眼视觉中的双凹特性(即鹰眼的浅中央凹可以实现粗粒度的环境感知,深中央凹可以实现细粒度的猎物识别),提取全局和细粒度的特征。BFSA包含Shallow Fovea Attention(简称SFA)和 Deep Fovea Attention(简称DFA),SFA和DFA中各包含1个Token Interaction Fusion(简称TIF)模块。
(1)Token Interaction Fusion(TIF)模块
在原始的多头自注意力机制(Multi-Head Self-Attention,简称MHSA)中,输入token(记作 X i n ′ ∈ R H × W × C \mathbf{X}_{i n}^{\prime} \in R^{H \times W \times C} Xin′∈RH×W×C)首先映射为 Q ∈ R N × D \mathbf{Q} \in R^{N \times D} Q∈RN×D、 K ∈ R N × D \mathbf{K} \in R^{N \times D} K∈RN×D和 V ∈ R N × D \mathbf{V} \in R^{N \times D} V∈RN×D,其中 N N N表示token长度, D D D表示特征维度。
作者设计了TIF模块用于减轻MHSA中的计算负担,结构如下图所示

TIF中使用了depthwise卷积和 1 × 1 1 \times 1 1×1卷积,减小在计算 K K K和 V V V时输入特征的空间尺寸。上图中的青色箭头表示使用步长为2的 3 × 3 3 \times 3 3×3 depthwise卷积进行下采样。TIF使用参数 f f f和 c c c控制输入特征的减小程度。TIF还能够实现多尺度特征token的提取和交互,这对于视觉密集预测任务尤为重要。
(2)Shallow Fovea Attention(SFA)模块和Deep Fovea Attention(DFA)模块
结构如下图所示:

将输入token记作 X i n ′ ∈ R H × W × C \mathbf{X}_{i n}^{\prime} \in R^{H \times W \times C} Xin′∈RH×W×C。
在SFA中,使用
Q
=
Linear
(
X
′
i
n
)
\mathrm{Q}=\operatorname{Linear}\left(\mathbf{X}^{\prime}{ }_{i n}\right)
Q=Linear(X′in)、
K
′
=
Linear
(
TIF
(
X
′
i
n
)
)
\mathbf{K}^{\prime}=\operatorname{Linear}\left(\operatorname{TIF}\left(\mathbf{X}^{\prime}{ }_{i n}\right)\right)
K′=Linear(TIF(X′in))、
V
′
=
Linear
(
TIF
(
X
i
n
′
)
)
\mathbf{V}^{\prime}=\operatorname{Linear} \left(\operatorname{TIF}\left(\mathbf{X}_{i n}^{\prime}\right)\right)
V′=Linear(TIF(Xin′))
对token之间的关系进行建模,得到attention map。SFA的结构为:
SFA ( X i n ′ ) = Concat ( h e a d 0 , h e a d 1 , … , h e a d h ) W o h e a d i = Attention ( Q i , K i ′ , V i ′ ) Attention ( Q , K ′ , V ′ ) = softmax ( Q K ′ T D ) V ′ \begin{gathered}\operatorname{SFA}\left(\mathbf{X}_{i n}^{\prime}\right)=\operatorname{Concat}\left(\mathbf{h e a d}_0, \mathbf { head }_1, \ldots, \mathbf { head }_h\right) \mathbf{W}^o \\ \mathbf{head}_i=\operatorname{Attention}\left(\mathbf{Q}_i, \mathbf{K}_i^{\prime}, \mathbf{V}_i^{\prime}\right) \\ \operatorname{Attention}\left(\mathbf{Q}, \mathbf{K}^{\prime}, \mathbf{V}^{\prime}\right)=\operatorname{softmax}\left(\frac{\mathbf{Q K}^{\prime T}}{\sqrt{D}}\right) \mathbf{V}^{\prime}\end{gathered} SFA(Xin′)=Concat(head0,head1,…,headh)Woheadi=Attention(Qi,Ki′,Vi′)Attention(Q,K′,V′)=softmax(DQK′T)V′
上式中 h e a d i ∈ R N × D h \mathbf{head}_i \in R^{N \times \frac{D}{h}} headi∈RN×hD表示第 i i i个head的输出特征。
DFA的结构与SFA基本相同,只有输入端与之不同。作者在DFA的输入端设计了 Local Information Awareness(简称LIA)模块,LIA模块由 1 × 1 1 \times 1 1×1卷积和 3 × 3 3 \times 3 3×3卷积组成,并使用了残差连接,LIA以一种互补的方式结合了CNN的局部连接和ViT的全局上下文。SFA的输出特征和 X i n ′ ∈ R H × W × C \mathbf{X}_{i n}^{\prime} \in R^{H \times W \times C} Xin′∈RH×W×C作为LIA的输入,DFA的输入信息 X i n ′ ′ \mathbf{X}_{i n}^{\prime \prime} Xin′′包含SFA的输出和LIA的输出,表示如下:
X i n ′ ′ = Conv ( SFA ( X i n ′ ) + LIA ( X i n ′ + SFA ( X i n ′ ) ) ) \mathbf{X}_{i n}^{\prime \prime}=\operatorname{Conv}\left(\operatorname{SFA}\left(\mathbf{X}_{i n}^{\prime}\right)+\operatorname{LIA}\left(\mathbf{X}_{i n}^{\prime}+\operatorname{SFA}\left(\mathbf{X}_{i n}^{\prime}\right)\right)\right) Xin′′=Conv(SFA(Xin′)+LIA(Xin′+SFA(Xin′)))
SFA和DFA的输出进行融合得到 Out \operatorname{Out} Out作为后续模块的输入,表示如下:
Out = Concat ( SFA ( X i n ′ ) + DFA ( X ′ ′ i n ) ) \operatorname{Out} =\operatorname{Concat}\left(\operatorname{SFA}\left(\mathbf{X}_{i n}^{\prime}\right)+\operatorname{DFA}\left(\mathbf{X}^{\prime \prime}{ }_{i n}\right)\right) Out=Concat(SFA(Xin′)+DFA(X′′in))
SFA和DFA模拟了鹰眼的浅中央凹和深中央凹的功能。本文使用SFA对token之间的全局依赖进行建模,使用DFA捕获目标的细粒度特征表示。LIA建立了SFA和DFA之间的联系,为BFSA引入了归纳偏置,以一种优雅的方式实现了ViT的全局依赖性和卷积的局部表示的互补融合。
2.5 EViT不同规模的架构
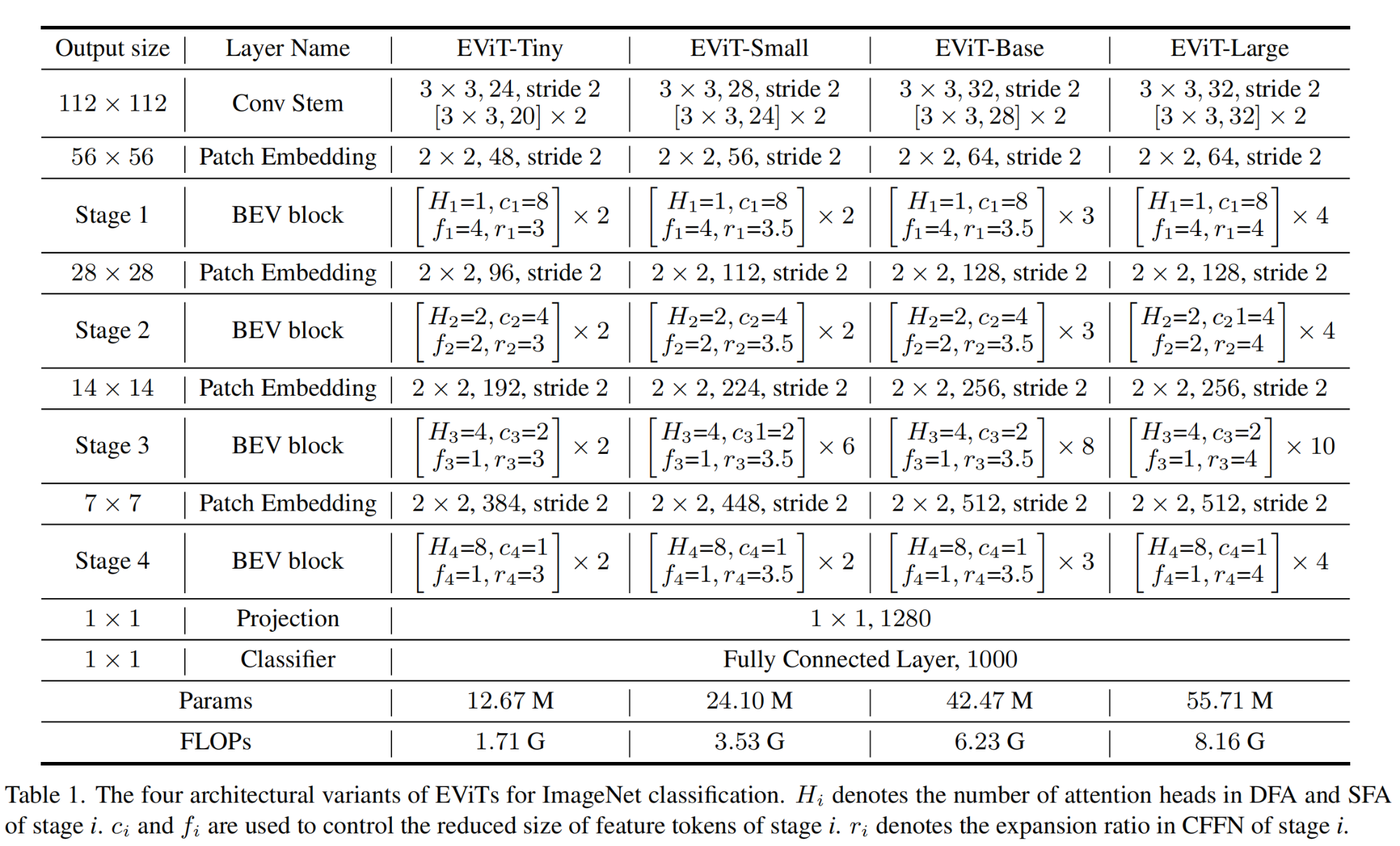
为便于表示,上表中4个结构的输入图片分辨率为 224 × 224 224 \times 224 224×224,作者在实际使用时,EViT-Tiny、EViT-Small、EViT-Base、EViT-Large的输入图片分辨率为别为 160 × 160 160 \times 160 160×160、 192 × 192 192 \times 192 192×192、 224 × 224 224 \times 224 224×224、$256 \times 256$。
3.实验
(1)图像分类
实验设置:

实验结果:

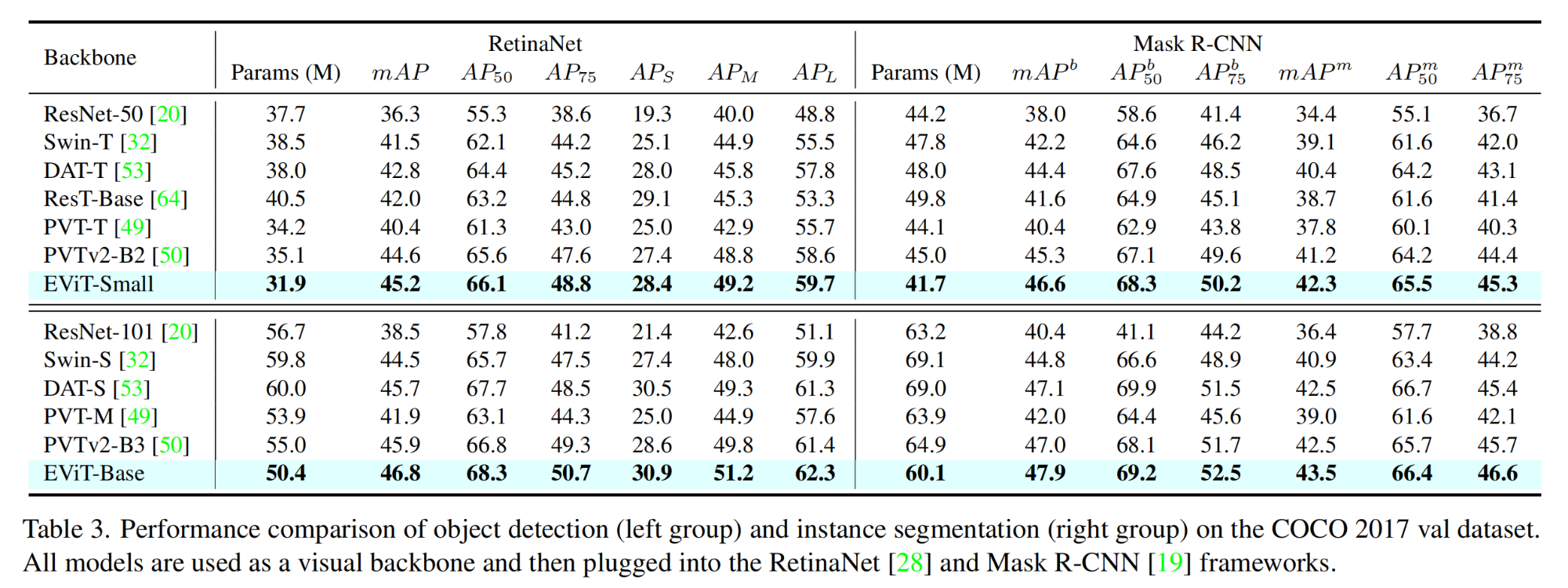
(2)目标检测和实例分割
实验设置:


实验结果:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











