







 本文深入剖析了Linux内核中的hlist数据结构,包括hlist_head和hlist_node,探讨了pprev指针的设计目的和优势,以及hlist在插入、删除操作中的不同。同时,文章通过pid管理的例子展示了hlist的实际应用。
本文深入剖析了Linux内核中的hlist数据结构,包括hlist_head和hlist_node,探讨了pprev指针的设计目的和优势,以及hlist在插入、删除操作中的不同。同时,文章通过pid管理的例子展示了hlist的实际应用。
在Linux内核中,hlist(哈希链表)使用非常广泛。本文将对其数据结构和核心函数进行分析。
和hlist相关的数据结构有两个(1)hlist_head (2)hlist_node
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};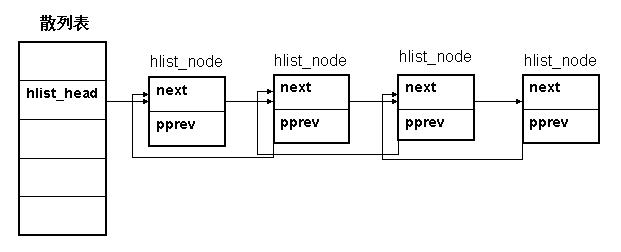
hlist_head结构体只有一个域,即first。 first指针指向该hlist链表的第一个节点。
hlist_node结构体有两个域,next 和pprev。 next指针很容易理解,它指向下个hlist_node结点,倘若该节点是链表的最后一个节点,next指向NULL。
pprev是一个二级指针, 它指向前一个节点的next指针。为什么我们需要这样一个指针呢?它的好处是什么?
在回答这个问题之前,我们先研究另一个问题:为什么散列表的实现需要两个不同的数据结构?
散列表的目的是为了方便快速的查找,所以散列表通常是一个比较大的数组,否则“冲突”的概率会非常大, 这样也就失去了散列表的意义。如何做到既能维护一张大表,又能不使用过多的内存呢?就只能从数据结构上下功夫了。所以对于散列表的每个entry,它的结构体中只存放一个指针,解决了占用空间的问题。现在又出现了另一个问题:数据结构不一致。显然,如果hlist_node采用传统的next,prev指针, 对于第一个节点和后面其他节点的处理会不一致。这样并不优雅,而且效率上也有损失。
hlist_node巧妙地将pprev指向上一个节点的next指针的地址,由于hlist_head和hlist_node指向的下一个节点的指针类型相同,这样就解决了通用性!
下面我们再来看一看hlist_node这样设计之后,插入 删除这些基本操作会有什么不一样。
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4553
4553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









