






在读完论文代码后,对于“DKSVD字典学习的脸部识别”这篇论文中的数学模型理解如下:
这篇论文采用递进的方式从SRC算法到KSVD,Baseline,DKSVD算法依次介绍,以下也按照论文所描述的流程对论文中的算法公式进行逐步介绍。
1.SRC算法
首先论文介绍了SRC算法思路,这个算法的思路是将人脸图像数据以矩阵方式转换为数学公式进行运算,设人脸的字典库中每个人的数据为Ai=[Vi 1 , ...... ,Vi ni],i是字典中每个人各自脸部照片数据组对应的编号。而人脸数据库字典D=[A1,A2,.....,Ak],设需要进行检测的人脸图片数据为y=[b1 1 , ..... ,bi,n],再设立一个相关系数ai=[0 , .... , Ai 1 , ..... , Ai ni , 0 , ...... , 0],i为检测的人的编号。
SRC 算法核心公式是 yi= D*ai(公式1)。i对应检测的第i个人,在得出yi后,计算err(i)= ||y-yi||2,通过err(i)的值来判断第i个人与给出的图像数据y的契合度,最后在检测完字典中所有人的err(i)的值后,以err(i)最低的第i个人为本次匹配结果。即第i个人与给出的图像数据y最像。
SRC算法缺点比较明显,为了保证SRC的准确率字典D必须不断增大它包含的每个人拥有的数据,但这样一来运算耗开销与其他算法比起来较大,而且准确率还有待提高。因此这里引出下面即将介绍的算法
2.KSVD算法
KSVD算法较SRC算法在于KSVD希望通过取更小的字典库D而达到较高的准确率,基于此目的,KSVD算法使用了此公式:
在读完论文代码后,对于“DKSVD字典学习的脸部识别”这篇论文中的数学模型理解如下:
这篇论文采用递进的方式从SRC算法到KSVD,Baseline,DKSVD算法依次介绍,以下也按照论文所描述的流程对论文中的算法公式进行逐步介绍。
1.SRC算法
首先论文介绍了SRC算法思路,这个算法的思路是将人脸图像数据以矩阵方式转换为数学公式进行运算,设人脸的字典库中每个人的数据为Ai=[Vi 1 , ...... ,Vi ni],i是字典中每个人各自脸部照片数据组对应的编号。而人脸数据库字典D=[A1,A2,.....,Ak],设需要进行检测的人脸图片数据为y=[b1 1 , ..... ,bi,n],再设立一个相关系数ai=[0 , .... , Ai 1 , ..... , Ai ni , 0 , ...... , 0],i为检测的人的编号。
SRC 算法核心公式是 yi= D*ai(公式1)。i对应检测的第i个人,在得出yi后,计算err(i)= ||y-yi||2,通过err(i)的值来判断第i个人与给出的图像数据y的契合度,最后在检测完字典中所有人的err(i)的值后,以err(i)最低的第i个人为本次匹配结果。即第i个人与给出的图像数据y最像。
SRC算法缺点比较明显,为了保证SRC的准确率字典D必须不断增大它包含的每个人拥有的数据,但这样一来运算耗开销与其他算法比起来较大,而且准确率还有待提高。因此这里引出下面即将介绍的算法
2.KSVD算法
KSVD算法较SRC算法在于KSVD希望通过取更小的字典库D而达到较高的准确率,基于此目的,KSVD算法使用了此公式: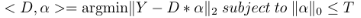
在这个公式中,Y是输入待检测的图像数据的矩阵,T则是矩阵稀疏参数。这个矩阵的含义是:Y减去字典D与系数α相乘结果进行二范数求值且其限制于α的二范数范围内,当二范数||Y-D*α||获得最小值时的D与α的值便为我们的最佳取值。即使用数学式子(2)来代替(1)对D和α的求取确定值,在获得D,α值后接下来的判定步骤与SRC算法后续步骤一样。与SRC相比KSVD在图像压缩和图像去噪方面的效果明显有了提高,但其运用的式子(2)中只考虑了重建误差和稀疏系数,该式子得到的字典D对于分辨性任务还没有达到最优化的结果。
3.Baseline算法
Baseline算法考虑到了字典D中的单张图片在对给出的待分辨数据Y的单张图片相互对比分辨的能力外,还考虑了字典D在对从给出的Y的整体图片组与字典库存储的每个人的图片组进行图片组与图片组之间的比较,即文中提到的“discriminative power”和“representative power”。Baseline算法中运用到的公式列出如下
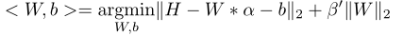
在这个公式中W,b是线性分类器H=W*a+b中的参数。H的每列都是一个向量其中的向量为:hi=[0,0,...,1...,0,0],向量中非零系数的位置与第i个人的图片组数据相对应,在这个式子中的||H-W*α-b||2是从字典中每个人的图片为一组的角度来对给出的数据进行分类的分类器误差系数,||W||2则是修正系数,使用argmin函数计算||H-W*α-b||2+β||W||2值最小时的W,b的值。为了简化起见b可以去掉,在此分别从单张图片对比角度和以字典中每个人的组图数据为对比角度联立(2)(3)数学式子推出如下公式:
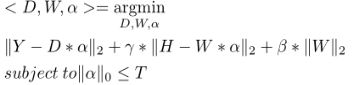 (公式4)
(公式4)
公式(3)中,Y,D,α分别是输入待鉴别数据,字典库,相关系数。而新加入的H,W分别是以字典库中每个人的图片组为参数的组系数和分类器参数(我个人感觉这里的分类器“classifier”是指的是分的是哪个人的图片组的分类的参数的意思,H和W是从字典中每个人的图片组为单位对给出的数据进行分类,而Y,W倾向于从单张图片进行对比鉴别)。Γ和β这两个参数则是反馈和相关系数的标量。
从以上公式介绍可以看出Baseline算法是从KSVD算法中拓展而来的,它比KSVD的数据对比角度多了一种想法。在建立了上述式子后为了能获得更精确的数值,Baseline算法采用迭代逼近求解方法,其步骤如下所示:
(1)通过(公式2)获得D,α初值
(2)通过(公式4)获得D,W,α的进一步精确值
(3)在D,W确定后计算α值
(4)在α,W确定后计算D的值
(5)反复迭代步骤2到4直到D,W,α的值精确到达到给定标准
4.DKSVD算法
DKSVD算法比Baseline算法更优良的地方在于DKSVD算法是对所有参数用一个步骤进行同时求解,不像Baseline算法中联立几个式子一步一步迭代参数逼近精确值,Baseline算法的缺点是容易陷入迭代过程的单个式子的运算结果最优化即所求出的最终值可能并不能同时满足它联立的式子的要求。DKSVD所用到的公式算法如下:
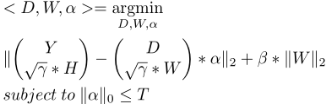 (公式5)
(公式5)
公式5其实与公式4是一样的,公式5中的
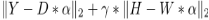
来的式子,两者在对argmin函数求解D,W,α的值这点上两个式子的结果是等价的,整个式子根据原型KSVD算法协议,矩阵
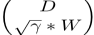
常规列化,因此可以进一步省去修正系数β*||W||2,整个式子最终可以写成:
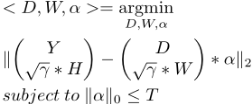 (公式6)
(公式6)
以上是论文中和代码描述的四个算法,在这四个算法的理解过程中,算法中运用到的矩阵运算涉及到矩阵二范式运算和行列变换研究生课程内容
。














 1335
1335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









