







首先简单介绍一下Google, Google有很多产品,Google搜索引擎,Gmail,安卓,AppspotGoogle Maps,Google earth,Google学术,Google翻译,Google+,下一步Google what??这些为我们的生活带来了巨大的变革,可以说在这个世纪,如果你不会用google,你的生活质量也不会怎么高。
先来看看Google的低成本之道。
不使用超级计算机,不使用存储(淘宝的去i,去e,去o之路)
大量使用普通的pc服务器(去掉机箱,外设,硬盘),提供有冗余的集群服务
全世界多个数据中心,有些附带发电厂
运营商向Google倒付费
这四个方面决定了google的成本很低,利润自然就高。
然后讲讲任何搜索引擎面临的几个难题,google自然也会遇到。但正是google的解决方案才成就了今天得hadoop。
1.大量的网页怎么存储?
2.搜索算法
3.Page-Rank计算问题
针对以上的问题,google是怎么解决的呢?
1.针对网页存储,Google采用了分布式文件存储和倒排索引, 具体请参考《搜索引擎-倒排索引基础知识》和《倒排索引-搜索引擎的基石》两篇文章,讲的很详细。
分布式文件存储也就是后来Haoop的核心HDFS。
2.针对网站的搜索算法,Google发明了Page-Rank算法。这个算法就是后来hadoop的另一个核心Map-Redure。具体请参考《PageRank算法》。当然这个算法是google早期论文中阐述的思想,hadoop创始人根据这个思想谢了hadoop的map-reduce。这个算法现在肯定有很多改进。比以前更复杂,也有很多人对此进行优化。中国也有人去研究,比如:《Hadoop-MapReduce下的PageRank 矩阵分块算法》就是中国大学的教授写的优化思想。
从上面可以看出,Google带给我们的关键技术和思想,这些包括:
GFS-->HDFS
Map-Reduce
Bigtable.(这个还没开始研究,后面会研究到)。
然后就有了Hadoop的源起——Lucene
Doug Cutting开创的开源软件,用java书写代码,实现与Google类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎
早期发布在个人网站和SourceForge,2001年年底成为apache软件基金会jakarta的一个子项目
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎
对于大数量的场景,Lucene面对与Google同样的困难。迫使Doug Cutting学习和模仿Google解决这些问题的办法
一个微缩版:Nutch
从lucene到nutch,从nutch到hadoop
2003-2004年,Google公开了部分GFS和Mapreduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和Mapreduce机制,使Nutch性能飙升 。
Yahoo招安Doug Cutting及其项目
Hadoop 于 2005 年秋天作为 Lucene的子项目 Nutch的 一部分正式引入Apache基金会。2006 年 3 月份,Map-Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中
名字来源于Doug Cutting儿子的玩具大象
目前Hadoop达到的高度
实现云计算的事实标准开源软件
包含数十个具有强大生命力的子项目
已经能在数千节点上运行,处理数据量和排序时间不断打破世界纪录
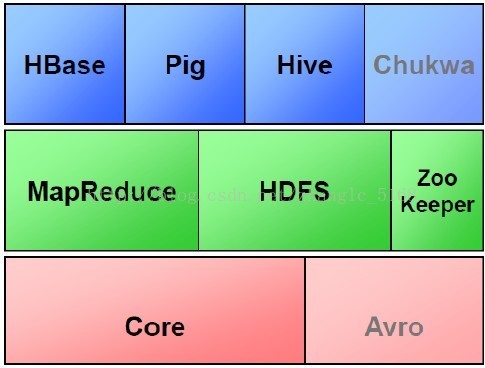
Hadoop子项目家族
Hadoop的架构
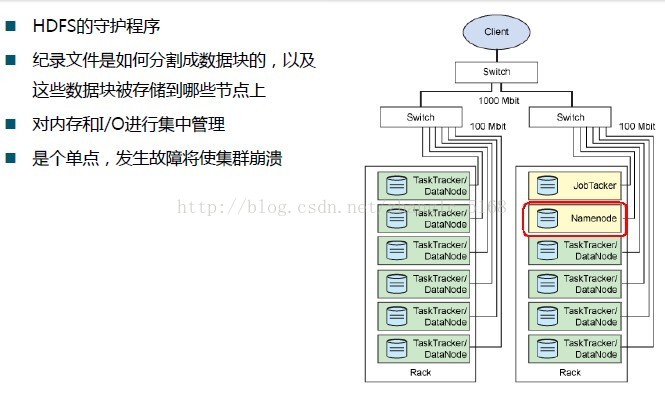
Namenode
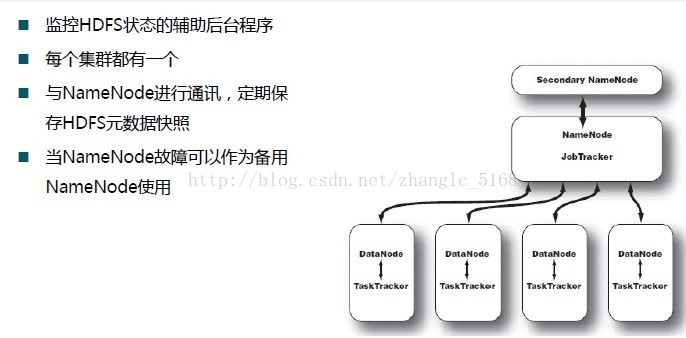
Secondary Namenode
DataNode
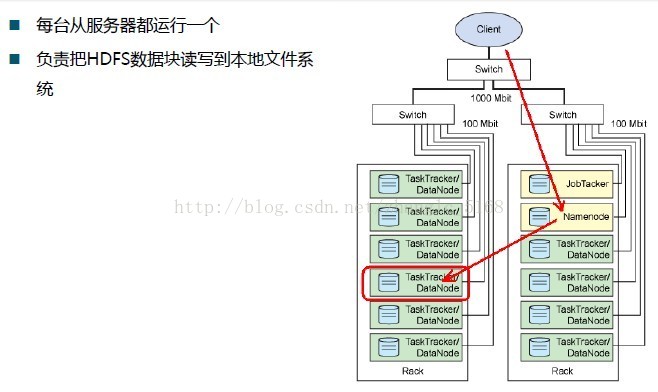
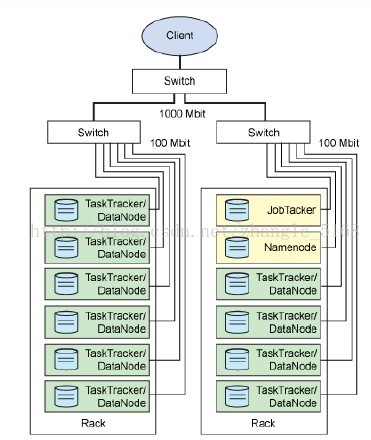
JobTracker
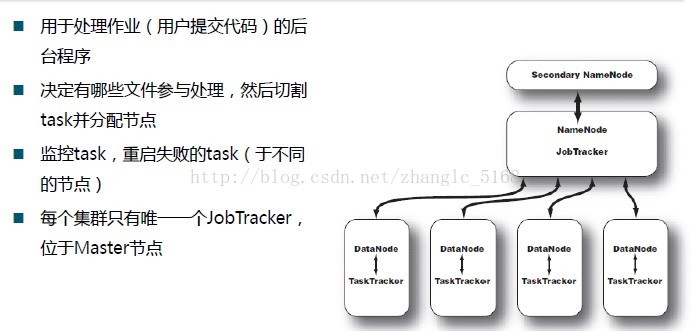
TaskTracker
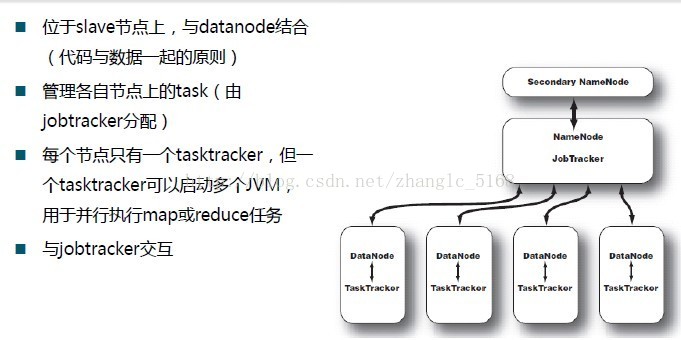
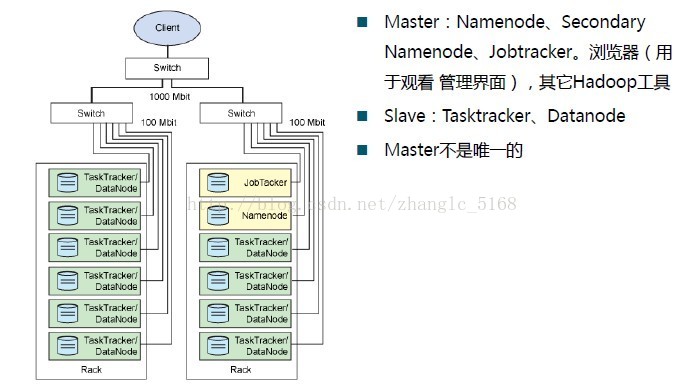
Master与Slave
Why Hadoop?
Why not Hadoop?
JAVA?
难以驾驭?
数据集成困难
Hadoop VS ORACLE
Hadoop确实是一门比较难的技术,因为是用java写的,所以你得精通java才能更好的去实现hadoop。但是我们一定要有决心去学好他。我们一起努力。















 1669
1669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









