







先来了解一下典型的多核架构,每个CPU都有自己的Cache,如果一个内存中的变量在多个Cache中都有副本的话,则需要保证变量的Cache一致性:变量的值为最后一次写入的值。Intel多核架构实现Cache一致性是采用的MESI (Modified/Exclusive/Shared/Invalid) 协议。
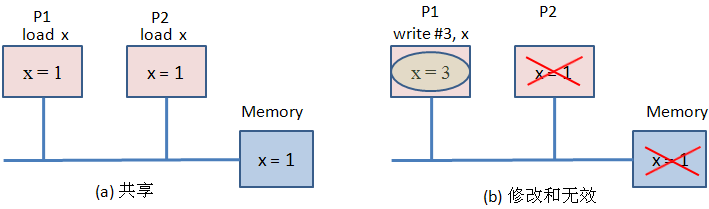
以上图为例,初始P1和P2都从Memory中加载变量x=1,这时每个CPU的Cache的x变量均处于Shared状态;当P1写入x=3时,P2中的变量成为无效状态,P1的为Modified状态。以后在P2读取变量x的值,由于P2的Cache的变量x是无效的,致使Cache命中失败,同时系统会用P1的值来更新P2的Cache和Memory,。
需要注意的是,CPU Cache的结构是按CacheLine为最小单位进行读写的。在Linux可以用命令行sudo cat /proc/cpuinfo看到Cache信息。
本人的机器信息如下:Cache Size: 3072KB, Cache_alignment:64。
下面的例子就能说明false sharing产生的原因:
double sum=0.0, sum_local[NUM_THREADS];
#pragma omp parallel num_threads(NUM_THREADS)
{
int me = omp_get_thread_num();
sum_local[me] = 0.0;
#pragma omp for
for (i = 0; i < N; i++)
sum_local[me] += x[i] * y[i]; //产生false sharing的代码行
#pragma omp atomic
sum += sum_local[me];
}
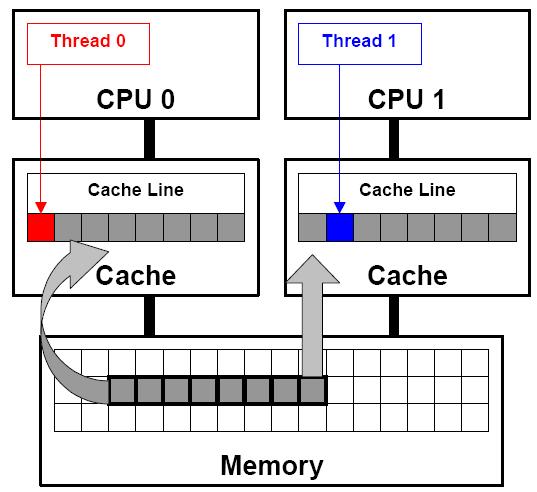
在上图中,CPU0和CPU1的sum_local数组位于同一个Cache Line中。比如某个CPU中的线程更新sum_local[]时,会使其他CPU的Cache的sum_local变成Invalid,这样其他CPU中的线程访问该变量的时候就会进行更新,导致Cache失败,这样会造成额外的内存和Cache之间的同步代价。
在实际的多线程程序中为了避免这种情况,可以采用如下几种方法:
1, 每个线程使用局部线程数据
2, 每个线程访问的全局数据尽可能分隔开至少超过一个Cache Line。
那么,false sharing对程序性能的影响到底有多大呢?下面通过一个程序来进行的粗略性能实验。
下面是一个通过蒙特卡洛法来求取pi的值。
#include<stdio.h>
#include<pthread.h>
#include<stdlib.h>
#include<sys/time.h>
#define MaxThreadNum 32
#define kSamplePoints 100000000
#define kSpace 1
void *compute_pi(void *);
inline double WallTime();
int total_hits, hits[MaxThreadNum][kSpace];
int sample_points_per_thread, num_threads;
int main(void)
{
int i;
double time_start, time_end;
pthread_t p_threads[MaxThreadNum];
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_setscope(&attr, PTHREAD_SCOPE_SYSTEM);
printf("Enter num_threads\n");
scanf("%d", &num_threads);
time_start = WallTime();
total_hits = 0;
sample_points_per_thread = kSamplePoints / num_threads;
for(i=0; i<num_threads; i++)
{
hits[i][0] = i;
pthread_create(&p_threads[i], &attr, compute_pi, (void *)&hits[i]);
}
for(i=0; i<num_threads; i++)
{
pthread_join(p_threads[i], NULL);
total_hits += hits[i][0];
}
double pi = 4.0 * (double)total_hits / kSamplePoints;
time_end = WallTime();
printf("Elasped time: %lf, Pi: %lf\n", time_end - time_start, pi);
return 0;
}
void *compute_pi(void * s)
{
unsigned int seed;
int i;
int *hit_pointer;
double rand_no_x, rand_no_y;
int local_hits;
hit_pointer = (int *)s;
seed = *hit_pointer;
local_hits = 0;
for(i=0; i<sample_points_per_thread; i++)
{
rand_no_x = (double)(rand_r(&seed))/(double)(RAND_MAX);
rand_no_y = (double)(rand_r(&seed))/(double)(RAND_MAX);
if((rand_no_x - 0.5)*(rand_no_x - 0.5) + (rand_no_y - 0.5) * (rand_no_y - 0.5) < 0.25)
(*hit_pointer)++;
// ++local_hits;
seed *= i;
}
//*hit_pointer = local_hits;
pthread_exit(0);
}
inline double WallTime()
{
struct timeval tv;
struct timezone tz;
gettimeofday(&tv, &tz);
double currTime = (double)tv.tv_sec + (double)tv.tv_usec/1000000.0;
return currTime;
}
其中注释的代码是一种采用线程局部数据的方法,记为pi_local,改变kSpace可以改变不同的线程访问的全局数据之间的间隔,其中改变kSpace的值使不同线程访问的数据之间的间隔为4bytes, 32bytes,64bytes,并分别记为pi_4, p1_32, pi_64,测试得到的结果如下:

因为CPU的数量为2,最大的并行效率为2,以pi_local为标准(因为这种情况完全不存在false sharing问题),可以看到pi_4的false sharing最为严重,因为16个线程访问的hits数组均位于一个Cache Line,因此会导致严重的Cache Invalid现象。而pi_64就采用另外的空间间隔策略完全避免了这一问题,效果也还不错。















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









