








 文章探讨了在并发环境中处理读写数据时如何保证数据一致性的问题,提出了使用双缓冲方案,通过空间换时间的方式,提高读取效率,但对写入时延和特定场景下的性能影响也进行了分析。
文章探讨了在并发环境中处理读写数据时如何保证数据一致性的问题,提出了使用双缓冲方案,通过空间换时间的方式,提高读取效率,但对写入时延和特定场景下的性能影响也进行了分析。
概述
在很多场景需要并发的去读写数据,如下图所示:

考虑到数据写入的顺序性,通常只会有一个线程写入,读数据是可以多线程的。
由于对于Data的一次写入不是原子操作,一个常用通常的方式就是在写的时候加写锁,读的时候加读锁。这在同一个线程每次读数据没有依赖时是可行的,否则还是可能出现问题。如在一次数据处理中,先通过用户“姓名”找到Data中对应的id,再通过id去Data中查找用户其它信息。在这两步之间,写线程可能已经把该用户从Data中删除了,这时就会出现异常。如果希望在一次数据处理中保持数据视图的一致,也就是通常说的“事务性”,需要添加一些措施。
最简单的方式,将上面的读写锁改为普通互斥锁,问题就解决了。但如果写数据的时间开销较大,那么所有的读线程都需要等待数据写完后才能继续工作,无法满足对读响应实时性要求很高的场景(也是笔者目前遇到的情形)。
思路
我是这么去思考的,如果是写数据的时间开销较大,那么是否有办法缩短呢(以至于可以忽略不计的程度)。如果写的数据还可以细分,我们是可以考虑这种方案的。而本文介绍的双buffer方案则是一种空间换时间的算法,它同时存储了两份数据,读的时候去主数据中查询,而写的时候则写入备份数据中,当完成写入后将主/备数据进行交换即可。
数据读取
step1: 获取读锁,确保此时并发的写线程不会修改主数据,同时多线程读数据不会阻塞;
step2: 获取数据,如果需要保证事务性,可以在多次查询中保留读锁不释放;
step3: 释放读锁;
数据写入
step1: 获取当前的数据版本,明确哪份是主数据,哪份是备份数据
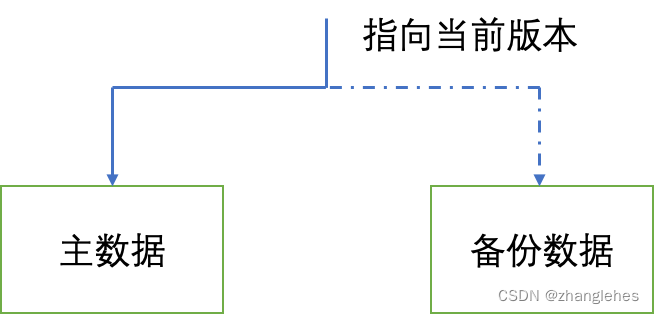
step2: 将备份数据与主数据保持同步,由于此时并未加锁,读线程仍然可以从主数据中查询数据
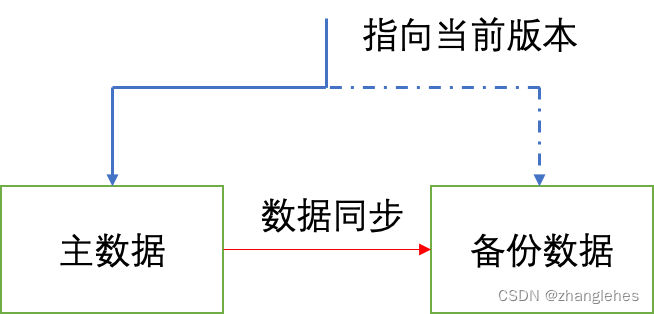
step3: 将数据写入备份数据中,由于此时并未加锁,读线程仍然可以从主数据中查询数据

step4: 加写锁,读数据不再允许,因为数据要改动了
step5: 更新数据版本,这是一个开销很小的操作

step6: 释放写锁
代码实现
#include <shared_mutex>
#include <memory>
#include <iostream>
struct DoubleBuffering {
public:
DoubleBuffering() {
_mtx = std::make_shared<std::shared_mutex>();
}
// following two functions used in query condition
void hold_read_lock() { return _mtx->lock_shared(); }
void release_read_lock() { return _mtx->unlock_shared(); }
// following function could be called with or without _mtx locked
int get_version() { return _version;}
void exchange() {
std::unique_lock<std::shared_mutex> lock(*_mtx);
if(_version == 0) {
std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::system_clock::now().time_since_epoch()).count() << "\tversion update from 0 to 1: " << std::endl;
_version = 1;
}else {
_version = 0;
std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::system_clock::now().time_since_epoch()).count() << "\tversion update from 1 to 0: " << std::endl;
}
}
public:
int _version{0};
std::shared_ptr<std::shared_mutex> _mtx{nullptr};
};验证代码
#include <iostream>
#include <thread>
#include <chrono>
#include <mutex>
using namespace std;
// global variable
int number0 = 0;
int number1 = 0;
DoubleBuffering buffer;
mutex mtx;
void read_func() {
for(int i=0; i!=10; i++) {
buffer.hold_read_lock();
int version = buffer.get_version();
if(version == 0) {
std::unique_lock<std::mutex> lock(mtx);
cout << i << "\t0\t" << std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::system_clock::now().time_since_epoch()).count() << "\t" << number0 << "\t" << number1 << endl;
}else {
std::unique_lock<std::mutex> lock(mtx);
cout << i << "\t1\t" << std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::system_clock::now().time_since_epoch()).count() << "\t" << number0 << "\t" << number1 << endl;
}
// simulate procedure
std::this_thread::sleep_for(std::chrono::milliseconds(100));
buffer.release_read_lock();
}
}
void write_func() {
for(int i=0; i!=10; i++) {
int version = buffer.get_version();
if(version == 1) { // version 1 data might be using now, so we can safely sync and update number0 without lock
// sync
number0 = number1;
// write new data
number0 = number0 + i;
}else {
// sync
number1 = number0;
// write new data
number1 = number1 + i;
}
buffer.exchange();
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
int main() {
// start two read threads and one write thread
thread read1_thread(read_func);
thread read2_thread(read_func);
thread write_thread(write_func);
read1_thread.join();
read2_thread.join();
write_thread.join();
return 0;
}总结
这种双buffer切换的方式主要适合读高频,写低频,且读对数据响应的实时性要求很高的场景。它也会有“弱点”,可能在以下场景下不再合适:
如果对写入的实时性较高,同时读数据一次事务的时间较长,这样写数据会被阻塞住;
如果读/写入的频率都很高,写操作被阻塞的可能性也很大,造成写入的吞吐量降低。















 513
513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









